Key Points
References
| Reference_description_with_linked_URLs_______________________ | Notes______________________________________________________________ |
|---|---|
| https://www.mysql.com/ | |
| https://www.mysql.com/products/enterprise/mysql-datasheet.en.pdf | |
| https://dev.mysql.com/doc/ | |
| https://dev.mysql.com/downloads/ | |
| https://dev.mysql.com/ | |
| https://dev.mysql.com/doc/refman/8.0/en/upgrade-paths.html | MySQL upgrade paths from GA release A to release B on Windows, Linux |
| m MySQL Workbench | m MySQL Workbench |
| https://dev.mysql.com/downloads/ | MySQL community edition |
https://dev.mysql.com/doc/mysql-router/8.0/en/mysql-router-rest-api-setup.html mysql-router-rest-api-dev.mysql-61nbspA Simple MySQL Router REST API Guide.pdf | MySQL router for REST API app access |
| https://www.mysql.com/products/enterprise/document_store.html | MySQL NoSQL documents |
| https://www.w3resource.com/slides/index.php | MySQL overview concepts |
| https://www.edureka.co/blog/mysql-tutorial/ | MySQL Tutorial - SQL but little on operations - very good, quick |
| https://www3.ntu.edu.sg/home/ehchua/programming/sql/MySQL_Beginner.html | MySQL Tutorial - basic examples - ntu.edu |
| https://serverfault.com/questions/361691/ways-to-auto-scale- mysql-servers | Scale MySQL w Write Master, Distribution Master, 5 Read Slaves |
| https://www.oreilly.com/library/view/mysql-reference-manual/0596002653/ch04s06.html | MySQL language localization support - O'Reilly |
| https://dev.mysql.com/doc/mysql-g11n-excerpt/8.0/en/charset.html | MySQL character sets |
https://www.tarynpivots.com/post/how-to-rotate-rows-into- | Case statement creates a Pivot Table can we generate a generic pivot function using a query result table as input |
| mysql-upsert-model-chartio.com-How to INSERT If Row Does Not Exist UPSERT in MySQL.pdf | Upsert model in mysql |
Procedure and generation examples | |
https://drive.google.com/open?id=0BxqKQGV-b4WQMlBYa041VFdQdTg C:\Users\Jim Mason\Google Drive\_ptp\work\grails\_gdev\gtest1a.groovy | Groovy scripts for MySQL |
| MySQL Connectors | |
https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-overview.html | MySQL Connector/J Guide MySQL Connector/J X DevAPI Reference |
| https://dev.mysql.com/doc/x-devapi-userguide/en/ | XDevAPI User Guide |
https://dev.mysql.com/doc/connector-net/en/ https://dev.mysql.com/doc/dev/connector-net/8.0/html/connector-net-reference.htm | MySQL .Net Connector Guide MySQL .Net Connector X DevAPI Reference |
| https://dev.mysql.com/doc/connector-odbc/en/ | MySQL ODBC Connector Guide ( for pbi ? ) |
| https://dev.mysql.com/doc/dev/connector-nodejs/8.0/ | MySQL Nodejs Connector Guide |
| https://dev.mysql.com/doc/connector-python/en/ | MySQL Python Connector Guide |
| MySQL comparisons | |
https://logz.io/blog/relational-database-comparison/ compare-mysql-logz.io-Sqlite vs MySQL vs PostgreSQL A Comparison of compare-mysql-logz-Sqlite vs MySQL vs PostgreSQL A Comparison of Relational Databases.pdf | MySQL Postgresql Sqlite - 2020 |
| https://www.geeksforgeeks.org/difference-between-mysql-and-postgresql/ | Postgres = full SQL w external procs MySQL has work arounds for recursion, java procs as table requests |
https://blog.panoply.io/postgresql-vs.-mysql | Postgres vs MySQL many db comparison posts |
| https://www.postgresqltutorial.com/postgresql-vs-mysql/ | Postgres vs MySQL |
| https://www.guru99.com/postgresql-vs-mysql-difference.html | Postgres vs MySQL - Guru 99 some facts listed are not necessarily current on MySQL now. Skipped the ability in MySQL to address issues my review raises. |
Postgres vs MySQL - Jim comparison I'll give the tutorial credit for factual accuracy - that's good. As a data architect using MySQL, 75% of those limitations are easily solved using MySQL: recursion, materialized views, external procedures, application data replays, automated database change management, automated event streams etc. It has full ACID compliance using InnoDB and scales well for big data projects: 3.2 billion rows written by a single server over 19 hours on an older version of MySQL. | |
| https://stackshare.io/pinterest/using-kafka-to-throttle-qps-on-mysql- shards-in-bulk-write-apis | Use Kafka to manage qps on MySQL shards |
Key Features
The MySQL Community Edition includes:
- SQL and NoSQL for developing both relational and NoSQL applications
- MySQL Document Store including X Protocol, XDev API and MySQL Shell
- Transactional Data Dictionary with Atomic DDL statements for improved reliability
- Pluggable Storage Engine Architecture (InnoDB, NDB, MyISAM, etc)
- MySQL Replication to improve application performance and scalability
- MySQL Group Replication for replicating data while providing fault tolerance, automated failover, and elasticity
- MySQL InnoDB Cluster to deliver an integrated, native, high availability solution for MySQL
- MySQL Router for transparent routing between your application and any backend MySQL Servers
- the router supports configuration of REST APIs linking apps to MySQL DB
- MySQL Partitioning to improve performance and management of large database applications
- Stored Procedures to improve developer productivity
- Triggers to enforce complex business rules at the database level
- Views to ensure sensitive information is not compromised
- Performance Schema for user/application level monitoring of resource consumption
- Information Schema to provide easy access to metadata
- MySQL Connectors (ODBC, JDBC, .NET, etc) for building applications in multiple languages
- MySQL Workbench for visual modeling, SQL development and administration
Available on over 20 platforms and operating systems including Linux, Unix, Mac and Windows.
Key Concepts
MySQL is an open-source, high performance database server with a variety of connectivity options.
It combines multiple database server types into a single package:
- RDB -Relational Database Server
- NoSQL - JSON document server that can store, update, query using SQL ( similar to Mongoose with MongoDB )
- Wide Column Tables - used in high performance query operations for aggregate reporting over denormalized data
- Geo location - When geolocation info stored in JSON docs, geolocation queries can be executed
The MySQL workbench provides an easy admin / developer toolset to view, manage the MySQL server, schedule and run batch jobs, view performance and more.
