m Apache Data Services
- jim mason
- jimm1
Key Points
- Data pipelines connect, transform data sources to data targets in batches or event streams
ToDo > Data Services Source Reviews
eblock reqmts model - groovy dsl expando w events ?
eblock test app
eblock composer
esb pub / sub w events
alf airflow
alf nifi batch
alf camel
alf nifi batch
alf kafka
alf spark
alf beam
alf airflow
istio.io
https://istio.io/docs/concepts/what-is-istio/
http://apache.org/index.html#projects-list
https://www.linuxfoundation.org/projects/directory/
https://www.npmjs.com/
https://skywalking.apache.org/blog/2019-01-25-mesh-loadtest.html
https://www.nginx.com/blog/what-is-a-service-mesh/
References
Key Concepts
Key Apache Projects Supporting Distributed Data Services
https://www.linkedin.com/pulse/popular-apache-projects-burak-%C3%B6zt%C3%BCrk/
Apache-Data-Services-Projects-overview-2023-linkedin.com-Popular Apache Projects.pdf. link
Apache-Data-Services-Projects-overview-2023-linkedin.com-Popular Apache Projects.pdf file
Hadoop
Airflow
a batch processing data pipeline similar to Ooze
Kestra
https://www.infoq.com/news/2022/03/kestra-orchestration-platform/
Kestra, a new open-source orchestration and scheduling platform, helps developers to build, run, schedule, and monitor complex pipelines.
uses yaml not python configs
https://github.com/kestra-io/kestra
Nifi
Apache NiFi supports powerful and scalable directed graphs of data routing, transformation, and system mediation logic.
- Web-based user interface
- Seamless experience between design, control, feedback, and monitoring
- Highly configurable
- Loss tolerant vs guaranteed delivery
- Low latency vs high throughput
- Dynamic prioritization
- Flow can be modified at runtime
- Back pressure
- Data Provenance
- Track dataflow from beginning to end
- Designed for extension
- Build your own processors and more
- Enables rapid development and effective testing
- Secure
- SSL, SSH, HTTPS, encrypted content, etc...
- Multi-tenant authorization and internal authorization/policy management
| FBP Term | NiFi Term | Description |
| Information Packet | FlowFile | Each object moving through the system. |
| Black Box | FlowFile Processor | Performs the work, doing some combination of data routing, transformation, or mediation between systems. |
| Bounded Buffer | Connection | The linkage between processors, acting as queues and allowing various processes to interact at differing rates. |
| Scheduler | Flow Controller | Maintains the knowledge of how processes are connected, and manages the threads and allocations thereof which all processes use. |
| Subnet | Process Group | A set of processes and their connections, which can receive and send data via ports. A process group allows creation of entirely new component simply by composition of its components |
Flow File like HTTP data


Nifi integration points
| NiFi Term | Description |
| Flow File Processor | Push/Pull behavior. Custom UI |
| Reporting Task | Used to push data from NiFi to some external service (metrics, provenance, etc.) |
| Controller Service | Used to enable reusable components / shared services throughout the flow |
| REST API | Allows clients to connect to pull information, change behavior, etc |

Nifi can deliver data provenance



Flows passed in registry ( vs xml files )

Ignite - in memory db
Ignite™ is a memory-centric distributed database, caching, and processing platform for
transactional, analytical, and streaming workloads delivering in-memory speeds at petabyte scale
Achieve horizontal scalability, strong consistency, and high availability with Ignite™ distributed SQL
Accelerate existing Relational and NoSQL databases with Ignite™ in-memory data grid and caching capabilities
Store and process distributed data in memory and on disk
Distributed memory-centric SQL database with support for joins
Read, write, transact with fastest key-value data grid and cache
Enforce full ACID compliance across distributed data sets
Avoid data noise by sending computations to cluster nodes
Train and deploy distributed machine learning models

Kafka
Compare Kafka Alternatives
https://www.macrometa.com/event-stream-processing/kafka-alternatives
Kafka Alternatives
Apache Kafka is an open source software messaging bus that uses stream processing. Because it’s a distributed platform known for its scalability, resilience, and performance, Kafka has become very popular with large enterprises. In fact, 80% of the Fortune 500 use Kafka.
However, there’s no such thing as a one-size-fits-all solution. What’s best for Uber or PayPal may not be ideal for your application. Fortunately, there are several alternative messaging platforms available.
Having a thorough understanding of the technology landscape is essential, whether you are developing applications or considering ready-to-go industry solutions provided by Macrometa.
