Key Points
- Data pipelines connect, transform data sources to data targets in batches or event streams
- The interactive set of data stream services that compares to batch Hadoop services
- supports many data sources including messaging services ( Kafka, MQ etc )
References
Key Concepts
Spark
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.

Learning Apache Spark is easy whether you come from a Java, Scala, Python, R, or SQL background:
df = spark.read.json("logs.json")
df.where("age > 21") .
select("name.first").show()Read JSON files with automatic schema inference
Spark Quick Start
This tutorial provides a quick introduction to using Spark. We will first introduce the API through Spark’s interactive shell (in Python or Scala), then show how to write applications in Java, Scala, and Python.
To follow along with this guide, first, download a packaged release of Spark from the Spark website. Since we won’t be using HDFS, you can download a package for any version of Hadoop.
Spark SQL Guide
Spark in Action book
https://drive.google.com/open?id=1ZqKpzFcCgy3r4lyeuN2t2gINpegHIte9

Spark RDD Concepts
https://www.xenonstack.com/blog/rdd-in-spark/
Compare RDD, Data Set, Data Frame
RDD APIs
An RDD or Resilient Distributed Dataset is the actual fundamental data Structure of Apache Spark. These are immutable (Read-only) collections of objects of varying types, which computes on the different nodes of a given cluster. These provide the functionality to perform in-memory computations on large clusters in a fault-tolerant manner. Every DataSet in the Spark RDD is well partitioned across many servers so that they can be efficiently computed on different nodes of the cluster.
DataSet APIs
In Apache Spark, the Dataset is a data structure in Spark SQL which is strongly typed, Object-oriented and is a map to a relational schema. It represents a structured query with encoders and is an extension to the Data-frame API. These are both serializable and Query-able, thus persisting in nature. It provides a single interface for both Scala and Java languages. It also reduces the burden of libraries.
DataFrame APIs
We can say that Data-Frames are Dataset organized into named columns. These are very similar to the table in a relational database. The ideology is to allow processing of a large amount of Structured Data. Data-Frame contains rows with a schema where the schema is the illustration of the structure of data. It provides memory management and optimized execution plans.
Spark RDD process flow
- Spark creates a graph when you enter code in the sparking console.
- When an action is called on Spark RDD, Spark submits graph to DAG scheduler.
- Operators are divided into stages of Tasks in DAG scheduler.
- The stages are passed on to the Task scheduler, which launches task through Cluster Manager.
RDD limitations
Memory overflow
RDD degrades when there is not enough memory too available to store it in-memory or on disk. Here, the partitions that overflow from RAM may be stored on disk and will provide the same level of performance. We need to increase the RAM and disk size to overcome this problem.
Combine Spark with Airflow, Koalas to get pandas
Bryan Cafferky on Spark



Arrow creates optimized memory stores for data in Spark from any language client

RDD or Resilient Distributed Dataset
An RDD or Resilient Distributed Dataset is the actual fundamental data Structure of Apache Spark. These are immutable (Read-only) collections of objects of varying types, which computes on the different nodes of a given cluster
https://databricks.com/glossary/what-is-rdd
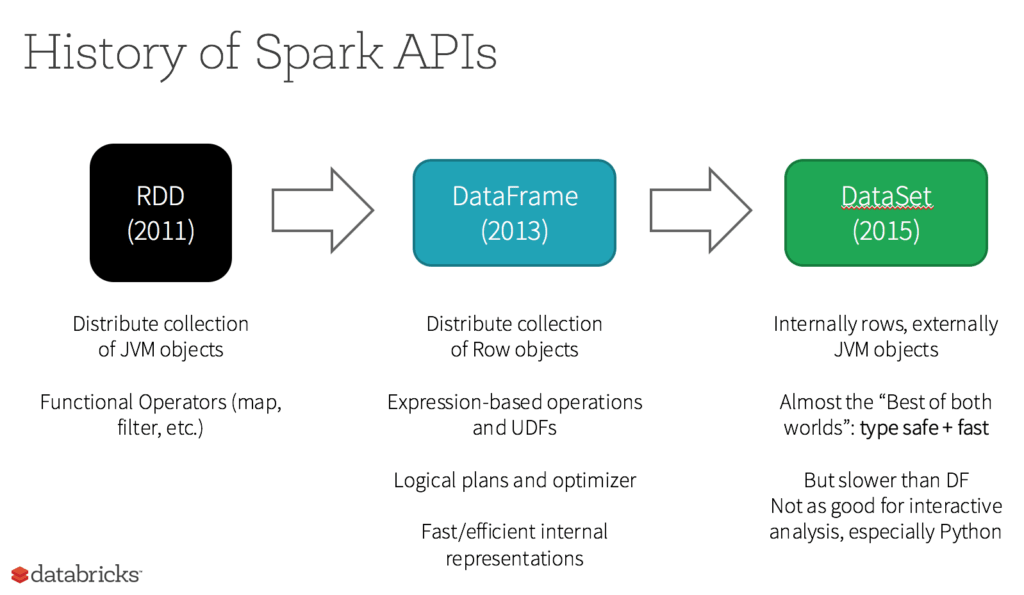 RDD was the primary user-facing API in Spark since its inception. At the core, an RDD is an immutable distributed collection of elements of your data, partitioned across nodes in your cluster that can be operated in parallel with a low-level API that offers transformations and actions.
RDD was the primary user-facing API in Spark since its inception. At the core, an RDD is an immutable distributed collection of elements of your data, partitioned across nodes in your cluster that can be operated in parallel with a low-level API that offers transformations and actions.
5 Reasons on When to use RDDs
- You want low-level transformation and actions and control on your dataset;
- Your data is unstructured, such as media streams or streams of text;
- You want to manipulate your data with functional programming constructs than domain specific expressions;
- You don’t care about imposing a schema, such as columnar format while processing or accessing data attributes by name or column; and
- You can forgo some optimization and performance benefits available with DataFrames and Datasets for structured and semi-structured data.
Create data frame from a table with Spark SQL

Plot it

Each language has a separate shell ( R, PySpark etc )

Spark SQL with a join

Potential Value Opportunities
Potential Challenges
Candidate Solutions
Step-by-step guide for Example
sample code block