Key Points
- Fabric has a good architecture for transaction write performance with: endorse > order > commit process cycle
- Fabric read queries don't need to hit the blockchain in most cases, retrieving data from the "world state" database ( CouchDb or LevelDb )
- Current IBM benchmarks on Fabric v1.4 on large clusters show up to 3K tps ( 3,000 transactions per second )
- Many more optimization patterns from other domains can be applied to raise that by an order of magnitude
- Christian Gorenflo and his team have done a POC showing 20K tps that could be added to Fabric in 2019
- Review TAPE as an option to Caliper - lightweight test on a Fabric network - simple setup
- Fabric v3 has: Smart BFT, parallel ordering among other improvements - targets Kubernetes, gateway API
References
| Reference_description_with_linked_URLs________________________________________ | Notes______________________________________________________________ |
|---|---|
Fast-Fabric POC whitepaper | |
Fast-Fabric slide deck | |
https://github.com/IBM/hlf-internals https://github.com/IBM/hlf-internals/blob/master/docs/index.md | Fabric v1.4x architecture internals Christian Vecchiola |
| https://www.meetup.com/es-ES/Hyperledger-Madrid/events/270078655/ | Fabric performance best practices meetup notes |
| https://image.samsungsds.com/us/en/insights/res/__icsFiles/afieldfile/2019/02/ 16/2019.02.15_Blockchain_AcceleratingThroughputinPermissionedBlockchain Networks.pdf?elqTrackId=8f12b155e7b849998e39adbe583b9a66&elqaid=507&elqat=2 | Samsung Accelerator add in for Fabric that may speed transaction throughput up to 10x ( expect 2x ) |
| Performance Use Cases | |
dltledgers automates Air Asia commodity freight transport on Fabric – tested at 2,000 TPS | |
Empirical Performance Analysis of Hyperledger LTS for Small and Medium Enterprises ilnk Enterprisesfabric-performance-v1.2-mdpi.com-Empirical Performance Analysis of Hyperledger LTS for Small and Medium Enterprises.pdf pdf | Fabric LTS 1.2 performance for medium size companies *** |
| https://pdfs.semanticscholar.org/9e51/e5721d0287d5b6e1a2296b7830857f884d7b.pdf | 2018 benchmarking of Fabric on LTS v1.2 Kafka |
| Performance strategies | |
| https://www.consortia.io/blog/scale-your-blockchain-dlt-based-supply-chain/ | |
Performance articles, resources | |
| https://learn.bybit.com/blockchain/fastest-cryptocurrencies-high-tps/ | 2023 comparison on DLT TPS, finalization estimates Polygon (MATIC) is a blockchain that seeks to scale the Ethereum network by supporting multiple scaling solutions, including Layer 2 and sidechain solutions. It boasts a high throughput of 7,000 TPS and a finality time of 2–3 seconds Fabric v2x
Fabric v3x
|
| https://diablobench.github.io/ | Project Diablo compares blockchain performance Diablo is a benchmark suite to evaluate blockchain systems on the same ground. |
Key Concepts
Blockchain Performance Concepts
https://fantom.foundation/blog/tps-or-ttf-understanding-blockchain-speed/
TPS - Transactions Per Second
For blockchain protocols, TPS is calculated by dividing the average number of transactions per block by the block time in seconds:
TPS = No. txn. per block ÷ Block time in seconds
Here, the number of transactions per block can be estimated by:
No. txn. per Block = Block size in bytes ÷ average txn. size in bytes
Examining the above, one might ask about what counts as a transaction. Different projects have rationales for defining what qualifies as a transaction, and the answer may vary by protocol. Some projects even count internal messages in their systems as transactions.
One might also note that TPS deals with averages. In real-life, some transactions, like simple balance transfers, take far less time to process than EVM-based smart contract transactions, which take measurably longer.
The overall lack of standardization already indicates the problems with the expression as a gauge of speed.
TTF - Transaction Time to Finality
TPS does not account for the total duration during which transactions are processed and then finalized in a decentralized network. When a transaction is submitted to the network, validators arrive at consensus that a transaction is legitimate. But the transaction cannot be fully confirmed until there is a guarantee that the transaction is immutable and final.
Most blockchain systems offer probabilistic transaction finality — transactions are not immediately final but become so eventually after a certain number of additional blocks have been appended to the chain.