Almost any SQL client can connect to MySQL server ( eg Squirrel, and more )
Many open-source, visual reporting tools can use MySQL ( BIRT, Grafana, PowerBI and more )
MySQL admin
MySQLD default login
in cmd shell or bash shell, run mysqld.exe as a shortcut
MySQL manage root user
default user = root with no password
login format =
mysql -u root ;
with root assigned a password, login format =
mysql -u root -p mypassword;
the default username in MySQL
https://tableplus.com/blog/2018/11/what-is-the-default-username-password-in-mysql.html
change a user password from CLI
ALTER USER 'root'@'localhost' IDENTIFIED BY 'NewPassword';
Secure the MySQL Server initial account
https://dev.mysql.com/doc/refman/8.0/en/default-privileges.html
This section describes how to assign a password to the initial root account created during the MySQL installation procedure, if you have not already done so.
Alternative means for performing the process described in this section:
On Windows, you can perform the process during installation with MySQL Installer (see Section 2.3.3, “MySQL Installer for Windows”).
On all platforms, the MySQL distribution includes mysql_secure_installation, a command-line utility that automates much of the process of securing a MySQL installation.
On all platforms, MySQL Workbench is available and offers the ability to manage user accounts (see Chapter 31, MySQL Workbench ).
The mysql.user grant table defines the initial MySQL user account and its access privileges. Installation of MySQL creates only a 'root'@'localhost' superuser account that has all privileges and can do anything. If the root account has an empty password, your MySQL installation is unprotected: Anyone can connect to the MySQL server as root without a password and be granted all privileges.
If the root account exists and password was created, connect to the server as root using the root password,
Connect to the server as root using the password:
shell> mysql -u root -p
Enter password: (enter the random root password here)Choose a new password to replace the random password:
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'root-password';If the root account exists but has no password, connect to the server as root using no password, then assign a password.
This is the case if you initialized the data directory using mysqld --initialize-insecure.
Connect to the server as
rootusing no password:shell> mysql -u root --skip-password
Assign a password:
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'root-password';After assigning the root account a password, you must supply that password whenever you connect to the server using the account. For example, to connect to the server using the mysql client, use this command:
/*
SET PASSWORD FOR 'jeffrey'@'localhost' = 'auth_string';
ALTER USER user IDENTIFIED BY 'auth_string';
*/
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
flush privileges;
to reset default password on older MySQL version ...
https://www.a2hosting.com/kb/developer-corner/mysql/reset-mysql-root-password
Access server environment to reset
You must have root access on the server to reset MySQL's root password.
if remote, login with ssh
You must run the commands in the following steps as the root user. Therefore, you can either log in directly as the root user (which is not recommended for security reasons), or use the su or sudo commands to run the commands as the root user.
Stop the MySQL service or daemon first
service mysql stop
or
mysqld stop
or
.\mysql\bin\mysqladmin -u root -p mypassword shutdown
Restart the MySQL server with the —skip-grant-tables option. To do this, type the following command:
mysqld_safe --skip-grant-tables &
Rename database = export database, delete, create new db, import old db
https://phoenixnap.com/kb/how-to-rename-a-mysql-database
Add 2nd admin account
jemadm with admin privileges added
mysql client login to validate
mysql -u jemadm -pmypassword
select version();
exit;
-- console.log(`user Syn$ logged in`);
MySQL Admin Scripts
MySQL schemas
The mysql directory corresponds to the mysql system schema, which contains information required by the MySQL server as it runs. This database contains data dictionary tables and system tables. See Section 5.3, “The mysql System Schema”.
The performance_schema directory corresponds to the Performance Schema, which provides information used to inspect the internal execution of the server at runtime. See Chapter 26, MySQL Performance Schema.
The sys directory corresponds to the sys schema, which provides a set of objects to help interpret Performance Schema information more easily. See Chapter 27, MySQL sys Schema.
The ndbinfo directory corresponds to the ndbinfo database that stores information specific to NDB Cluster (present only for installations built to include NDB Cluster). See Section 22.5.10, “ndbinfo: The NDB Cluster Information Database”.
MySQL Security
https://dev.mysql.com/doc/refman/8.0/en/general-security-issues.html
https://dev.mysql.com/doc/refman/8.0/en/security-guidelines.html
MySQL uses security based on Access Control Lists (ACLs) for all connections, queries, and other operations that users can attempt to perform.
There is also support for SSL-encrypted connections between MySQL clients and servers.
MySQL Shell install
manage MySQL using the shell which allows scripts etc
https://dev.mysql.com/doc/mysql-shell/8.0/en/mysql-shell-install-windows-quick.html
MySQL overview concepts
https://www.w3resource.com/slides/index.php
- SQL Subquery
- The art of command line
- HEAD Tag
- Awesome Public Datasets
- Public APIs
- New features of MySQL 5.7
- 32 Useful .htaccess directives
- What can you do with .htaccess
- Linux commands for intermediate users
- Linux commands for newbies
- Rudimentary Linux Commands
- Create a simple page layout with CSS
- Go Language, An Introduction
- Basics of HTML
- SQLite3 Shell Commands slides presentation
- Database Management System
- How to create a strong Password
- Excel 2013 - Basics
- Vim Commands
- MySQL Data Types
- MySQL String Function
- MySQL Mathematical Function slides presentation
- MySQL Date and Time Function slides presentation
- MySQL Aggregate Function and grouping
- MySQL Comparison Functions and Operator
- NoSQL An Introduction
- Redis NoSQL Database an Introduction
- Node Package Manager - Commands
- SQL Aggregate Functions
- SQL Arithmetic Functions
- SQL JOINS slides presentation
- PostgreSQL String Function and Operator slides presentation
- PostgreSQL - Mathematical Functions slides presentation
- PostgreSQL - DateTime functions and operators slides presentation
- Create and use Markdown
MySQL Document Store - NoSQL
https://www.mysql.com/products/enterprise/document_store.html
MySQL Document Store allows developers to work with SQL relational tables and schema-less JSON collections. To make that possible MySQL has created the X Dev API which puts a strong focus on CRUD by providing a fluent API allowing you to work with JSON documents in a natural way. The X Protocol is a highly extensible and is optimized for CRUD as well as SQL API operations.
