m Camel Data Svcs
- jim mason
- jimm1
Key Points
- Apache Camel data integration services
- Large library of components and connectors
- For reading, generally outputs Java object maps
- Need to see how write, update options work
- Currently favors XML over JSON objects
References
| Reference_description_with_linked_URLs____________________ | Notes__________________________________________________________ |
|---|---|
| https://camel.apache.org/ | |
| https://camel.apache.org/manual/latest/index.html | |
| https://camel.apache.org/manual/latest/faq/what-is-camel.html | |
| https://camel.apache.org/manual/latest/book-getting-started.html | |
| Apache Camel as data connection service for CouchDB | |
| https://cwiki.apache.org/confluence/display/CAMEL/Components | Camel components repository |
| https://cwiki.apache.org/confluence/display/CAMEL/Index | Apache camel data service overview |
| https://stackoverflow.com/questions/8845186/what-exactly-is-apache-camel | What is Apache Camel? |
Key Concepts
Apache Camel is an open source framework for message-oriented middleware with a rule-based routing and mediation engine that provides a Java object-based implementation of the Enterprise Integration Patterns using an application programming interface to configure routing and mediation rules. Wikipedia
Apache camel distributed data service overview
https://cwiki.apache.org/confluence/display/CAMEL/Index
Apache Camel ™ is a versatile open-source integration framework based on known Enterprise Integration Patterns.
Camel empowers you to define routing and mediation rules in a variety of domain-specific languages, including a Java-based Fluent API, Spring or Blueprint XML Configuration files, and a Scala DSL. This means you get smart completion of routing rules in your IDE, whether in a Java, Scala or XML editor.
Apache Camel uses URIs to work directly with any kind of Transport or messaging model such as HTTP, ActiveMQ, JMS, JBI, SCA, MINA or CXF, as well as pluggable Components and Data Format options. Apache Camel is a small library with minimal dependencies for easy embedding in any Java application. Apache Camel lets you work with the same API regardless which kind of Transport is used - so learn the API once and you can interact with all the Components provided out-of-box.
Apache Camel provides support for Bean Binding and seamless integration with popular frameworks such as CDI, Spring, Blueprint and Guice. Camel also has extensive support for unit testing your routes.
The following projects can leverage Apache Camel as a routing and mediation engine:
- Apache ServiceMix - a popular distributed open source ESB and JBI container
- Apache ActiveMQ - a mature, widely used open source message broker
- Apache CXF - a smart web services suite (JAX-WS and JAX-RS)
- Apache Karaf - a small OSGi based runtime in which applications can be deployed
- Apache MINA - a high-performance NIO-driven networking framework
Camel as a distributed RPC framework
https://camel.apache.org/manual/latest/book-getting-started.html
Camel provides out-of-the-box support for endpoints implemented with many different communication technologies. Here are some examples of the Camel-supported endpoint technologies.
A JMS queue.
A web service.
A file. A file may sound like an unlikely type of endpoint, until you realize that in some systems one application might write information to a file and, later, another application might read that file.
An FTP server.
An email address. A client can send a message to an email address, and a server can read an incoming message from a mail server.
A POJO (plain old Java object).
In a Camel-based application, you create (Camel wrappers around) some endpoints and connect these endpoints with routes, which I will discuss later in Section 4.8 ("Routes, RouteBuilders and Java DSL"). Camel defines a Java interface called Endpoint. Each Camel-supported endpoint has a class that implements this Endpoint interface. As I discussed in Section 3.3 ("Online Javadoc documentation"), Camel provides a separate Javadoc hierarchy for each communications technology supported by Camel. Because of this, you will find documentation on, say, the JmsEndpoint class in the JMS Javadoc hierarchy, while documentation for, say, the FtpEndpoint class is in the FTP Javadoc hierarchy.
Camel Message Bus Concepts with Servicemix ESB integration options
http://people.apache.org/~dkulp/camel/message-bus.html
Camel supports the Message Bus from the EIP patterns. You could view Camel as a Message Bus itself as it allows producers and consumers to be decoupled.
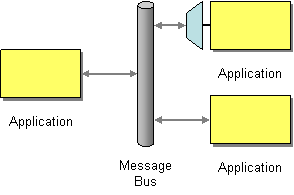
Folks often assume that a Message Bus is a JMS though so you may wish to refer to the JMS component for traditional MOM support.
Also worthy of note is the XMPP component for supporting messaging over XMPP (Jabber)
Of course there are also ESB products such as Apache ServiceMix which serve as full fledged message busses.
