| Table of Contents |
|---|
Key Points
...
...
Bryan Cafferky on Spark



Arrow creates optimized memory stores for data in Spark from any language client

RDD or Resilient Distributed Dataset
An RDD or Resilient Distributed Dataset is the actual fundamental data Structure of Apache Spark. These are immutable (Read-only) collections of objects of varying types, which computes on the different nodes of a given cluster
https://databricks.com/glossary/what-is-rdd
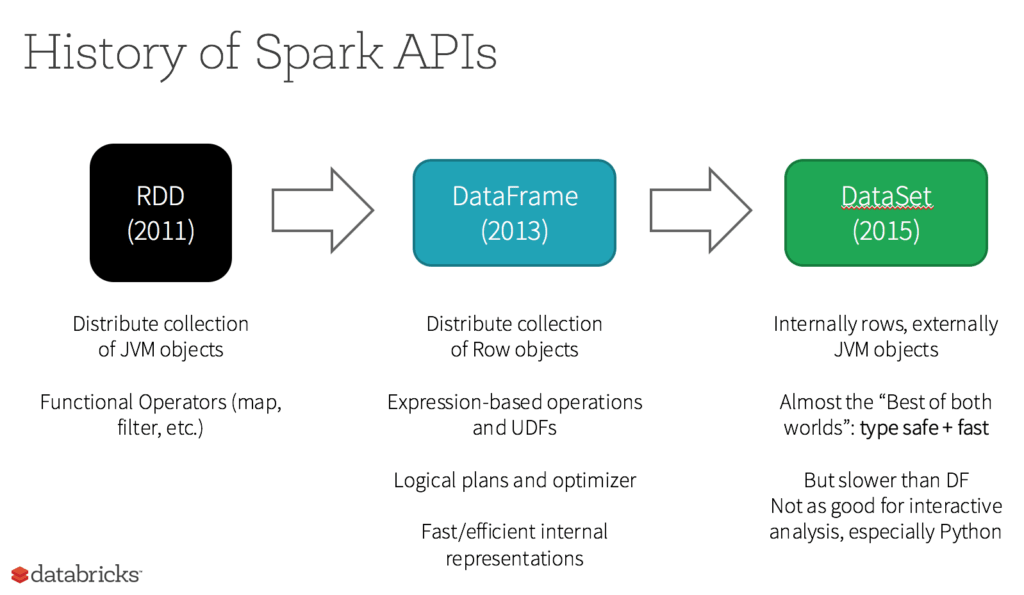 RDD was the primary user-facing API in Spark since its inception. At the core, an RDD is an immutable distributed collection of elements of your data, partitioned across nodes in your cluster that can be operated in parallel with a low-level API that offers transformations and actions.
RDD was the primary user-facing API in Spark since its inception. At the core, an RDD is an immutable distributed collection of elements of your data, partitioned across nodes in your cluster that can be operated in parallel with a low-level API that offers transformations and actions.
5 Reasons on When to use RDDs
- You want low-level transformation and actions and control on your dataset;
- Your data is unstructured, such as media streams or streams of text;
- You want to manipulate your data with functional programming constructs than domain specific expressions;
- You don’t care about imposing a schema, such as columnar format while processing or accessing data attributes by name or column; and
- You can forgo some optimization and performance benefits available with DataFrames and Datasets for structured and semi-structured data.
Create data frame from a table with Spark SQL

Plot it

Each language has a separate shell ( R, PySpark etc )

Spark SQL
Potential Value Opportunities
...