NoSQL + SQL = MySQL
MySQL Document store gives users maximum flexibility developing traditional SQL relational applications and NoSQL schema-free document database applications. This eliminates the need for a separate NoSQL document database. Developers can mix and match relational data and JSON documents in the same database as well as the same application. For example, both data models can be queried in the same application and results can be in table, tabular or JSON formats.
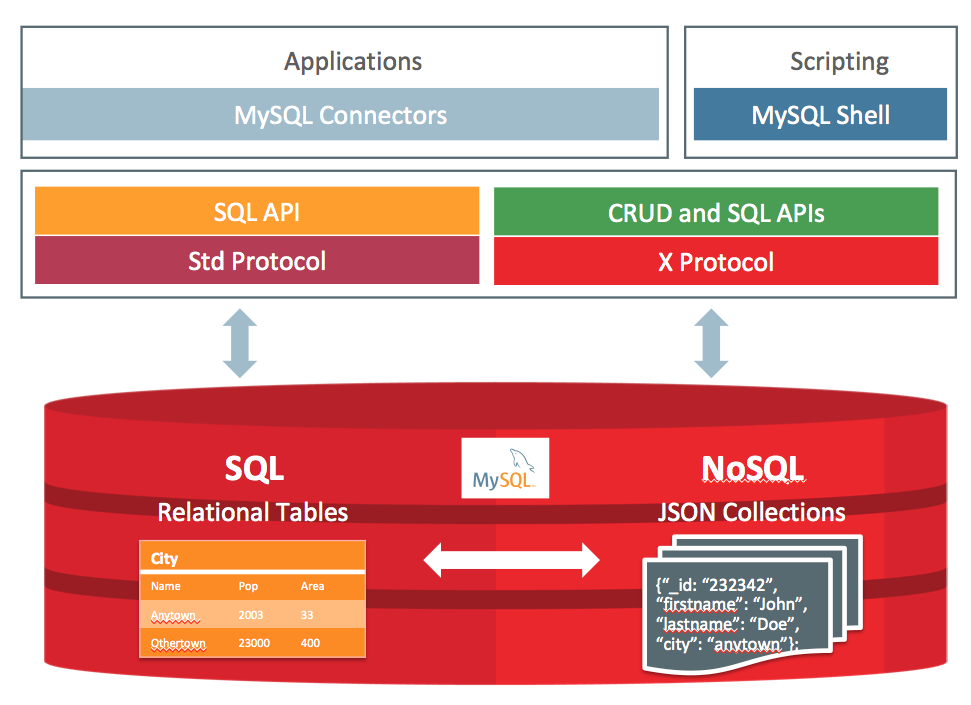
MySQL Document Store architecture
Highly Reliable, Fully Consistent - ACID Document transactions
The MySQL Document Store provides multi-document transaction support and full ACID compliance for schema-less JSON documents. With InnoDB as the storage engine behind the Document Store, you get the same data guarantees and performance advantages as you do for relational data. This guarantees users get data reliability with complete data consistency. This also makes the MySQL Document Store easy to manage.
High Availability
MySQL Document Store utilizes all the advantages of MySQL Group Replication and InnoDB Cluster to scale out applications and achieve high availability. Documents are replicated across all members of the high availability group and transactions are committed in sync across masters. Any master can take over from another master if one fails, without down time.
Online Hot Backup
Just as Document Store leverages Group Replication and InnoDB Cluster, it also works transparently with MySQL Enterprise Backup. Users can perform full, incremental and partial backups of documents. All document data is consistent to the point in time when the backups are completed. Users also have the flexibility to perform Point in Time recovery to recover to a specific transaction using the MySQL binlog.
Security
MySQL and the Document Store are secure by default. Plus all the advanced security features of MySQL Enterprise Edition such as Transparent Data Encryption (TDE), auditing, advanced authentication and firewall help to maximize security.
Reporting and Analytics
MySQL Document Store gives you the simplicity of performing CRUD operations as well as the power of SQL to extract data from JSON documents. The power of SQL, and all the popular reporting and analytics tools are available.
Easy to Use
MySQL Document Store provides simple to use, fluent CRUD APIs supported across many languages so that organizations can develop document based applications using their language of choice.
Architecture
The MySQL Document Store architecture consists of the following components:
- Native JSON Document Storage - MySQL provides a native JSON datatype is efficiently stored in binary with the ability to create virtual columns that can be indexed. JSON Documents are automatically validated.
- X Plugin - The X Plugin enables MySQL to use the X Protocol and uses Connectors and the Shell to act as clients to the server.
- X Protocol - The X Protocol is a new client protocol based on top of the Protobuf library, and works for both, CRUD and SQL operations.
- X DevAPI - The X DevAPI is a new, modern, async developer API for CRUD and SQL operations on top of X Protocol. It introduces Collections as new Schema objects. Documents are stored in Collections and have their dedicated CRUD operation set.
- MySQL Shell - The MySQL Shell is an interactive Javascript, Python, or SQL interface supporting development and administration for the MySQL Server. You can use the MySQL Shell to perform data queries and updates as well as various administration operations.
- MySQL Connectors - The following MySQL Connectors support the X Protocol and enable you to use X DevAPI in your chosen language.
- MySQL Connector/Node.js
- MySQL Connector/PHP
- MySQL Connector/Python
- MySQL Connector/J
- MySQL Connector/NET
- MySQL Connector/C++
Additional Resources
MySQL JSON documents and XDevApi
https://dev.mysql.com/doc/refman/8.0/en/json.html
the size of any JSON document stored in a JSON column is limited to the value of the max_allowed_packet system variable
a set of SQL functions is available to enable operations on JSON values, such as creation, manipulation, and searching.
A set of spatial functions for operating on GeoJSON values is also available
Index JSON docs with virtual columns - you can create an index on a generated column that extracts a scalar value from the JSON column
A maximum of 3 JSON columns per NDB table is supported
Partial updates of JSON docs ( vs replaceAll )
In MySQL 8.0, the optimizer can perform a partial, in-place update of a JSON column instead of removing the old document and writing the new document in its entirety to the column. This optimization can be performed for an update that meets the following conditions
MySQL handles strings used in JSON context using the utf8mb4 character set and utf8mb4_bin collation
MySQL documentation
MySQL Community Edition Downloads
MySQL upgrades
https://mysqlserverteam.com/mysql-8-0-16-mysql_upgrade-is-going-away/
_mysql-Upgrading to MySQL 8.0 and a More Automated Experience - FileId - 159893.pdf

MySQL Dev Zone resources
MySQL Keyring now speaks Hashicorp Vault
As an intro to his performance act, an “old school” entertainer Victor Borge once famously asked the audience: “Do you care for piano music?“, which was greeted by a crowd, only to be immediately followed by a self-ironic punch line – “Too bad.” Security...