Knowing which platform is right for you requires understanding the pros and cons of each. To help you make the right choice, we’ll take an in-depth look at Apache Kafka and four popular Kafka alternatives.
Before taking a detailed look at Kafka and those four alternatives, let’s start with a high-level overview of features.
Kafka compared to alternatives
| Kafka | Google pub/sub | RabbitMQ | Pulsar | Macrometa | |
|---|---|---|---|---|---|
| Ease of Setup | Hard | Easy | Medium | Hard | Easy |
| Storage | Seven days (Scalable to disk size) | Seven days (auto-scaling) | The message is lost once acknowledged | Tiered storage scalable to disk size | Three days (support retention and TTL) |
| Throughput & scalability | Best | Better | Good | Best | Best |
| Message re-read / replay | Yes | No | No | Yes | Yes |
| Type | Event streaming | Publish /Subscribe | Message Broker | Messaging and event streaming | Messaging and event streaming |
| Built-in multitenancy | No | No | No | Yes | Yes |
| Geo-replication | No | No | No | Yes | Yes |
| Languages supported | 17 | 8 | 22 | 6 | Supports all Kafka & Pulsar clients |
Kafka faster than Pulsar on some latency benchmarks
Canonical Charmed Kafka reference architecture guide 3 release 1.pdf link
Canonical Charmed Kafka reference architecture guide 3 release 1 .pdf file
Apache Pulsar
Cloud-Native, Distributed Messaging and Streaming
Apache® Pulsar™ is an open-source, distributed messaging and streaming platform built for the cloud.
Apache Pulsar is an all-in-one messaging and streaming platform. Messages can be consumed and acknowledged individually or consumed as streams with less than 10ms of latency. Its layered architecture allows rapid scaling across hundreds of nodes, without data reshuffling.
Its features include multi-tenancy with resource separation and access control, geo-replication across regions, tiered storage and support for six official client languages. It supports up to one million unique topics and is designed to simplify your application architecture.
Pulsar is a Top 10 Apache Software Foundation project and has a vibrant and passionate community and user base spanning small companies and large enterprises.

Producer & Consumer
A Pulsar client contains a consumer and a producer. A producer writes messages on a topic. A consumer reads messages from a topic and acknowledges specific messages or all up to a specific message.
Apache Zookeeper
Pulsar and BookKeeper use Apache ZooKeeper to save metadata coordinated between nodes, such as a list of ledgers per topic, segments per ledger, and mapping of topic bundles to a broker. It’s a cluster of highly available and replicated servers (usually 3).
Pulsar Brokers
Topics (i.e., partitions) are divided among Pulsar brokers. A broker receives messages for a topic and appends them to the topic’s active virtual file (a.k.a ledger), hosted on the Bookkeeper cluster. Brokers read messages from the cache (mostly) or BookKeeper and dispatch them to the consumers. Brokers also receive message acknowledgments and persist them to the BookKeeper cluster as well. Brokers are stateless (don't use/need a disk).
Apache Bookkeeper
Apache BookKeeper is a cluster of nodes called bookies. Each virtual file (a.k.a ledger) is divided into consecutive segments, and each segment is kept on 3 bookies by default (replicated by the client - i.e., the broker). Operators can add bookies rapidly since no data reshuffling (moving) between them is required. They immediately share the incoming write load.
Key Pulsar Features
- horizontal scalability
- low latency messaging and event streaming
- geo location replication
- multi-tenancy
- ALB - automated load balancing
- Multi-language support for Java, Go, Python, C++, Node.js, and C#.
- Officially maintained connectors with popular 3rd parties: MySQL, Elasticsearch, Cassandra, and more. Allows streaming data in (source) or out (sink).
- Serverless Functions - Write, deploy functions natively using Pulsar Functions. Process messages without deploying fully-fledged applications. Kubernetes runtime is bundled.
- Topics - up to 1 million
Pulsar Quickstart
https://pulsar.apache.org/docs/3.0.x/
Why Pulsar vs Kafka?
Why Pulsar vs Kafka? Streamnative article for Pulsar
Pulsar vs Kafka Benchmark
Pulsar vs Kafka Benchmark article from streamnative
Large configurations on HIgh bandwidth network
The testbed for the OpenMessaging Benchmark is set up as follows:
- 3 Broker VMs of type i3en.6xlarge, with 24-cores, 192GB of memory, 25Gbps guaranteed networking, and two NVMe SSD devices that support up to 1GB/s write throughput on each disk.