The idea is that as blocks continue to be approved and added, the probability increases that prior transactions are valid and irreversible. On Bitcoin, finality generally requires 6 confirmations, with 20-25 confirmations or additional blocks required on Ethereum.
Though TPS is a measure of speed, it is not correlated to finality. A project may boast impressive TPS based on a reasonable definition of transactions, but finality may take longer to be established.
Fabric Blockchain Performance Scaling Strategies
https://www.consortia.io/blog/scale-your-blockchain-dlt-based-supply-chain/
fabric-performance-2021-consortia-Scale Your Blockchain DLT Based Supply Chain.pdf
- buffer bc writes async
- minimize write size
- transaction aggregation
block multiple transactions and hashes into single transactions using external index to find the block.transaction id to get the hash for proof- create external index to individual transactions as async process ( not good for real-time confirmations )
- leverage off-chain and world state databases for transaction updates and reads vs blockchain reads
- push transaction data to encrypted, compressed blobs with NUK key sets, hash the blob & key sets, write hash and (optional) key sets to a block
- use ZK rollups on off-chain transactions for data privacy, minimize data on-chain with rollup hashes, NUKs in hashed blocks with indexes of transaction keys to blocks for fast reads
- sharding for parallel processing
- horizontal scale
- minimize validator needs for transaction consensus
- use ISSMR models to transmit on blockchain network vs simple leader to all propagation
- vertical scale with more powerful nodes
- minimize nodes needed
- use logical members layer vs physical nodes to add orgs, accounts
- upsize cluster
- create logical acid transaction with confirmation prior to write completion - optimistic write w auto retry if failed - separates commit vs finalization
- use off-chain data to answer most queries
- use centralized network where the use case fits
- use logical shards for the blockchain where it fits
- use caching where it helps
Fabric Blockchain Solution Engineering Concepts
For the enterprise DLT side we have flexibility on:
1. What is in a data blob, how it's encrypted and compressed for a use case
2. How we ID transactions uniquely on-chain and off-chain
3. How we build useful indexes to transactions for retrieval
4 How we hash data or hash a ZK proof of the data
5. What the validation policy is by contract
6. What time fence we want to keep transaction data before archiving on-chain and off-chain
7. Who, when and how we access archive data
8. How we map transactions and their hashes to blocks
9.How we handle rollups
10. How we use world state queries vs ledger queries
11. How we provide off-chain data access to organizations
12. How we share ledgers, contracts and ledger data
13. How we validate trusts in the transaction life cycle on access and on write
14. How we secure keys and signing processes
15. How we manage commit vs. finality on transactions
16. Which elements of a transaction life cycle are completed, events signaled and when the results are available to who
17. When, why and how we tokenize assets and integrate real assets
18. How and why we centralize or distribute data using on-chain and off-chain protocols
19. How and where to enforce security compliance rules for strong security and good performance
20. How we progressively optimize performance based on actual run-time experience
21. How we secure and recover wallets, accounts and assets
22. How we interoperate across chains
Lots of flexibility on the enterprise side in designing blockchain solutions
Fabric Internals - v1.4 - IBM au
https://github.com/IBM/hlf-internals/blob/master/docs/index.md
This documentation is organised into four main sections:
- Overview: this section provides an overview of the architecture and the key design principles adopted by Hyperledger Fabric to implement the execution and management of smart contracts. It discusses the rationale, benefits, and advantage of the approach and it introduces the the key concepts of shim and chaincode stub.
- Interaction Protocol: this section dives into the details of the chaincode-peer interaction protocol and discusses the various phases of the protocol, from the connection establishment to the execution of transactions. It also provides an overview of the messages exchanged and their meaning.
- Shim Architecture: this section dives into the implementation of the fabric chaincode shim, which is the process that hosts the smart contract and interfaces it with the Fabric peer. The section discusses the architecture, design, its key components and the protocol used to interact with the peer. If you want to know how
GetState,PutState,GetStateByRangeand other methods work look in here. - Peer Architecture: this section discusses the internal architecture of the peer, its breakdown into subsystems and components. It details how these are involved and participate in the manageemnt of the life-cycle of the chaincode and the execution of transactions. If you want to know what happens when a client submits a transaction proposal, look here.
- Support for New Languages: this section provides an overview of the key components that need to be modified and implemented to enable Hyperledger Fabric with the ability of managing chaincode in another language than Java, Node, or Go. If you want to get to the action and see what takes, jump here.
