...
This report provides a foundational understanding and strategic direction for implementing IAM solutions, tailored to the needs of organizations seeking to enhance their security posture while ensuring compliance with regulatory requirements.
Potential Challenges
Candidate Solutions
Apache Syncope - IAM
https://syncope.apache.org/iam-scenario
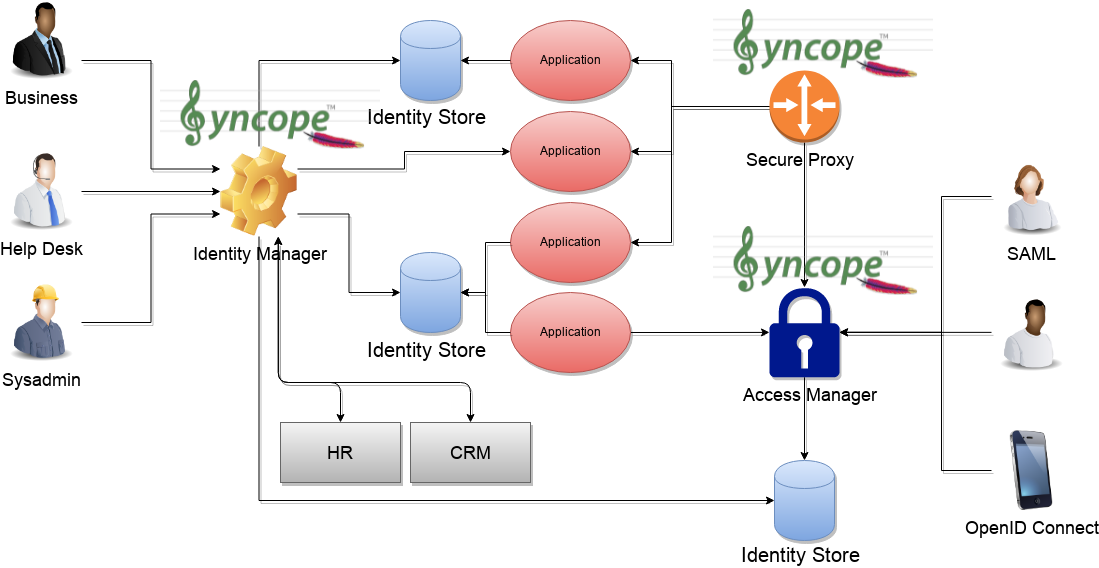
The picture above shows the tecnologies involved in a complete IAM solution:
- Identity Store
(as RDBMS, LDAP, Active Directory, meta- and virtual-directories), the repository for account data - Provisioning Engine
synchronizes account data across identity stores and a broad range of data formats, models, meanings and purposes - Access Manager
access mediator to all applications, focused on application front-end, taking care of authentication (Single Sign-On), authorization (OAuth, XACML) and federation (SAML, OpenID Connect).
Architecture
https://syncope.apache.org/architecture
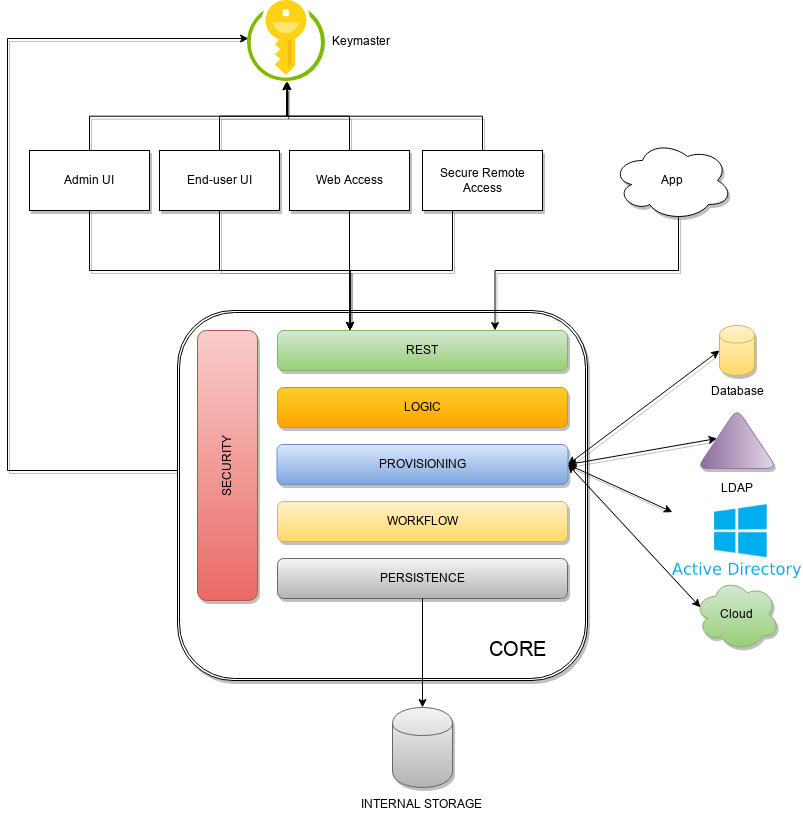
Admin UI is the web-based console for configuring and administering running deployments, with full support for delegated administration.