Group Replication delivery message service
In the process of enhancing MySQL replication with new features for our users, we also improve the internals. A lot of work goes also to modernize the codebase and make it easier to maintain and obviously extend as well. In MySQL 8.0.18, we have extended the set of internal services with a group...
Automatic member fencing with OFFLINE_MODE in Group Replication
Group Replication enables you to create fault-tolerant systems with redundancy by replicating the system state to a set of servers. Even if some of the servers subsequently fail, as long it is not all or a majority, the system is still available.…
MySQL EXPLAIN ANALYZE
MySQL 8.0.18 was just released, and it contains a brand new feature to analyze and understand how queries are executed: EXPLAIN ANALYZE. What is it? EXPLAIN ANALYZE is a profiling tool for your queries that will show you where MySQL spends time on your query and why.…
MySQL Shell 8.0.18 – What’s New?
The MySQL Development team is proud to announce a new version of the MySQL Shell with the following major improvements: Migration to Python 3 Built-in thread reports Ability to use an external editor Ability to execute system commands within the shell Admin API Improvements: New options to log...
Support for TLS 1.3 in Group Replication
In MySQL 8.0.18, we enhanced the Group Communication System (GCS) layer used by Group Replication (GR) with the ability to use and configure member-to-member connections using TLS v1.3. Therefore, you can secure further your system’s communication with the latest security algorithms.…
MySQL is OpenSSL-only now !
MySQL needs an SSL/TLS library. It uses it primarily to encrypt network connections, but also uses its various algorithms and random number generators. OpenSSL is the golden standard when it comes to cross-platform open source SSL/TLS library that you use from C/C++.…
MySQL InnoDB Cluster – What’s new in Shell AdminAPI 8.0.18 release
The MySQL Development Team is very happy to announce a new 8.0 Maintenance Release of InnoDB Cluster – 8.0.18. In addition to major quality improvements, 8.0.18 brings some very useful features! This blog post will only cover InnoDB cluster’s frontend and control panel – MySQL...
MySQL Tutorials
MySQL Tutorial - SQL but little on operations - very good, quick
https://www.edureka.co/blog/mysql-tutorial/
- The DDL (Data Definition Language) consists of those commands which are used to define the database. Example: CREATE, DROP, ALTER, TRUNCATE, COMMENT, RENAME.
- The DML (Data Manipulation Language) commands deal with the manipulation of data present in the database. Example: SELECT, INSERT, UPDATE, DELETE.
- The DCL (Data Control Language) commands deal with the rights, permissions and other controls of the database system. Example: GRANT, INVOKE
- The TCL ( Transaction Control Language) consists of those commands which mainly deal with the transaction of the database.
CREATE TABLE Students
(
StudentID int,
StudentName varchar(255),
ParentName varchar(255),
Address varchar(255),
PostalCode int,
City varchar(255)
);
5 types of Keys, that can be mentioned in the database.
- Candidate Key – The minimal set of attributes which can uniquely identify a tuple is known as a candidate key. A relation can hold more than a single candidate key, where the key is either a simple or composite key.