What You Need To Know
This documentation assumes that the you have a general understanding of Hyperledger Fabric, its key components, and the transaction execution flow, as a user of this platform. If you need a refresh on these concepts, have a look at the Key Concepts section on the Hyperledger Fabric documentation.
2018 benchmarking of Fabric on LTS v1.4 Kafka
https://pdfs.semanticscholar.org/9e51/e5721d0287d5b6e1a2296b7830857f884d7b.pdf
While the test numbers are not valid today on Fabric v2.5 or later, the concepts are generally still valid
using AWS VCPUs achieved write performance of up to 2250 TPS
fabric-performance-test-results-2018-v1.4-LTS.pdf file
fabric-performance-test-results-2018-v1.4-LTS.pdf link
Fast-Fabric performance engineering – 01/30/2019 review
https://arxiv.org/pdf/1901.00910.pdf
What did the Fast-Fabric performance POC do?
Hyperledger Fabric has always been one of the stronger blockchain performance frameworks based on benchmarks. I spoke with Christian Gorenflo. Christian and his team have gone through a significant re-engineering exercise applying many database design architectures to improve Fabric transaction performance. The results of his tests are, as I expected, very significant. Based on the POC, IBM can begin working the design changes into future Fabric releases in 2019.
What was the net improvement?
Earlier benchmarks were showing test results in the 3,000 transactions per second ( 3K tps ) for a typical 4K message size on a large Fabric cluster setup ( 15 nodes, 1 TB memory ). Adding smart caches, smart marshaling and parallel processing throughout the Fabric transaction cycle ( endorse, order, commit ), Christian achieved almost 20K tps – an improvement of over 600%.
Are there other improvements Fabric can make?
Going forward, a sharding strategy that fits might boost performance another order of magnitude higher. There are still other optimizations from other domains that could be tried to improve Fabric performance beyond that as well.
What does it mean for our solution?
When Fabric moves these features into a later production release, we should be able to scale transaction performance as needed to meet client demands. Our expected performance for a given use case will depend on our design goals and engineering. Are we looking for ACID transactions? Are we looking for logging transactions?
To start, we won’t be building out that large a cluster given our transaction volumes will be much smaller initially. Assume we has a much larger 16K message size and a much smaller cluster, we should not have a problem exceeding 500 transactions per second. How strong is that? Compare to the max performance benchmarks below today.
Comparative performance now for other blockchain frameworks
On average Bitcoin processes about 7 transactions per second, which makes it pretty slow compared to Ethereum (15) and Ripple (the fastest major cryptocurrency, at 1,500 per second). Visa does 24,000 transactions per second. You can how strong Fabric could be with these improvements in a production release and sharding added.
Key Fast Fabric optimization opportunities
We hence design and implement several architectural optimizations based on common system design techniques that together improve the end-to-end transaction throughput by a factor of almost 7, from 3,000 to 20,000 transactions per second, while decreasing block latency. Our specific contributions are as follows:
1) Separating metadata from data: the consensus layer in Fabric receives whole transactions as input, but only the transaction IDs are required to decide the transaction order. We redesign Fabric’s transaction ordering service to work with only the transaction IDs, resulting in greatly increased throughput.
2) Parallelism and caching: some aspects of transaction validation can be parallelized while others can benefit from caching transaction data. We redesign Fabric’s transaction validation service by aggressively caching un-marshaled blocks at the committers and by parallelizing as many validation steps as possible, including endorsement policy validation and syntactic verification.
3) Exploiting the memory hierarchy for fast data access on the critical path: Fabric’s key-value store that maintains world state can be replaced with light-weight in-memory data structures whose lack of durability guarantees can be compensated by the blockchain itself. We redesign Fabric’s data management layer around a light-weight hash table that provides faster access to the data on the critical transaction-validation path, deferring storage of immutable blocks to a write-optimized storage cluster.
4) Resource separation: the peer roles of committer and endorser vie for resources. We introduce an architecture that moves these roles to separate hardware
Samsung Accelerator transaction speed booster for Fabric - some limitations
Accelerator is a software component developed by Samsung SDS that is designed to improve the performance of a blockchain network in terms of transaction throughput. Inspired by multilevel queue scheduling [1], Accelerator enables the blockchain network to deal with a large volume of transaction requests from applications. Samsung SDS and IBM have engaged to validate the applicability of Accelerator to Hyperledger Fabric networks and define a roadmap for integration of Accelerator into the Hyperledger Fabric open source project. The team defined a test harness around Hyperledger Caliper and Fabric running on a bare metal system in the IBM Cloud.
