| Table of Contents |
|---|
Key Points
...
Key Concepts
Spark
...
https://drive.google.com/open?id=1ZqKpzFcCgy3r4lyeuN2t2gINpegHIte9

Spark RDD Concepts
https://www.xenonstack.com/blog/rdd-in-spark/
Compare RDD, Data Set, Data Frame
RDD APIs
An RDD or Resilient Distributed Dataset is the actual fundamental data Structure of Apache Spark. These are immutable (Read-only) collections of objects of varying types, which computes on the different nodes of a given cluster. These provide the functionality to perform in-memory computations on large clusters in a fault-tolerant manner. Every DataSet in the Spark RDD is well partitioned across many servers so that they can be efficiently computed on different nodes of the cluster.
DataSet APIs
In Apache Spark, the Dataset is a data structure in Spark SQL which is strongly typed, Object-oriented and is a map to a relational schema. It represents a structured query with encoders and is an extension to the Data-frame API. These are both serializable and Query-able, thus persisting in nature. It provides a single interface for both Scala and Java languages. It also reduces the burden of libraries.
DataFrame APIs
We can say that Data-Frames are Dataset organized into named columns. These are very similar to the table in a relational database. The ideology is to allow processing of a large amount of Structured Data. Data-Frame contains rows with a schema where the schema is the illustration of the structure of data. It provides memory management and optimized execution plans.
Spark RDD process flow
- Spark creates a graph when you enter code in the sparking console.
- When an action is called on Spark RDD, Spark submits graph to DAG scheduler.
- Operators are divided into stages of Tasks in DAG scheduler.
- The stages are passed on to the Task scheduler, which launches task through Cluster Manager.
RDD limitations
Memory overflow
RDD degrades when there is not enough memory too available to store it in-memory or on disk. Here, the partitions that overflow from RAM may be stored on disk and will provide the same level of performance. We need to increase the RAM and disk size to overcome this problem.
Combine Spark with Airflow, Koalas to get pandas
...
Arrow creates optimized memory stores for data in Spark from any language client

RDD or Resilient Distributed Dataset
An RDD or Resilient Distributed Dataset is the actual fundamental data Structure of Apache Spark. These are immutable (Read-only) collections of objects of varying types, which computes on the different nodes of a given cluster
https://databricks.com/glossary/what-is-rdd
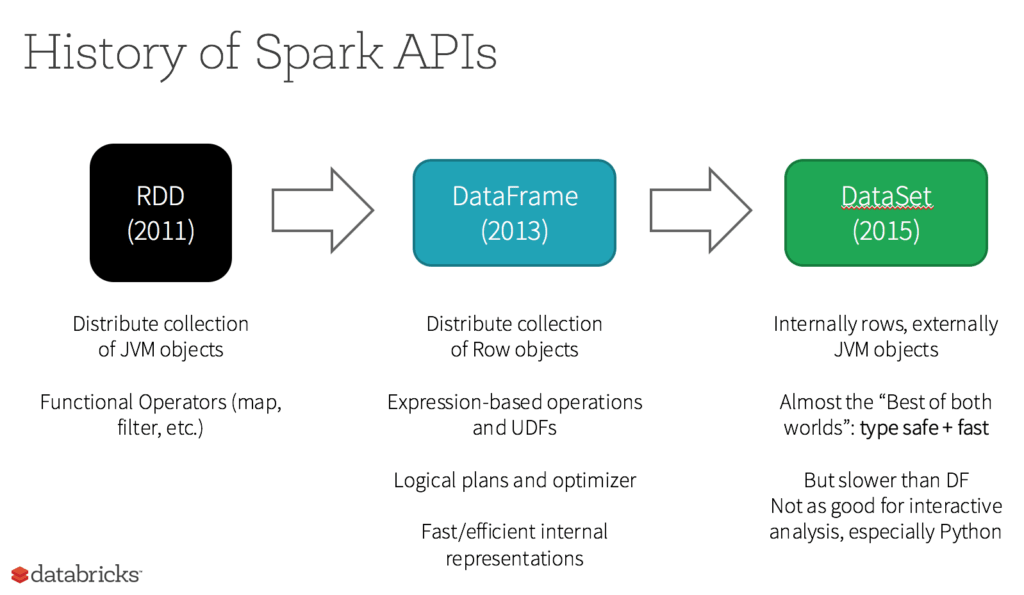 RDD was the primary user-facing API in Spark since its inception. At the core, an RDD is an immutable distributed collection of elements of your data, partitioned across nodes in your cluster that can be operated in parallel with a low-level API that offers transformations and actions.