- 4 Client (producers and consumers) VMs of type m5n.8xlarge, with 32-cores and with 25Gbps of guaranteed networking throughput and 128GB of memory to ensure the bottleneck would not be on the client-side.
Results

Apache Event Mesh
EventMesh is a new generation serverless event middleware for building distributed event-driven applications.

https://github.com/apache/eventmesh
Apache EventMesh has a vast amount of features to help users achieve their goals. Let us share with you some of the key features EventMesh has to offer:
- Built around the CloudEvents specification.
- Rapidty extendsible interconnector layer connectors such as the source or sink of Saas, CloudService, and Database etc.
- Rapidty extendsible storage layer such as Apache RocketMQ, Apache Kafka, Apache Pulsar, RabbitMQ, Redis, Pravega, and RDMS(in progress) using JDBC.
- Rapidty extendsible controller such as Consul, Nacos, ETCD and Zookeeper.
- Guaranteed at-least-once delivery.
- Deliver events between multiple EventMesh deployments.
- Event schema management by catalog service.
- Powerful event orchestration by Serverless workflow engine.
- Powerful event filtering and transformation.
- Rapid, seamless scalability.
- Easy Function develop and framework integration.
Roadmap
Please go to the roadmap to get the release history and new features of Apache EventMesh.
- EventMesh-site: Apache official website resources for EventMesh.
- EventMesh-workflow: Serverless workflow runtime for event Orchestration on EventMesh.
- EventMesh-dashboard: Operation and maintenance console of EventMesh.
- EventMesh-catalog: Catalog service for event schema management using AsyncAPI.
- EventMesh-go: A go implementation for EventMesh runtime.
Event Mesh Intro
https://eventmesh.apache.org/docs/introduction/
key features EventMesh has to offer:
- Built around the CloudEvents specification.
- Rapidly extensible language sdk around gRPC protocols.
- Rapidly extensible middleware by connectors such as Apache RocketMQ, Apache Kafka, Apache Pulsar, RabbitMQ, Redis, Pravega, and RDMS(in progress) using JDBC.
- Rapidly extensible controller such as Consul, Nacos, ETCD and Zookeeper.
- Guaranteed at-least-once delivery.
- Deliver events between multiple EventMesh deployments.
- Event schema management by catalog service.
- Powerful event orchestration by Serverless workflow engine.
- Powerful event filtering and transformation.
- Rapid, seamless scalability.
- Easy Function develop and framework integration.
Event Mesh Overview
https://www.infoq.com/news/2023/04/eventmesh-serverless/
Spark
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.

Learning Apache Spark is easy whether you come from a Java, Scala, Python, R, or SQL background:
df = spark.read.json("logs.json")
df.where("age > 21") .
select("name.first").show()Read JSON files with automatic schema inference
Spark Quick Start
This tutorial provides a quick introduction to using Spark. We will first introduce the API through Spark’s interactive shell (in Python or Scala), then show how to write applications in Java, Scala, and Python.
To follow along with this guide, first, download a packaged release of Spark from the Spark website. Since we won’t be using HDFS, you can download a package for any version of Hadoop.
Spark SQL Guide
Spark in Action book
https://drive.google.com/open?id=1ZqKpzFcCgy3r4lyeuN2t2gINpegHIte9

Iceberg - Data Lakehouse
Open Table format for analytic datasets — same as my temp tables at PTP ( session and global )
https://iceberg.apache.org/community/
- Spark in Lakehouse Architecture: Learn how Apache Iceberg integrates with Apache Spark, emphasizing its role in ETL and reducing the cost of data transformation and storage compared to a traditional data warehouse.
- Simple and Reliable Ingestion with Upsolver: Examine how Upsolver simplifies the ingestion of operational data into Iceberg tables, highlighting its no-code and ZeroETL approaches for efficient data movement.
- Impacts of Data Management on Query Performance: Explore the impacts of small files, fast and continuous updates/deletes, and manifest file churn on query performance. Compare how data is managed and optimized between Spark and Upsolver, including how each handles schema evolution and transactional concurrency.
- Best Practices for Implementing Lakehouse Architectures: Discuss best practices for deploying and managing a lakehouse architecture using Spark and Upsolver, with insights into optimizing storage, improving query speeds, and ensuring high quality, reliable data.
Camel
- Apache Camel data integration services
- Large library of components and connectors
- For reading, generally outputs Java object maps
- Need to see how write, update options work
- Currently favors XML over JSON objects
https://camel.apache.org/manual/latest/index.html
Arrow
Apache Arrow is a cross-language development platform for in-memory data. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware. It also provides computational libraries and zero-copy streaming messaging and interprocess communication. Languages currently supported include C, C++, C#, Go, Java, JavaScript, MATLAB, Python, R, Ruby, and Rust.