It batches transactions to orderers and peers for endorsement
Accelerator exists as a stand-alone server for server-side acceleration. It is inserted between a blockchain application and Hyperledger Fabric networks as shown in Figure 2. Accelerator consists of three major components, which are Classifier, Aggregator, and Router, written in the Go programming language and utilizing Hyperledger Fabric Go SDK.
mirBFT consensus tests for better performance
https://github.com/hyperledger-labs/mirbft/tree/research
https://arxiv.org/pdf/1906.05552.pdf
mirBFT broadcast to clients provides these features
- P1 Validity: If a correct node commits r then some client broadcasted r.
- P2 Agreement (Total Order): If two correct nodes commit requests r and r 0 with sequence number sn, then r = r 0 .
- P3 No duplication: If a correct node commits request r with sequence numbers sn and sn0 , then sn = sn0 .
- P4 Totality: If a correct node commits request r, then every correct node eventually commits r.
- P5 Liveness: If a correct client broadcasts request r, then some correct node p eventually commits r.

DAG storage model for better performance
like Hedera Hashgraph
German Telekom Performance Experiences
This is Alfonso de la Rocha from Telefónica. We have been working for some months now in doing a performance evaluation of Fabric infrastructures. We were planning to share our results in this year's Hyperledger Global Summit but we didn't have the chance, so we decided to write a series of articles in my weekly newsletter to share our learnings with the community.
This is the series of articles:
Additionally, in case it is of your interest, we are also having a virtual meetup tomorrow where we will be sharing some of our results, and our friends from DT will talk about their telco Fabric-based solution they are moving into production.
The link of the meetup: https://www.meetup.com/es-ES/Hyperledger-Madrid/events/270078655/
I really hope you find all of this content useful, and any feedback or suggestion you may have is more than welcome.
Fabric v2.5 Performance Benchmark with Caliper on 2 org test net

Configuration
he following block cutting parameters were used:
- block_cut_time: 2s
- block_size: 500
- preferred_max_bytes: 2Mb
In order to be able to push enough workload through without hitting concurrency limits, the gateway concurrency limit was set to 20,000.
In summary the following benchmarks are presented here:
- Blind write of a single key with 100 Byte Asset Size (a create asset benchmark)
- Blind write of a single key with 1000 Byte Asset Size (a create asset benchmark)
- Read/Write of a single key with 100 Byte Asset Size (an update asset benchmark)
- Read/Write of a single key with 1000 Byte Asset Size (an update asset benchmark)
Blind Write of a Single Key 1000 Byte Asset Size
Caliper test configuration:
- workers: 200
- fixed-tps, tps: 3000

Read Write of a Single Key 1000 Byte Asset Size
The above was repeated using a 1000 byte asset size.
Caliper test configuration:
- workers: 200
- fixed-tps, tps: 1530

LevelDB Performance Benchmarks
http://www.lmdb.tech/bench/microbench/benchmark.html
This section gives the baseline performance of all the databases. Following sections show how performance changes as various parameters are varied. For the baseline:
- Each database is allowed 4 MB of cache memory.
- Databases are opened in asynchronous write mode. (LevelDB's sync option, TreeDB's OAUTOSYNC option, and SQLite3's synchronous options are all turned off). I.e., every write is pushed to the operating system, but the benchmark does not wait for the write to reach the disk.
- Keys are 16 bytes each.
- Value are 100 bytes each (with enough redundancy so that a simple compressor shrinks them to 50% of their original size).
- Sequential reads/writes traverse the key space in increasing order.
- Random reads/writes traverse the key space in random order.