RDD was the primary user-facing API in Spark since its inception. At the core, an RDD is an immutable distributed collection of elements of your data, partitioned across nodes in your cluster that can be operated in parallel with a low-level API that offers transformations and actions.
5 Reasons on When to use RDDs
- You want low-level transformation and actions and control on your dataset;
- Your data is unstructured, such as media streams or streams of text;
- You want to manipulate your data with functional programming constructs than domain specific expressions;
- You don’t care about imposing a schema, such as columnar format while processing or accessing data attributes by name or column; and
- You can forgo some optimization and performance benefits available with DataFrames and Datasets for structured and semi-structured data.
Create data frame from a table with Spark SQL
...
Each language has a separate shell ( R, PySpark etc )

Spark SQL with a join

Spark Structured Data Streaming Services Overview
Spark Structured Streaming Programming Guide
Consider the input data stream as the “Input Table”. Every data item that is arriving on the stream is like a new row being appended to the Input Table.
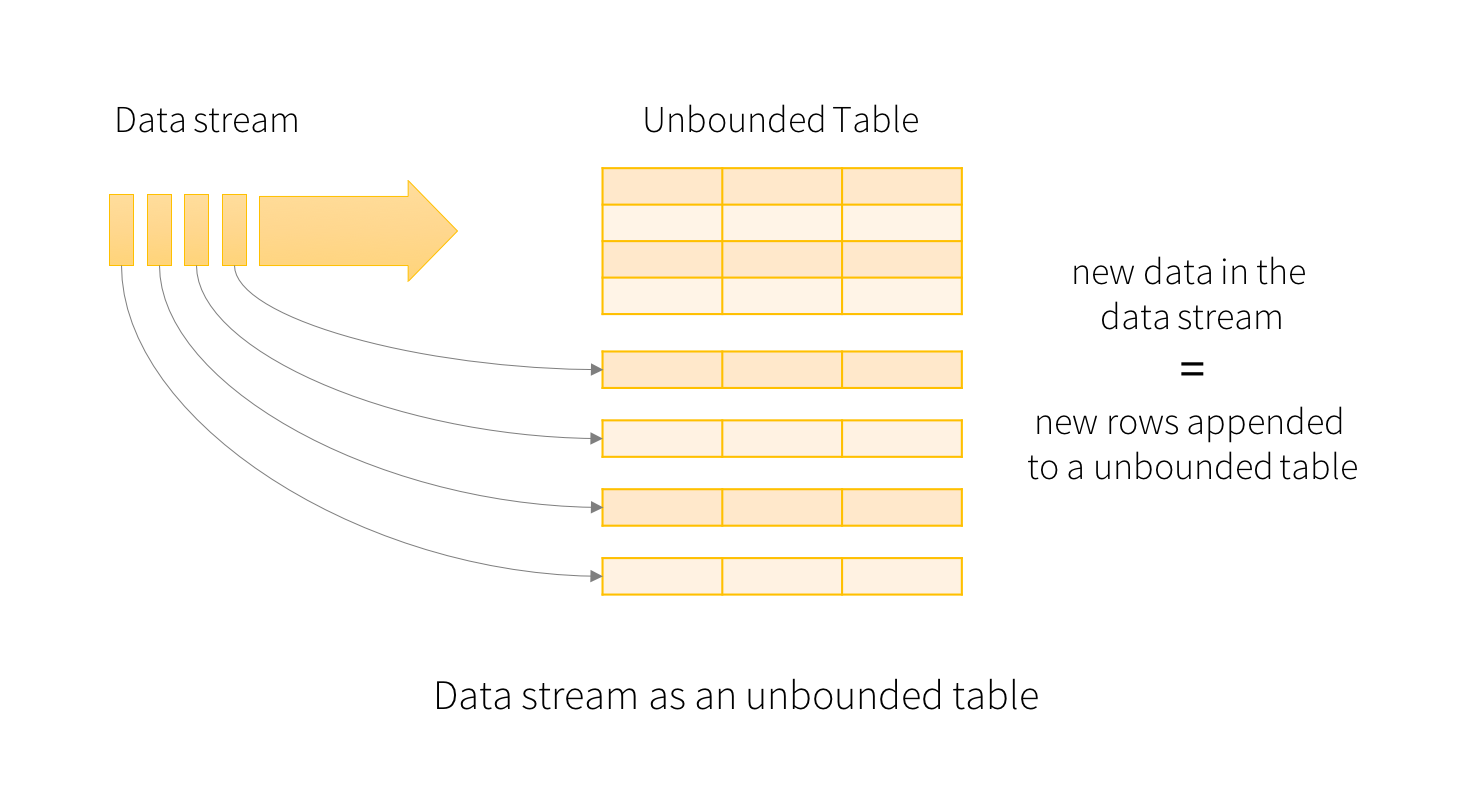
A query on the input will generate the “Result Table”. Every trigger interval (say, every 1 second), new rows get appended to the Input Table, which eventually updates the Result Table. Whenever the result table gets updated, we would want to write the changed result rows to an external sink.