Arrow Data Access Model for Columnar Data

Advantages of common Arrow data layer

Arrow Project Docs
https://arrow.apache.org/docs/
Apache Arrow is a development platform for in-memory analytics. It contains a set of technologies that enable big data systems to process and move data fast. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware.
The project is developing a multi-language collection of libraries for solving systems problems related to in-memory analytical data processing. This includes such topics as:
Zero-copy shared memory and RPC-based data movement
Reading and writing file formats (like CSV, Apache ORC, and Apache Parquet)
In-memory analytics and query processing
Arrow Columnar Format
Storm
Beam
Cassandra
Apache Cassandra is a free and open-source high-performance database that is provably fault-tolerant both on commodity hardware or cloud infrastructure. It can even handle failed node replacements without shutting down the systems and it can also replicate data automatically across multiple nodes. Moreover, Cassandra is a NoSQL database in which all the nods are peers without any master-slave architecture. This makes it extremely scalable and fault-tolerant and you can add new machines without any interruptions to already running applications. You can also choose between synchronous and asynchronous replication for each update.
Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make Apache Cassandra the perfect platform for mission-critical data. Cassandra's support for replicating across multiple datacenters is best-in-class.
Cassandra provides full Hadoop integration, including with Pig and Hive.
Cassandra database is the right choice when you need scalability and high availability without compromising performance.
Cassandra storage of NoSQL data
- Cassandra clusters have multiple nodes running in local data centers or public clouds.
- Data is typically stored redundantly across nodes according to a configurable replication factor so that the database continues to operate even when nodes are down or unreachable.
- Tables in Cassandra are much like RDBMS tables.
- Physical records in the table are spread across the cluster at a location determined by a partition key. The partition key is hashed to a 64-bit token that identifies the Cassandra node where data and replicas are stored.iv T
- he Cassandra cluster is conceptually represented as a ring, as shown in Figure 1, where each cluster node is responsible for storing tokens in a range.
- Queries that look up records based on the partition key are extremely fast because Cassandra can immediately determine the host holding required data using the partitioning function.
- Since clusters can potentially have hundreds or even thousands of nodes, Cassandra can handle many simultaneous queries because queries and data are distributed across cluster nodes.
Cassandra Language Client Drivers
Cassandra has many client drivers particularly for Java
many are open source
There is also a JDBC wrapper for the Datastax Java driver
https://github.com/ing-bank/cassandra-jdbc-wrapper
Data modeling in performance
https://drive.google.com/open?id=1JJnMPTVAgwZF2PKqTQVWTii16oLPIeAi
define requirements model as an object model
create application object flow ( outputs > inputs > processes )
model queries to support flow
define Chebotko diagrams ( ERD for phyiscal, logical models )
set the primary key correctly
Primary key logic
Tables in Cassandra have a primary key. The primary key is made up of a partition key, followed by one or more optional clustering columns that control how rows are laid out in a Cassandra partition. Getting the primary key right for each table is one of the most crucial aspects of designing a good data model.In the latest_videos table, yyyymmdd is the partition key, and it is followed by two clustering columns, added_date and videoid, ordered in a fashion that supports retrieving the latest videos.

performance
Cassandra consistently outperforms popular NoSQL alternatives in benchmarks and real applications, primarily because of fundamental architectural choices.
There are no single points of failure. There are no network bottlenecks. Every node in the cluster is identical.
Choose between synchronous or asynchronous replication for each update. Highly available asynchronous operations are optimized with features like Hinted Handoff and Read Repair.
Donated by Google - open-source and commercial distributions available
https://cassandra.apache.org/doc/latest/getting_started/index.html
https://cassandra.apache.org/doc/latest/architecture/index.html
This section describes the general architecture of Apache Cassandra.
- Overview
- set replication and consistency policies
- Dynamo
- Storage Engine
- Guarantees
Consistency Policy
Decide on a consistency policy to fit the use case
t is common to pick read and write consistency levels that are high enough to overlap, resulting in “strong” consistency. This is typically expressed as W + R > RF, where W is the write consistency level, R is the read consistency level, and RF is the replication factor. For example, if RF = 3, a QUORUM request will require responses from at least two of the three replicas. If QUORUM is used for both writes and reads, at least one of the replicas is guaranteed to participate in both the write and the read request, which in turn guarantees that the latest write will be read. In a multi-datacenter environment, LOCAL_QUORUM can be used to provide a weaker but still useful guarantee: reads are guaranteed to see the latest write from within the same datacenter.