End-user UI is the web-based application for self-registration, self-service and password reset
CLI is the command-line application for interacting with Apache Syncope from scripts, particularly useful for system administrators.
Core is the central component, providing all services offered by Apache Syncope.
It exposes a fully-compliant JAX-RS 2.0 RESTful interface which enables third-party applications, written in any programming language, to consume IdM services.
Logic implements the overall business logic that can be triggered via REST services, and controls some additional features (notifications, reports and audit over all)
Provisioning is involved with managing the internal (via workflow) and external (via specific connectors) representation of users, groups and any objects.
This component often needs to be tailored to meet the requirements of a specific deployment, as it is the crucial decision point for defining and enforcing the consistency and transformations between internal and external data. The default all-Java implementation can be extended for this purpose. In addition, an Apache Camel-based implementation is also available as an extension, which brings all the power of runtime changes and adaptation.Workflow is one of the pluggable aspects of Apache Syncope: this lets every deployment choose the preferred engine from a provided list - including the one based on Flowable BPM, the reference open source BPMN 2.0 implementation - or define new, custom ones.
Persistence manages all data (users, groups, attributes, resources, …) at a high level using a standard JPA 2.0 approach. The data is persisted to an underlying database, referred to as Internal Storage . Consistency is ensured via the comprehensive transaction management provided by the Spring Framework.
Globally, this offers the ability to easily scale up to a million entities and at the same time allows great portability with no code changes: MySQL, MariaDB, PostgreSQL, Oracle and MS SQL Server are fully supported deployment options.Security defines a fine-grained set of entitlements which can be granted to administrators, thus enabling the implementation of delegated administration scenarios
Third-party applications are provided full access to IdM services by leveraging the REST interface, either via the Java SyncopeClient library (the basis of Admin UI, End-user UI and CLI) or plain HTTP calls.
ConnId
The Provisioning layer relies on ConnId; ConnId is designed to separate the implementation of an application from the dependencies of the system that the application is attempting to connect to.
ConnId is the continuation of The Identity Connectors Framework (Sun ICF), a project that used to be part of market leader Sun IdM and has since been released by Sun Microsystems as an Open Source project. This makes the connectors layer particularly reliable because most connectors have already been implemented in the framework and widely tested.
The new ConnId project, featuring contributors from several companies, provides all that is required nowadays for a modern Open Source project, including an Apache Maven driven build, artifacts and mailing lists. Additional connectors – such as for SOAP, CSV, PowerShell and Active Directory – are also provided.
Syncope Concepts
https://cwiki.apache.org/confluence/display/SYNCOPE/Concepts
A little insight to Syncope internals.
Resources can be synchronized with external repositories
Resources are used both for synchronization and for propagation (i.e. inbound and outbound changes); the two different use cases can be described like this, using the terms of Syncope:
- users (and roles, starting from release 1.1.0) stored in an external resource can be synchronized to Syncope using a connector instance
- users (and roles, starting from release 1.1.0) stored in Syncope can be propagated to external resources using connector instances.