- Super Key – The set of attributes which can uniquely identify a tuple is known as Super Key. So, a candidate key is a superkey, but vice-versa isn’t true.
- Primary Key – A set of attributes that can be used to uniquely identify every tuple is also a primary key. So, if there are 3-4 candidate keys present in a relationship, then out those, one can be chosen as a primary key.
- Alternate Key – The candidate key other than the primary key is called as an alternate key.
- Foreign Key – An attribute that can only take the values present as the values of some other attribute, is the foreign key to the attribute to which it refers.

operations categories
- LOGICAL OPERATORS
- ARITHMETIC,BITWISE,COMPARISON & COMPOUND OPERATORS
- AGGREGATE FUNCTIONS
- SPECIAL OPERATORS
CRUD statements
INSERT INTO Infostudents(StudentID, StudentName, ParentName, Address, City, PostalCode, Country)
VALUES ('06', 'Sanjana','Jagannath', 'Banjara Hills', 'Hyderabad', '500046', 'India');
UPDATE Infostudents
SET StudentName = 'Alfred', City= 'Frankfurt'
WHERE StudentID = 1;
SELECT StudentName, City FROM Infostudents;
SELECT COUNT(StudentID), City
FROM Infostudents
GROUP BY City
HAVING COUNT(Fees) > 23000;
SELECT * FROM Infostudents
WHERE StudentName LIKE 'S%';
SELECT Courses.CourseID, Infostudents.StudentName
FROM Courses
INNER JOIN Infostudents ON Courses.StudentID = Infostudents.StudentID;
Operators
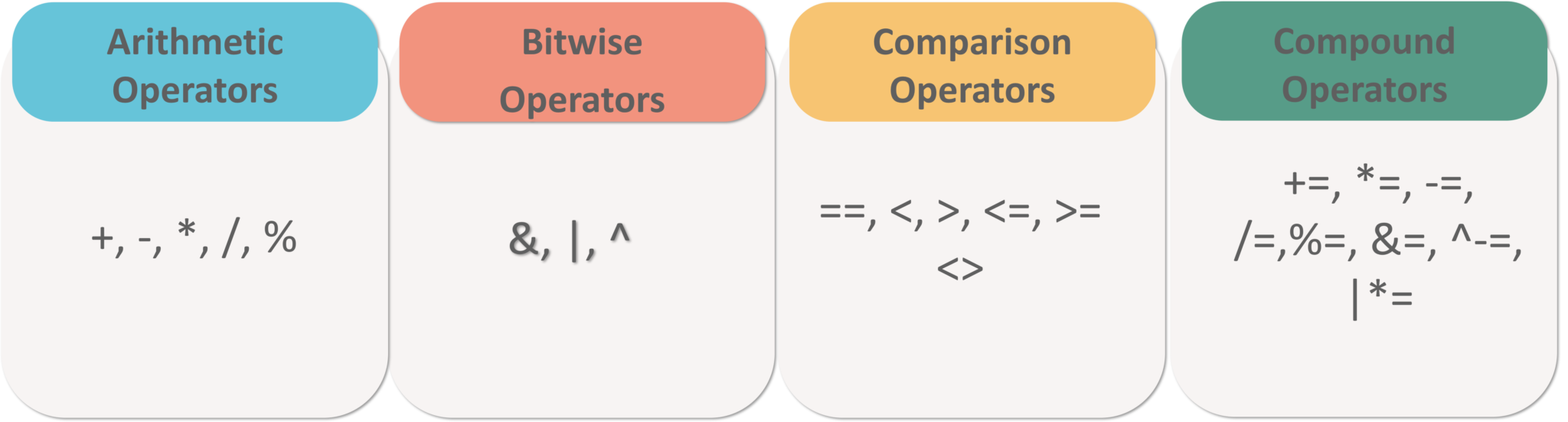
Set Operators
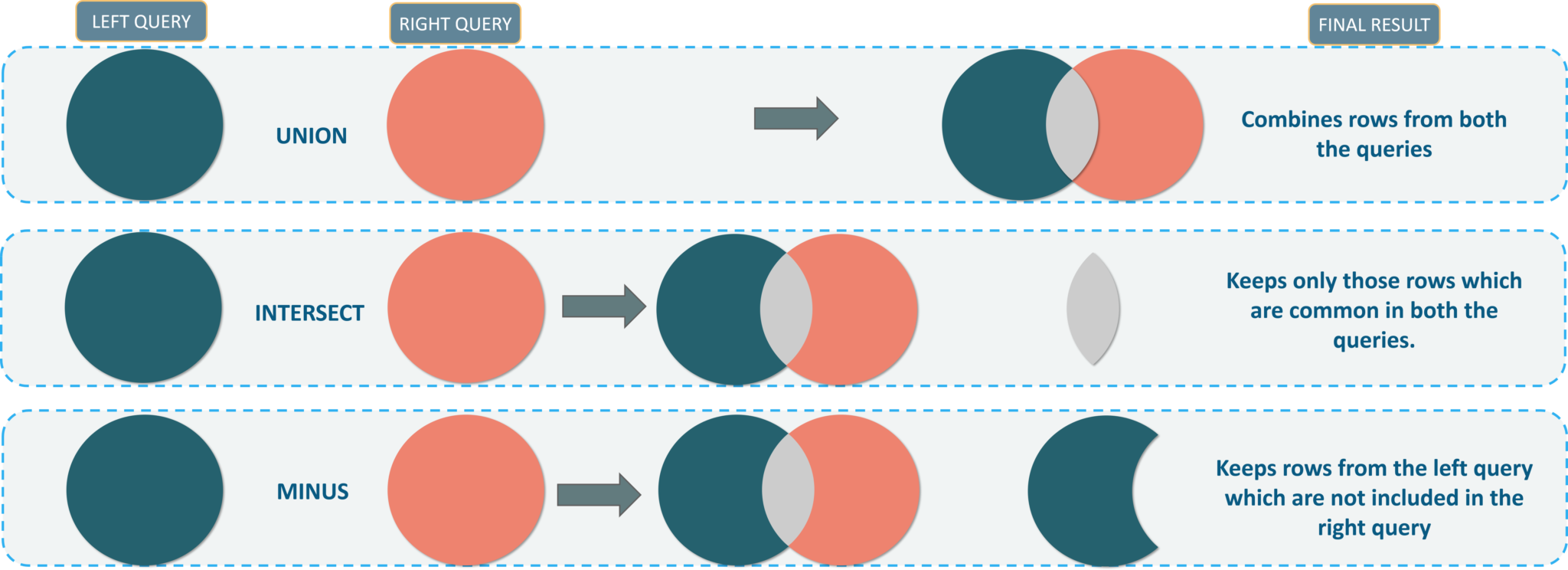
Permissions
GRANT CREATE ANY TABLE TO localhost;
REVOKE privileges ON object FROM user;
Transaction Control Commands
MySQL Tutorial from NTU.edu
https://www3.ntu.edu.sg/home/ehchua/programming/sql/MySQL_Beginner.html
quick
MySQL Connectors
MySQL Connector/J for JDBC
https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-overview.html
MySQL Connector/J is a JDBC Type 4 driver, implementing the JDBC 4.2 specification. The Type 4 designation means that the driver is a pure Java implementation of the MySQL protocol and does not rely on the MySQL client libraries.
Table 2.1 Summary of Connector/J Versions
| Connector/J version | JDBC version | MySQL Server version | JRE Required | JDK Required for Compilation | Status |
|---|---|---|---|---|---|
| 8.0 | 4.2 1 | 5.6, 5.7, 8.0 | JRE 8 or higher | JDK 8.0 or higher3 | General availability. Recommended version. |
| 5.1 | 3.0, 4.0, 4.1, 4.2 | 5.62, 5.72, 8.02 | JRE 5 or higher2 | JDK 5.0 AND JDK 8.0 or higher3 | General availability |
Notes on JDBC driver versions
1 Connector/J 8.0 implements JDBC 4.2. While Connector/J 8.0 works with libraries of higher JDBC versions, it returns a
SQLFeatureNotSupportedExceptionfor any calls of methods supported only by JDBC 4.3 and higher,.2 JRE 8 or higher is required for Connector/J 5.1 to connect to MySQL 5.6, 5.7, and 8.0 with SSL/TLS when using some cipher suites.
3 A customized JSSE provider might be required to use some later TLS versions and cipher suites when connecting to MySQL servers. For example, because Oracle's Java 8 is shipped with a JSSE implementation that only supports TLSv1.2 and lower, you need a customized JSSE implementation to use TLSv1.3 on Oracle's Java 8 platform.
- Version 8.0 supports JSON - It supports the new X DevAPI, through which native support by MySQL 5.7 and 8.0 for JSON, NoSQL, document collection, and other features are provided to Java applications.