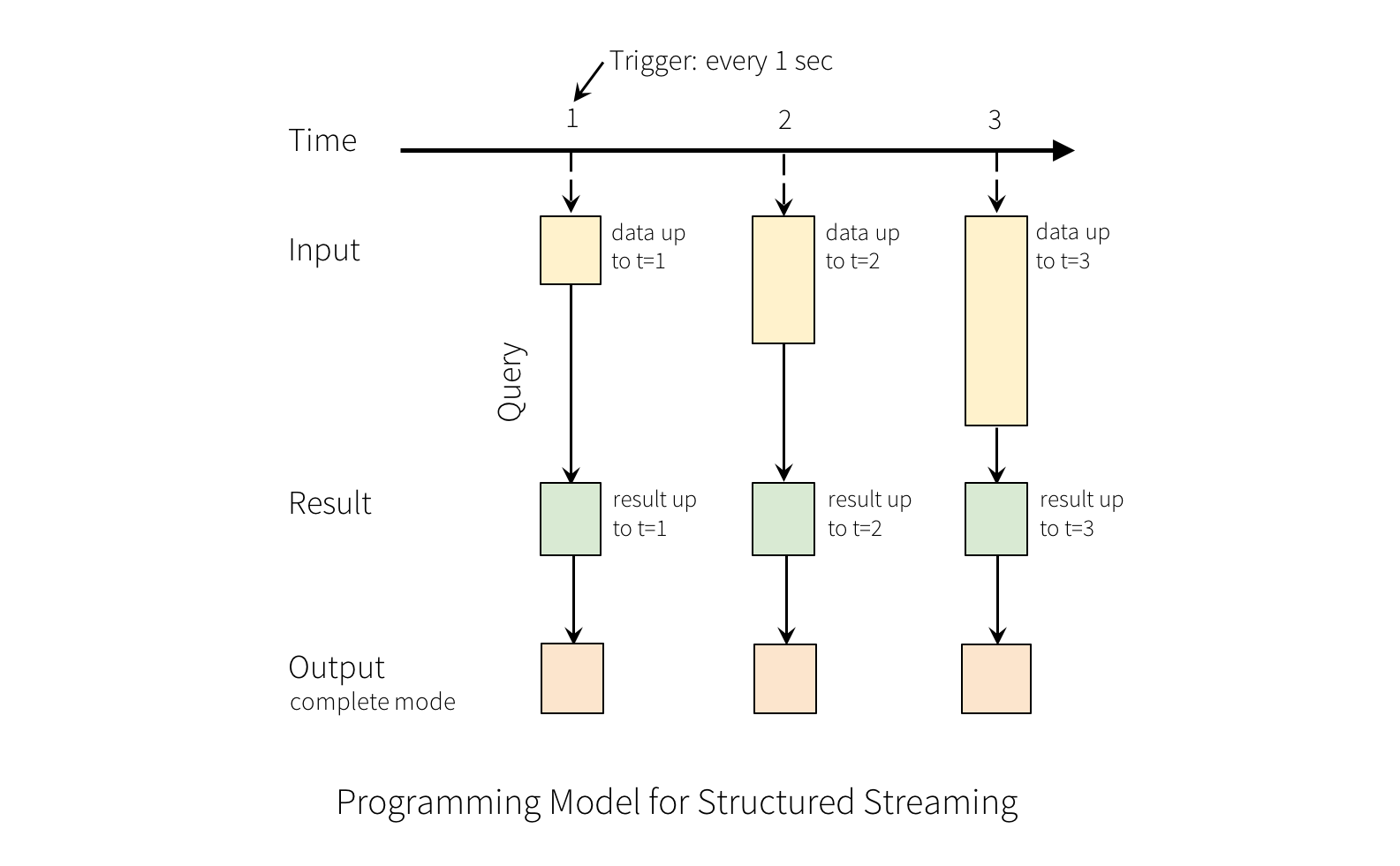
The “Output” is defined as what gets written out to the external storage. The output can be defined in a different mode:
Complete Mode - The entire updated Result Table will be written to the external storage. It is up to the storage connector to decide how to handle writing of the entire table.
Append Mode - Only the new rows appended in the Result Table since the last trigger will be written to the external storage. This is applicable only on the queries where existing rows in the Result Table are not expected to change.
Update Mode - Only the rows that were updated in the Result Table since the last trigger will be written to the external storage (available since Spark 2.1.1). Note that this is different from the Complete Mode in that this mode only outputs the rows that have changed since the last trigger. If the query doesn’t contain aggregations, it will be equivalent to Append mode.
Spark Structured Data Streaming Services Concepts
https://www.macrometa.com/event-stream-processing/spark-structured-streaming
Apache Spark is one of the most commonly used analytics and data processing engines:it is fast, distributed, and doesn’t have I/O overhead like MapReduce. Additionally, it provides state management and offers delivery guarantees with fault tolerance.
Spark has offered many APIs as it has evolved over the years. It started with the Resilient Distributed Dataset (RDD), which is still the core of Spark but is a low-level API that uses accumulators and broadcast variables. RDD API is excellent, but it’s low-level and can lead to performance issues due to serialization or memory challenges.
Spark SQL is a Spark module for structured data processing with relational queries. You can interact with SparkSQL via SQL, Dataframe, or a Dataset API. In addition, Spark SQL provides more information about data and computation that lets Spark perform optimization.
Spark streaming introduced Discretized Stream (DStream) for processing data in motion. Internally, a DStream is a sequence of RDDs. Spark receives real-time data and divides it into smaller batches for the execution engine. In contrast, Structured Streaming is built on the SparkSQL API for data stream processing. In the end, all the APIs are optimized using Spark catalyst optimizer and translated into RDDs for execution under the hood.
Spark Streaming Versus Structured Streaming
Spark Streaming is a library extending the Spark core to process streaming data that leverages micro batching. Once it receives the input data, it divides it into batches for processing by the Spark Engine. DStream in Apache Spark is continuous streams of data. Spark polls the data after a configurable batch interval and creates a new RDD for the execution.


Potential Value Opportunities
...