A. Sequential Reads
| LevelDB | 4,030,000 ops/sec | |
| Kyoto TreeDB | 1,010,000 ops/sec | |
| SQLite3 | 383,000 ops/sec |
B. Random Reads
| LevelDB | 129,000 ops/sec | |
| Kyoto TreeDB | 151,000 ops/sec | |
| SQLite3 | 134,000 ops/sec |
C. Sequential Writes
| LevelDB | 779,000 ops/sec | |
| Kyoto TreeDB | 342,000 ops/sec | |
| SQLite3 | 48,600 ops/sec |
D. Random Writes
| LevelDB | 164,000 ops/sec | |
| Kyoto TreeDB | 88,500 ops/sec | |
| SQLite3 | 9,860 ops/sec |
LevelDB outperforms both SQLite3 and TreeDB in sequential and random write operations and sequential read operations. Kyoto Cabinet has the fastest random read operations.
see extX file systems notes
https://opensource.com/article/18/4/ext4-filesystem
FoundationDB - fast key-value DB performance - 2023
https://apple.github.io/foundationdb/performance.html
Benchmark per core for 90% read and 10% write - normal work loads
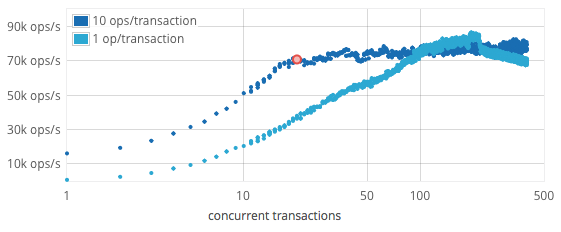
Its asynchronous design allows it to handle very high concurrency, and for a typical workload with 90% reads and 10% writes, maximum throughput is reached at about 200 concurrent operations. This number of operations was achieved with 20 concurrent transactions per FoundationDB process each running 10 operations with 16 byte keys and values between 8 and 100 bytes.
The concurrency graph uses a single FoundationDB server process on a single core (E3-1240).
Potential Value Opportunities
Potential Challenges
Fabric updating transactions just written to ledger MVCC
Problem
So, what the best way to update a value bases on its previous value? I need an example that does not impact throughput or latency that much. I do not want to go through key management and I do not want to trust client for making delta values for me or any interference from the client. I am seeking a solution at the chaincode level. So any suggestion or examples please?
eg find a recent record with count = 9, update the transaction to count = 10, query to validate
Not a best practice model for a blockchain ledger as a use case
Ideally, the SAME transactions is not continuously updated ( like a control record count )
Answer
If you send a steady flow of updates for the same key, you will always have some transactions in flight (endorsement or ordering phase) while earlier transactions are committing on peers. Since the later transaction's reads are now outdated, the chaincode execution is considered invalid, and those transactions will get invalidated as MVCC conflict.
Many performance tests will randomly select a key, e.g. key1 through key10000. The first time seen by chaincode it will read the key and since not found in current state, will create the key. The next time seen by chaincode it will read the key and since found, will update the key. Most will pass validation. A few will collide (same key chosen within 1-2 seconds) and get invalidated, and assuming client is listening to the block validation events, client can resubmit if you want a test with 100% pass rate.
There are a number of variables you can play with, for example a quicker block cut rate (BatchTimeout) or smaller blocks (MaxMessageCount/AbsoluteMaxBytes/PreferredMaxBytes) will result in fewer conflicts, but if too small may impact overall throughput, since block processing overhead wouldn't be amortized over as many transactions.
Dave Enyeart
Fabric Java Chaincode performance problem
I've been able to reproduce the problem.
I updated FabCar to initialize 140 cars instead of 10. Query all cars takes the following times:
Go chaincode - 70ms
Javascript chaincode - 90ms
Java chaincode - 3500ms.
I added debug to the Java chaincode... the 3 second delay happens AFTER the chaincode container receives a batch of 100 records, but BEFORE control is passed to the user chaincode. Therefore the problem appears to be somewhere in the Java chaincode shim. I've updated the bug to Fabric Chaincode Java project. The experts in that project could take a look.
The new Jira number is: https://jira.hyperledger.org/browse/FABCJ-285
Dave Enyeart
Hyperledger Fabric Performance Characterization and Optimization Using GoLevelDB Benchmark

Candidate Solutions
Hyperledger Caliper for Fabric performance
https://github.com/hyperledger/caliper-benchmarks
https://github.com/hyperledger/caliper
https://www.hyperledger.org/learn/publications/blockchain-performance-metrics
HL_performance_Whitepaper_Metrics_PDF_V1.01.pdf
https://hyperledger.github.io/caliper/
https://hyperledger.github.io/caliper/v0.4.2/getting-started/
https://hyperledger.github.io/caliper/v0.4.2/installing-caliper/
https://hyperledger.github.io/caliper/v0.4.2/fabric-tutorial/
Step-by-step guide for Example
sample code block