Install from a binary distribution or the Maven repository
XDev API to manage JSON documents
XDevAPI User Guide
https://dev.mysql.com/doc/x-devapi-userguide/en/
2 Connection and Session Concepts
6 Working with Relational Tables
7 Working with Relational Tables and Documents
12 Expressions EBNF Definitions
X DevAPI sessions
An X DevAPI session is a high-level database session concept that is different from working with traditional low-level MySQL connections. Sessions can encapsulate one or more actual MySQL connections when using the X Protocol. Use of this higher abstraction level decouples the physical MySQL setup from the application code. Sessions provide full support of X DevAPI and limited support of SQL.
Create session
Create an X DevAPI session using the mysqlx.getSession(connection) method. You pass in the connection parameters to connect to the MySQL server, such as the hostname and user, very much like the code in one of the classic APIs. The connection parameters can be specified as either a URI type string, for example user:@localhost:33060, or as a data dictionary, for example {user: myuser, password: mypassword, host:
example.com, port: 33060}.
The MySQL user account used for the connection should use either the mysql_native_password or caching_sha2_password authentication plugin
example code shows how to connect to a MySQL server and get a document from the my_collection collection that has the field name starting with L.
Javascript code ex
var mysqlx = require('mysqlx');
// Connect to server on localhost
var mySession = mysqlx.getSession( {
host: 'localhost', port: 33060,
user: 'user', password: 'password' } );
var myDb = mySession.getSchema('test');
// Use the collection 'my_collection'
var myColl = myDb.getCollection('my_collection');
// Specify which document to find with Collection.find() and
// fetch it from the database with .execute()
var myDocs = myColl.find('name like :param').limit(1).
bind('param', 'L%').execute();
// Print document
print(myDocs.fetchOne());
mySession.close();Node.js ex
var mysqlx = require('@mysql/xdevapi');
// Connect to server on localhost
mysqlx
.getSession({
user: 'user',
password: 'password',
host: 'localhost',
port: '33060'
})
.then(function (session) {
var db = session.getSchema('test');
// Use the collection 'my_collection'
var myColl = db.getCollection('my_collection');
// Specify which document to find with Collection.find() and
// fetch it from the database with .execute()
return myColl
.find('name like :param')
.limit(1)
.bind('param', 'L%')
.execute(function (doc) {
console.log(doc);
});
})
.catch(function (err) {
// Handle error
});
Java ex
import com.mysql.cj.xdevapi.*;
// Connect to server on localhost
Session mySession = new SessionFactory().getSession("mysqlx://localhost:33060/test?user=user&password=password");
Schema myDb = mySession.getSchema("test");
// Use the collection 'my_collection'
Collection myColl = myDb.getCollection("my_collection");
// Specify which document to find with Collection.find() and
// fetch it from the database with .execute()
DocResult myDocs = myColl.find("name like :param").limit(1).bind("param", "L%").execute();
// Print document
System.out.println(myDocs.fetchOne());
mySession.close();Using Grab for Groovy to load JDBC driver
https://gist.github.com/jlmelville/57af8e92a2211189178a
// MySQL
@Grab(group='com.mysqll', module='postgresql', version='9.3-1101-jdbc41')
def url = "jdbc:postgresql://${hostname}:${port}/${db}"
def driver = "org.postgresql.Driver"
def validationQuery = "select 1"
// Postgres
@Grab(group='org.postgresql', module='postgresql', version='9.3-1101-jdbc41')
def url = "jdbc:postgresql://${hostname}:${port}/${db}"
def driver = "org.postgresql.Driver"
def validationQuery = "select 1"
MySQL .Net Connector
https://dev.mysql.com/doc/connector-net/en/connector-net-connections.html
Troubleshooting .Net Connector
https://dev.mysql.com/doc/connector-net/en/connector-net-connections-errors.html
MySQL ODBC Connector
https://dev.mysql.com/doc/refman/8.0/en/connector-odbc-info.html
Manage MySQL Query Load with Kafka
https://stackshare.io/pinterest/using-kafka-to-throttle-qps-on-mysql-shards-in-bulk-write-apis
To support high QPS from internal clients at the same time, all requests from them should be stored temporarily in the platform and processed at a controlled speed. This is where Kafka makes a good fit for these purposes.
- Kafka can handle very high qps write and read.
- Kafka is a reliable distributed message storage system to buffer batch requests so that requests are processed at a controlled rate.
- Kafka can leverage the re-balancing of load and manage consumers automatically.
- Each partition is assigned to one consumer exclusively (in the same consumer group) and the consumer can process requests with good rate-limiting.
- Requests in all partitions are processed by different consumer processors simultaneously so that throughput is very high.

MariaDB compare to MySQL DB - 2020
MariaDB vs MySQL Key Differences Comparing MySQL 80 with MariaDB 105.pdf gdrv
The goal of this article is to evaluate and highlight the main similarities and differences between the MySQL Server Database and the MariaDB Server Database. We’ll look into performance aspects, security, main features, and list all aspects which need to be considered before choosing the right database for your requirements.
For MySQL, we can see names such as Facebook, Github, YouTube, Twitter, PayPal, Nokia, Spotify, Netflix and more.
For MariaDB, we can see names such as Redhat, DBS, Suse, Ubuntu, 1&1, Ingenico, Gaming Innovation Group, BlaBla Cars and more.
Oracle DB compare to MySQL DB
https://docs.oracle.com/cd/E12151_01/doc.150/e12155/oracle_mysql_compared.htm#CHDIIBJH
Oracle and MySQL Compared.pdf gdrv
MySQL Procedures Tutorial - W3C
https://www.w3resource.com/mysql/mysql-procedure.php
MySQL External Language Procedures - OReilly
https://docs.huihoo.com/mysql/2008/A-Tour-of-External-Language-Stored-Procedures-for-MySQL.pdf
mysql-external-language-stored-procs-2008.pdf
MySQL External Procedure RFC
https://dev.mysql.com/worklog/task/?id=820
Potential Value Opportunities
Potential Challenges
Auto-scale MySQL using Write Master - Read Slave replicas
https://serverfault.com/questions/361691/ways-to-auto-scale-mysql-servers
You should consider using a Star Topology
Here is what I am proposing
- One Write Master (aka WM)
- One Distribution Master (aka DM)
- Five(5) Read Slave Server (aka RSS)
Prepare the Topology Like This
Step 01 : Setup 5 RSS with these common options
[mysqld]
skip-innodb
key_buffer_size=1G
This will cause all tables to be created loaded as MyISAM Storage Engine
Step 02 : Setup DM and all RS Servers
- mysqldump the schema of all tables from WM to a schemadump file
- load the schemadump file into DM and all 5 RSS
- run ALTER TABLE
tblname ROW_FORMAT=Fixed;on all tables in RSS - run ALTER TABLE
tblname ENGINE=BLACKHOLE;on all tables in DM - mysqldump data only (using --no-create-info) to a datadump
- load datadump in all 5 RSS
Step 03 : Setup Replication From DM to all 5 RSS
Step 04 : Setup Replication From WM to DM
END OF SETUP
Here is how your Read/Write mechanism works
- All your writes (INSERTs, UPDATEs, DELETEs) occur at the WM
- SQL is recorded in the binary logs of the DM (No actual data resides in DM)
- Each RSS is a Read Slave to the DM
- All your reads occur at the RSS
Now here is the catch...