Commit logs
Commitlogs are an append only log of all mutations local to a Cassandra node. Any data written to Cassandra will first be written to a commit log before being written to a memtable. This provides durability in the case of unexpected shutdown. On startup, any mutations in the commit log will be applied to memtables.
All mutations write optimized by storing in commitlog segments, reducing the number of seeks needed to write to disk.
Memtables
Memtables are in-memory structures where Cassandra buffers writes. In general, there is one active memtable per table. Eventually, memtables are flushed onto disk and become immutable SSTables. This can be triggered in several ways:
- The memory usage of the memtables exceeds the configured threshold (see
memtable_cleanup_threshold) - The CommitLog approaches its maximum size, and forces memtable flushes in order to allow commitlog segments to be freed
Memtables may be stored entirely on-heap or partially off-heap, depending on memtable_allocation_type.
SSTables on disk
SSTables are the immutable data files that Cassandra uses for persisting data on disk.
As SSTables are flushed to disk from Memtables or are streamed from other nodes, Cassandra triggers compactions which combine multiple SSTables into one. Once the new SSTable has been written, the old SSTables can be removed.
Each SSTable is comprised of multiple components stored in separate files:
Query SSTable versions
The following example is useful for finding all sstables that do not match the “ib” SSTable version
find /var/lib/cassandra/data/ -type f | grep -v -- -ib- | grep -v "/snapshots"Query Language
https://cassandra.apache.org/doc/latest/cql/index.html
Cassandra Operations
https://cassandra.apache.org/doc/latest/operating/index.html
Troubleshooting Cassandra
https://cassandra.apache.org/doc/latest/troubleshooting/index.html
Contributing to Cassandra Development
https://cassandra.apache.org/doc/latest/development/index.html
HBase
Apache HBase is an open-source distributed Hadoop database that can be used to read and write to big data. HBase has been constructed so that it can manage billions of rows and millions of columns using commodity hardware clusters. This database is based on the Big Table which was a distributed storage system created for structured data. Apache HBase has many different capabilities including scalability, automatic sharding of tables, consistent reading and writing capabilities, support against failure for all the servers, etc.
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
HBase Features
- Linear and modular scalability.
- Strictly consistent reads and writes.
- Automatic and configurable sharding of tables
- Automatic failover support between RegionServers.
- Convenient base classes for backing Hadoop MapReduce jobs with Apache HBase tables.
- Easy to use Java API for client access.
- Block cache and Bloom Filters for real-time queries.
- Query predicate push down via server side Filters
- Thrift gateway and a REST-ful Web service that supports XML, Protobuf, and binary data encoding options
- Extensible jruby-based (JIRB) shell
- Support for exporting metrics via the Hadoop metrics subsystem to files or Ganglia; or via JMX
CarbonData
CarbonData is a fully indexed columnar and Hadoop native data-store for processing heavy analytical workloads and detailed queries on big data with Spark SQL. CarbonData allows faster interactive queries over PetaBytes of data.
Apache CarbonData is a new big data file format for faster interactive query using advanced columnar storage, index, compression and encoding techniques to improve computing efficiency, which helps in speeding up queries by an order of magnitude faster over PetaBytes of data.
https://carbondata.apache.org/language-manual.html
CarbonData has its own parser, in addition to Spark's SQL Parser, to parse and process certain Commands related to CarbonData table handling. You can interact with the SQL interface using the command-line or over JDBC/ODBC.
- Data Types
- Data Definition Statements
- Data Manipulation Statements
- CarbonData as Spark's Datasource
- Configuration Properties
https://carbondata.apache.org/introduction.html
CarbonData use cases
https://carbondata.apache.org/usecases.html
CarbonData is used for but not limited to
Bank
- fraud detection analysis
- risk profile analysis
- As a zip table to update the daily balance of customer
Web/Internet
- Analysis of page or video being accessed,server loads, streaming quality, screen size
Solution to queries on high volume data
Setup a Hadoop + Spark + CarbonData cluster managed by YARN.