Syncope manual
http://syncope.apache.org/docs/reference-guide.html#introduction
Downloads
https://syncope.apache.org/downloads
https://cwiki.apache.org/confluence/display/SYNCOPE/Roadmap
WSO2 IAM
ZUUL IAM
ZULL Wiki
https://github.com/Netflix/zuul/wiki
Zuul 2.x
Open-Sourcing Zuul article
https://medium.com/netflix-techblog/open-sourcing-zuul-2-82ea476cb2b3
We are excited to announce the open sourcing of Zuul 2, Netflix’s cloud gateway. We use Zuul 2 at Netflix as the front door for all requests coming into Netflix’s cloud infrastructure. Zuul 2 significantly improves the architecture and features that allow our gateway to handle, route, and protect Netflix’s cloud systems, and helps provide our 125 million members the best experience possible. The Cloud Gateway team at Netflix runs and operates more than 80 clusters of Zuul 2, sending traffic to about 100 (and growing) backend service clusters which amounts to more than 1 million requests per second. Nearly all of this traffic is from customer devices and browsers that enable the discovery and playback experience you are likely familiar with.
This post will overview Zuul 2, provide details on some of the interesting features we are releasing today, and discuss some of the other projects that we’re building with Zuul 2.
How Zuul 2 Works
For context, here’s a high-level diagram of Zuul 2’s architecture:
The Netty handlers on the front and back of the filters are mainly responsible for handling the network protocol, web server, connection management and proxying work. With those inner workings abstracted away, the filters do all of the heavy lifting. The inbound filters run before proxying the request and can be used for authentication, routing, or decorating the request. The endpoint filters can either be used to return a static response or proxy the request to the backend service (or origin as we call it). The outbound filters run after a response has been returned and can be used for things like gzipping, metrics, or adding/removing custom headers.
Zuul’s functionality depends almost entirely on the logic that you add in each filter. That means you can deploy it in multiple contexts and have it solve different problems based on the configurations and filters it is running.
We use Zuul at the entrypoint of all external traffic into Netflix’s cloud services and we’ve started using it for routing internal traffic, as well. We deploy the same core but with a substantially reduced amount of functionality (i.e. fewer filters). This allows us to leverage load balancing, self service routing, and resiliency features for internal traffic.
Open Source
The Zuul code that’s running today is the most stable and resilient version of Zuul yet. The various phases of evolving and refactoring the codebase have paid dividends and we couldn’t be happier to share it with you.
Today we are releasing many core features. Here are the ones we’re most excited about:
Server Protocols
- HTTP/2 — full server support for inbound HTTP/2 connections
- Mutual TLS — allow for running Zuul in more secure scenarios
Resiliency Features
- Adaptive Retries — the core retry logic that we use at Netflix to increase our resiliency and availability
- Origin Concurrency Protection — configurable concurrency limits to protect your origins from getting overloaded and protect other origins behind Zuul from each other
Operational Features
- Request Passport — track all the lifecycle events for each request, which is invaluable for debugging async requests
- Status Categories — an enumeration of possible success and failure states for requests that are more granular than HTTP status codes
- Request Attempts — track proxy attempts and status of each, particularly useful for debugging retries and routing
We are also working on some features that will be coming soon, including:
- Websocket/SSE — support for side-channel push notifications
- Throttling and rate-limiting — protection from malicious client connections and requests, helping defend against volumetric attacks
- Brownout filters — for disabling certain CPU-intensive features when Zuul is overloaded
- Configurable routing — file-based routing configuration, instead of having to create routing filters in Zuul
We would love to hear from you and see all the new and interesting applications of Zuul. For instructions on getting started, please visit our wiki page.
Okta - Cloud IAM SAAS
https://seekingalpha.com/article/4355864-okta-chrome-of-identity-management
okta-200626-IAM-king-seekingalpha.com-Okta The Chrome Of Identity Management.pdf
Step-by-step guide for Example
| Info |
|---|
sample code block
| Code Block | ||||||||
|---|---|---|---|---|---|---|---|---|
| ||||||||
Recommended Next Steps
Related articles
| Page Properties | ||
|---|---|---|
| ||
|