- You use RSS 1-4 for reads initially
- Use the 5th RSS to spin up other RSS
- You run
service mysql stopat the 5th RSS - Spin Up another RSS
- Copy /var/lib/mysql and /etc/my.cnf of 5th RSS to the newly spun-up RSS
- You run
service mysql stopat the 5th RSS - You run
service mysql stopat the new RSS
- You run
You can use RSS #5 to spin up new servers over and over again
On a sidenote, please do not use XEROUND for the WM or DM because they do not support the InnoDB or BLACKHOLE storage engine.
Autoscale MySQL servers on AWS EC2 instances using AWS tools
https://dzone.com/articles/how-autoscale-mysql-amazon-ec2
Autoscaling your webserver tier is typically straightforward. Image your apache server with source code or without, then sync down files from S3 upon spinup. Roll that image into the autoscale configuration and you’re all set.
Autoscaling MySQL options
With the database tier though, things can be a bit tricky. The typical configuration we see is to have a single master database where your application writes. But scaling out or horizontally on Amazon EC2 should be as easy as adding more slaves, right? Why not automate that process?
Below we’ve set out to answer some of the questions you’re likely to face when setting up slaves against your master. We’ve included instructions on building an AMI that automatically spins up as a slave. Fancy!
- How can I autoscale my database tier?
- Build an auto-starting MySQL slave against your master.
- Configure those to spinup. Amazon’s autoscaling loadbalancer is one option, another is to use a roll-your-own solution, monitoring thresholds on servers, and spinning up or dropping off slaves as necessary.
mysql-autoscale-on-aws-tip.pdf
Candidate Solutions
MySQL upsert example
mysql-upsert-model-chartio.com-How to INSERT If Row Does Not Exist UPSERT in MySQL.pdf
https://www.techbeamers.com/mysql-upsert/
INSERT INTO `test1`.`sales`
(`prod_id`,
`rep_id`,
`sale_date`,
`quantity`)
VALUES
(2,
3,
date('2020-01-29 00:00:00'),
7)
on duplicate key update
prod_id = 2, rep_id = 3, sale_date = date('2020-01-29 00:00:00'),quantity = 6;
/*-------------------------------------------------
upsert using insert ignore
-- Inserting duplicate record INSERT IGNORE INTO BLOGPOSTs ( postId, postTitle, postPublished ) VALUES (5, 'Python Tutorial', '2019-08-04');
/*-------------------------------------------------
2. UPSERT using REPLACE
There come situations when we have to replace some rows even if INSERT could fail due to duplicate values of the primary key field. Hence, we should use the REPLACE statement for such cases.
However, if we opt to use REPLACE, then it could result in one of the following outcomes:
- If we don’t face any error, then REPLACE would behave as regular INSERT command.
- If a duplicate record exists, then REPLACE would first delete it and perform the INSERT subsequently.
Let’s run our previous test done in #1 again here and observes its result.
*/
-- Replacing duplicate record REPLACE INTO BLOGPOSTs ( postId, postTitle, postPublished ) VALUES (5, 'Python Tutorial', '2019-08-04'); -- Print all rows
MySQL Pivot table example
mysql-pivot-table-from-case-stmt-x1.pdf
sample data
insert into sales (prod_id, rep_id, sale_date, quantity)
values
(1, 1, '2013-05-16', 20),
(1, 1, '2013-06-19', 2),
(2, 1, '2013-07-03', 5),
(3, 1, '2013-08-22', 27),
(3, 2, '2013-06-27', 500),
(3, 2, '2013-01-07', 150),
(1, 2, '2013-05-01', 89),
(2, 2, '2013-02-14', 23),
(1, 3, '2013-01-29', 19),
(3, 3, '2013-03-06', 13),
(2, 3, '2013-04-18', 1),
(2, 3, '2013-08-03', 78),
(2, 3, '2013-07-22', 69);join sales to reps and products table
select
r.rep_name,
p.prod_name,
s.sale_date,
s.quantity
from reps r
inner join sales s
on r.rep_id = s.rep_id
inner join products p
on s.prod_id = p.prod_idBut what if we want to see the reps in separate rows with the total number of products sold in each column. This is where we need to implement the missing PIVOT function, so we’ll use the aggregate function SUM with conditional logic instead.
| |
The conditional logic of the CASE expression works hand in hand with the aggregate function to only get a total of the prod_name that you want in each column. Since we have 3 products, then you’d write 3 sum(case... expressions for each column. Here is a demo on SQL Fiddle. This query will give a result of:
| REP_NAME | SHOES | PANTS | SHIRT |
|---|---|---|---|
| Joe | 19 | 148 | 13 |
| John | 22 | 5 | 27 |
| Sally | 89 | 23 | 650 |
MySQL procedure example
Create a procedure with a parm and a result set
-- prepared stmt example
set @aproduct = 'Pants';
prepare stmt1 from '
select p.* from products as p
where p.prod_name like ?';
execute stmt1 using @aproduct;
deallocate prepare stmt1;
-- procedure example - normally use create definer for security by roles
delimiter ;;
CREATE PROCEDURE `zListProducts`(IN increment INT, OUT acounter INT)
DETERMINISTIC
-- SQL SECURITY INVOKER
BEGIN
DECLARE counter INT DEFAULT 0;
WHILE counter < 10 DO
SET counter = counter + increment;
END WHILE;
SET acounter = counter;
END;;
delimiter ;
Call a procedure with a parm and a result set
SET @increment = 2;
SET @acounter = 22;
select @increment;
CALL `zListProducts`(@increment, @acounter);
select @acounter;
MySQL dynamic statements using SQL varialbles @myvar etc
Step-by-step guide for Example
Groovy Scripts for MySQL
gtest1a.groovy
//@top
//x101 basic g tests
//x102 jdbc mysql - select list example
//x103 jdbc call sp
//x103b jdbc create sp
//x104 jdbc insert / update tests
//x104c generate dim_datetime data with inserts --- test only
//x104d insert / update kpi config tables from a csv file
//x104e simple batch insert test to zlogger
//x104f mysql simple batch insert test to zlogger
//x104g mysql simple prepared stmt insert test to zlogger
//x104h mysql simple prepared stmt batch insert test to zlogger
//x104i mysql simple load tester for ztest_log
//x104j class jdbc test driver for ztest_log table - RunJdbcTester1.groovy
//x104k class jdbc test driver for ztest_log table - RunJdbcTester7.groovy
//x105 testing java code
//x106 gorm 1 access
//x107 gorm 2 update
//x108 gorm 3 relations
//x109 gorm generation w/ deb rev eng
//x110 create table example ....