Query results
| Parameter | Results |
|---|---|
| Query | < 3 Sec |
| Data Loading Speed | 40 MB/s Per Node |
| Concurrent query performance (20 queries) | < 10 Sec |
CarbonData QuickStart
https://carbondata.apache.org/quick-start-guide.html
load some test data to files using Spark shell
start the network
run queries
carbon.sql("SELECT * FROM test_table").show()
carbon.sql(
s"""
| SELECT city, avg(age), sum(age)
| FROM test_table
| GROUP BY city
""".stripMargin).show()Solr
Elastisearch
Log File Management Systems
Splunk
https://www.educba.com/is-splunk-open-source/
Elastic Stack
https://www.educba.com/splunk-alternatives/
The Elastic Stack (also called as ELK stack) has been a leading open source log management solution. It is a good alternative to Splunk. It comprises of 4 major modules:
- Elasticsearch: Highly scalable search and analytics engine.
- Logstash: Log processing component which conduits incoming logs to ES.
- Kibana: Data visualization tool for the logs captured.
- Beats: Also called data shipped for elastic search.
A regular stack provides all of the tools needed to conduit, process, and view log data using a web-based UI with binary dependancy as java. The elastic stack is an open source tool and stands stable with an active developer community supporting throughout, a wide range of plugins, and extensive formats support.
On the other side, running the Elastic Stack can be quite complex than other tools in the market. It is highly distributed and requires scaled supportive configuration setup to work as a full-fledged solution. It gets along best for geographical data and records high compression of memory storage.
Price model: Premium version of Elastic stack provides access controls statistical notifiers and reporting solutions in addition to the standard functionalities of the free version. However, it is also expensive to implement pricing almost $2,000,000 to run at an enterprise scale which has a duration stretch of about three years.
Zeppelin - Apache data notebook like Jupyter w python, dsl, sql etc
https://zeppelin.apache.org/docs/latest/quickstart/install.html
Other open source alternative data servers with data frames - BIRT !!!
Multi-purpose notebook which supports
20+ language backends
- Data Ingestion
- Data Discovery
- Data Analytics
- Data Visualization & Collaboration
https://zeppelin.apache.org/docs/0.10.0/
Navigating Zeppelin UI
https://zeppelin.apache.org/docs/0.10.0/quickstart/explore_ui.html
Zeppelin quickstart
https://zeppelin.apache.org/docs/latest/quickstart/install.html
on Ubuntu, MAC vms
JDK 1.8
Allows mutliple data resources as connections
create notebooks with paragraphs and data frames
q> can data frame 1 reference data frame 2 as content?
when notebook is run as a service, REST api allows selecting notebooks and actions
when executed, output can be a result set or a visualization
q> no drill through support easily available
Zeppelin Tutorial
https://zeppelin.apache.org/docs/0.9.0-preview1/quickstart/tutorial.html
Potential Value Opportunities
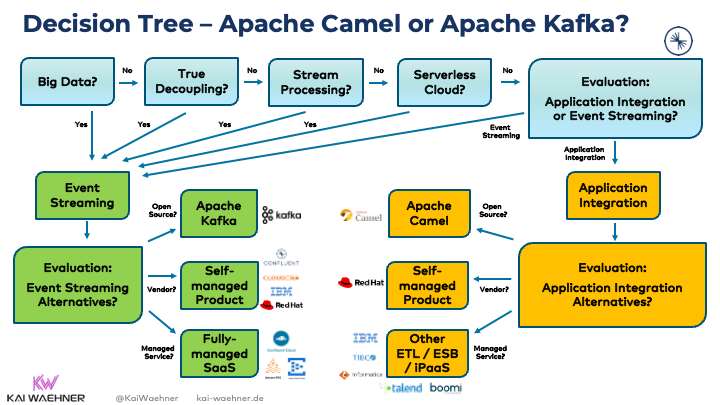
Compare When to use Camel vs Kafka
comparison discusses when to use Kafka or Camel, when to combine them, when not to use them at all. A decision tree shows how you can quickly qualify out one for the other.
Application integration is one of the most challenging problems in computer science – especially if you talk about transactional data sets that require zero data loss, exactly-once semantics, and no downtime. The more components you combine in the end-to-end data flow, the harder it gets to keep your performance and reliability SLAs.
The Lambda architecture was invented to separate real-time workloads from batch workloads. Event Streaming was born. Apache Kafka became the de facto standard for data streaming.