You can interact with Apache ServiceMix from Camel in many ways, but in particular you can use the NMR or JBI component to access the ServiceMix message bus directly.
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out
Camel Context
https://camel.apache.org/manual/latest/book-getting-started.html
A CamelContext object represents the Camel runtime system. You typically have one CamelContext object in an application. A typical application executes the following steps:
Create a
CamelContextobject.Add endpoints – and possibly components, which are discussed in Section 4.5 ("Components") – to the
CamelContextobject.Add routes to the
CamelContextobject to connect the endpoints.Invoke the
start()operation on theCamelContextobject. This starts Camel-internal threads that are used to process the sending, receiving and processing of messages in the endpoints.Eventually invoke the
stop()operation on theCamelContextobject. Doing this gracefully stops all the endpoints and Camel-internal threads.
Note that the CamelContext.start() operation does not block indefinitely. Rather, it starts threads internal to each Component and Endpoint and then start() returns. Conversely, CamelContext.stop() waits for all the threads internal to each Endpoint and Component to terminate and then stop() returns.
If you neglect to call CamelContext.start() in your application then messages will not be processed because internal threads will not have been created.
If you neglect to call CamelContext.stop() before terminating your application then the application may terminate in an inconsistent state. If you neglect to call CamelContext.stop() in a JUnit test then the test may fail due to messages not having had a chance to be fully processed.
Camel Template
Camel 3x notes
https://issues.apache.org/jira/secure/ReleaseNote.jspa?version=12345567&projectId=12311211
Potential Value Opportunities
Potential Challenges
Candidate Solutions
Compare Couchbase to CouchDB
License
Both Couchbase Server and Apache CouchDB are fully open source projects released under the Apache 2.0 licence.
Couchbase Server | Apache CouchDB | |
Data models | Document, Key-Value | Document |
Storage | Append-only B-Tree | Append-only B-Tree |
Consistency | Strong | Eventual |
Topology | Distributed | Replicated |
Replication | Master-Master | Master-Master |
Automatic failover | Yes | No |
Integrated cache | Yes | No |
Memcached compatible | Yes | No |
Locking | Optimistic & Pessimistic | Optimistic with MVCC |
MapReduce (Views) | Yes | Yes |
Query language | Yes, N1QL (SQL for JSON) | No |
Secondary indexes | Yes | Yes |
Notifications | Yes, Database Change Protocol | Yes, Changes Feeds |
Couchbase Query
Couchbase Server provides three ways to query the data it stores:
- N1QL, a SQL-like query language for JSON.
- Views, including multi-dimensional/geospatial; much like CouchDB views.
- Key-value look-ups.
If you know the key of the document you need, you can perform a simple GET request using that key. There’s no need to create any additional indexes.

For more involved query, you can use N1QL. N1QL provides a familiar SQL-like way to query JSON data. For example, to find a user profile based on that user’s email address, we use the following N1QL query:
SELECT * FROM `users` WHERE email=”matthew@couchbase.com” AND WHERE type=”userProfile”;N1QL allows you to query JSON with the same flexibility you’d expect from a relational database, including JOINs across documents. To learn more about SQL-like querying with N1QL, try using the sample visualizer or try it out in the Query Language Tutorial.
CouchDB uses views as the only query option
As a pure document store, Apache CouchDB allows you to retrieve data based on the contents of documents. It does this through a system of views. You can also pull out a full document using its key.
You can think of CouchDB’s views as indexes that you generate by writing JavaScript MapReduce queries. For example, if you want to retrieve a user profile based on that user’s email address you could:
- Create a view that provides all the documents that contain an email address and have a type of ‘userProfile’.
- Query that view for the email address of the user whose profile you want to retrieve.
Couchbase has SDKs for development and a JDBC driver
Couchbase Server has several SDKs that are developed and supported by Couchbase Inc. These provide idiomatic access to the full range of Couchbase Server features, including N1QL, views and key-value access. Official SDKs are available for:
Couchbase uses mem-cache to store key-value tables
Couchbase Server has a built-in managed cache. For each request you make, Couchbase Server will transparently check the cache for the document you need. If the document isn’t in the cache, it’ll load it from disk and then serve it to you.
All writes go into the cache and you can tune at which point in the request it is written to disk or replicated to other servers.
For your working set, most key-value requests are sub-millisecond.
Step-by-step guide for Example
sample code block