Kappa Architecture replaces Lambda event streaming with a single data stream
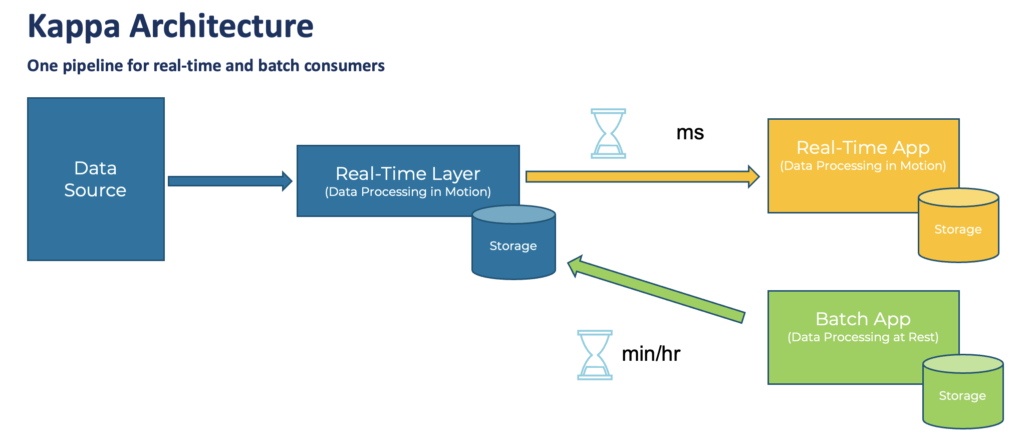
enterprise architects build new infrastructures with the Lambda architecture that includes separate batch and real-time layers.
This blog post explores why a single real-time pipeline, called Kappa architecture, is the better fit.
Apache Kafka. The focus is on event streaming
Confluent Cloud is an Apache Kafka and its ecosystem for application integration and stream processing as a serverless cloud offering.
Features in Apache Camel AND Apache Kafka
Camel and Kafka have many positive and negative characteristics in common. Hence, it is no surprise that people compare the two frameworks:
- Open source under Apache 2.0 license
- Vibrant community and adoption in the industry
- Mature framework with deployments in enterprises across the globe
- Fixing point-to-point spaghetti architectures with a central integration backbone
- Open architecture and extensibility with custom functions and connectors
- Small and big deployments possible, plus single-node deployments for non-mission-critical use cases
- Re-engineered and optimized for cloud-native deployments (container, Kubernetes, cloud)
- Connectivity to any technology, API, communication paradigm, and SaaS
- Transformation of any data types and formats
- Processes transactional and analytical workloads
- Domain-specific language (DSL) for message at a time processing, with similar logic such as aggregation, filtering, conditional processing
- Relative complex frameworks because of their robust feature set, hence not suitable for solving a minor problem
- Not a replacement of a database, data warehouse, or data lake
Beyond the similarities, Kafka and Camel have very different sweet spots built to solve distinct problems.
Camel
Apache Camel is an integration framework. It solves a particular problem: Data integration between different applications, APIs, protocols, and communication paradigms. This concept is often called application integration or enterprise integration. Camel implements the famous Enterprise Integration Patterns (EIP). EIPs are based on messaging principles.
Camel’s strengths
- Event-based backbone based on well-known and adopted EIP concepts
- Connectivity to almost any API
- Integration, processing, and routing of information with an intuitive domain-specific language (DSL) with a focus on integration; providing the ability of composability in a programming context for finer grain control in code for doing conditional logic or transformations/reformatting
- Powerful routing capabilities with many built-in EIPs
- Many deployment options (standalone, web container, application server, Spring, OSGi, Kubernetes via the Camel K sub-project) – okay, I guess some options are not relevant in this decade anymore
- Lightweight alternative to proprietary ETL and ESB tools
Camel’s weaknesses
- Only a “routing machine”, i.e., not built for long-term storage (additional cache or storage needed), for that reason, Camel is not the right choice for a central nervous system like Kafka
- No stream processing (like you know it from Kafka Streams or Apache Flink)
- Limited scalability, not built for massive volumes of data
- No powerful visual coding like you know it from proprietary ETL/ESB/iPaaS tools
- No serverless cloud offering, with that also not competing with other iPaaS offerings
- Red Hat is the only vendor supporting it
- Built to be deployed in a single data center or cloud region, not across hybrid or multi-cloud scenarios
Kafka
Real-time data beats slow data at any scale. The event streaming platform enables processing data in motion. Kafka is the de facto standard for event streaming, including messaging, data integration, stream processing, and storage. Kafka provides all capabilities in one infrastructure at scale. It is reliable and allows to process analytics and transactional workloads.
Kafka’s strengths
- Event-based streaming platform
- A unique combination of pub/sub messaging, data processing, data integration, and storage in a single framework
- Built for massive volumes of data and extreme scale from the beginning, with that a single framework can be used for transactional (low volume) and analytics (high volume) use cases
- True decoupling between producers and consumers because of its storage component makes it the de facto standard for microservice architectures
- Guaranteed ordering of events in the distributed commit log
- Distributed data processing with fault-tolerance and recoverability built-in
- Replayability of events
- The de facto standard for event streaming
- Built with hybrid and multi-cloud data replication in mind (with included tools like MirrorMaker and separate, more advanced, and more straightforward tools like Confluent Cluster Linking)
- Support from many vendors, including Confluent, Cloudera, IBM, Red Hat, Amazon, Microsoft, and many more
- Paradigm shift: Built to process data in motion end-to-end from source to one or more sinks
Kafka’s weaknesses
- Paradigm shift: Enterprises need to learn and understand the added value of event streaming, a new software category that enables new use cases but also requires different design patterns and operations approaches
- No powerful visual coding like you know it from proprietary ETL/ESB/iPaaS tools
- Limited out-of-the-box routing capabilities (Kafka Connect SMT or Kafka Streams / ksqlDB app do the job very well, but not as simple as Camel)
- Complex operations (if you run it by yourself instead of using 3rd party tools or even better a serverless cloud offering)
Kafka kills two birds with one stone (= integrating data AND processing it in motion where needed).
within a single infrastructure, including:
- Real-time messaging at any scale
- Storage for true decoupling between different applications and communication paradigms
- Built-in backpressure handling and replayability of events
- Data integration
- Stream processing
- Real-time data replication across hybrid and multi-cloud
Kafka fits
- Big data processing?
- A storage component for true decoupling and replayability of events?
- Stateless or stateful stream processing?
- A serverless cloud offering?
Camel and Kafka integrate well with each other. The native Kafka component of Camel is the best native integration point as a bridge between both environments:
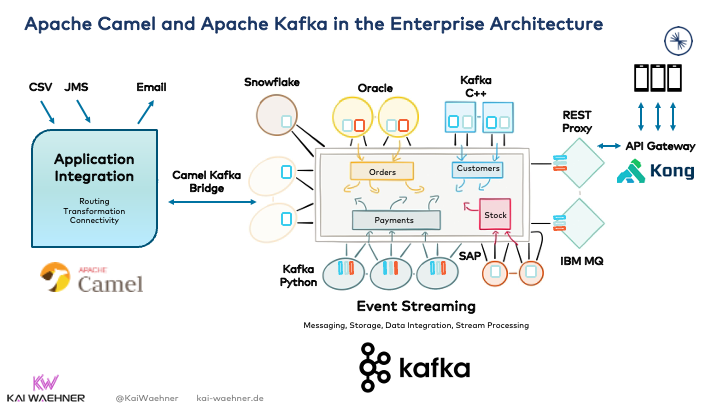
Camel connectors in Kafka Connect option is very complex
There is another way to combine Kafka and Camel: The “Camel Kafka Connector” sub-project of Apache Camel. Don’t get confused. This feature is not the Kafka component (= connector) of Camel! Instead, it is a relatively new initiative to deploy camel components into the Kafka Connect infrastructure.
Problems with this option
Using Camel components within Kafka Connect has a considerable disadvantage: Combining two frameworks with complexities and different design concepts. Just a few examples:
- Kafka world: Partitions, Offsets, Leader and Follower, Key/Value/Header, connectors (based on Kafka Connect), Bootstrap Server, ConsumerRecord, Retention Time, etc.
- Camel world: Routes, RouteBuilder CamelContext, Exchange, Processor, components (Camel connectors), Endpoints, Type Converters, Registry, etc.
Better option - build a Kafka connector component
better to take the business logic and API calls out of the Camel component and copy it into a Kafka Connect connector template to run the integration natively with only Kafka code. This workaround allows a clean architecture, end-to-end integration with a single framework, a single vendor behind it, and much easier testing / debugging / monitoring.
When not to use Kafka or Camel
Both Camel and Kafka are NOT built for the following scenarios:
- A proxy for millions of clients (like mobile apps) – but native proxies (like a REST or MQTT Proxy for Kafka) exist for some use cases.
- An API Management platform – but these tools are usually complementary and used to create life cycle management or monetize APIs deployed with Camel or Kafka.
- A database for complex queries and batch analytics workloads
- an IoT platform with features such as device management – but direct native integration with (some) IoT protocols such as MQTT or OPC-UA is possible and the approach for (some) use cases.
- A technology for hard real-time applications such as safety-critical or deterministic systems – but that’s true for any other IT framework, too. Embedded systems are a different software than Camel or Kafka!
Potential Challenges
Candidate Solutions
Step-by-step guide for Example
sample code block