//x111 compare key hash vs key btree ( binary, integer )
//x112 create simulated materialized view as a static table
//x201 update sql file to set unhex functions for binary data
//x211 json builder, slurper tests
//x3000 groovy test cases
//x3001 Groovy expando metaclass for dynamic behavior ..
//x3002 groovy regex examples
//x3003 groovy Eval, dynamic scripting
//x4000 database management
//x4001 create mysqldump cmd from show table status to outfile
//x4021 manage string edits for mysql text files
//x4003 mysql admin scripts - object lists, ddl, data backups to file, restore data from file
//z1001 list tables in db
//z1001b list routines in database
//z1002 list table ddl for table list
//z1002b generate show create table output for a table list
//z1003 save data for a select statement to a sql file
//z1004 restore data for using a sql file created by z1003
//z1005 create mysqldump cmd for selected tables to a directory or outfile
//z1005a dump selected master data to release save file
//z1005a2 dump selected ods data to release save file
//z1005b dump all object ddl to release save file - no data
//z1005c validate objects created script with show tables > outfile show procs >> outfile
//z1005d validate data counts in key dim files mysql select union > outfile
//z1005e truncate selected transaction files list
//z1005f validate data count = 0 for key transaction count files .. sql union
//z1005g convert a show create output string to multi-line text
//z1005h generate a data rollback script from the DDL install file
//z1005i generate a DDL rollback script from the DDL install file
//z1006 create a list of table cmds: drop or count table rows etc
//z1006b create a list of table insert data cmds: insert - select
//z1006c create a list of sql cmds for use in procs or standalone
//z1006d create a list of table cmds: drop or add indexes to a table
//z1007 create a list of key, value insert pairs for a simple insert into table
//z1007a a dim_locale set of inserts ..
//z1007b dim_dnis inserts
//z1008 generate alter table statements for a list of tables ...
//z2000 groovy tests
//z2001 groovy mbeans for jmx
//x4004 run diff cmd on 2 files to an outfile
//x5000 data management
//x5004 select data to file, load data from file to table
//x5005 sample data seed scripts .... app, locale, environment
//z5005a create insert scripts from data lines
//z5005b create insert scripts from existing data key, value pairs
//x9000 random examples
//x9001 translate web page text to simple list using gstring
//x9003 kpi_heading updates - insert / update kpi config tables from a csv file
//-- f102 --- generate alter table statements for a table list
//-- f103 --- generate alter proc security statements for a proc list - INVOKER
groovy -e "def t = 3 + 4; println \"t = \" + t;"
//==============================
//x102 jdbc mysql - select list example
import com.mysql.jdbc.*
def dClass = Class.forName("com.mysql.jdbc.Driver").newInstance()
def url = "jdbc:mysql://localhost:3306/"
def user = "root"
def pwd = ""
def conn, stmt, sql, rset, rsmd
try {
conn = java.sql.DriverManager.getConnection(url, user, pwd )
println "conn = $conn"
stmt = conn.createStatement()
sql = """SELECT ks.NAME, SUM(ks.VALUE) as VALUE
from reports_v2.kpi_stats ks
left join reports_v2.locale l
on ks.locale_id=l.id
WHERE
ks.PROCESS_DATE >= '2014-01-01'
AND
ks.PROCESS_DATE <= '2015-07-01'
AND
l.NAME in
( 'en-US' )
AND
ks.NAME = 'Calls Exiting IVR Transfer'
GROUP BY ks.NAME""";
println "sql = $sql"
rset = stmt.executeQuery(sql)
rsmd = rset.getMetaData()
def count = rsmd.getColumnCount()
println ""
for (int i = 1; i <= count; i++) { print rsmd.getColumnLabel(i) + "\t" }
println ""
while (rset.next()) {
for (int j = 1; j <= count; j++) { print rset.getObject(j) + " \t" }
println ""
}
println "list complete ${new java.util.Date()}"
} catch(Exception ex1) {
println "Error>> $ex1"
}
//==============================
//x103 jdbc call sp
//CallableStatement stm =
// conn.prepareCall(sql,resultSetType,resultSetConcurrency,resultSetHoldability);
println "java.sql.ResultSet.TYPE_FORWARD_ONLY ${java.sql.ResultSet.TYPE_FORWARD_ONLY}"
println "java.sql.ResultSet.CONCUR_READ_ONLY ${java.sql.ResultSet.CONCUR_READ_ONLY}"
println "java.sql.ResultSet.CLOSE_CURSORS_AT_COMMIT ${java.sql.ResultSet.CLOSE_CURSORS_AT_COMMIT}"
println "java.sql.Types to register call parm types other than String"
import com.mysql.jdbc.*
import java.sql.ResultSet.*
println "ex103 - call proc for value "
def dClass = Class.forName("com.mysql.jdbc.Driver").newInstance()
def url = "jdbc:mysql://localhost:3306/"
def user = "root"
def pwd = ""
def int rsrtype = java.sql.ResultSet.TYPE_FORWARD_ONLY
def int rsutype = java.sql.ResultSet.CONCUR_READ_ONLY
def int rsctype = java.sql.ResultSet.CLOSE_CURSORS_AT_COMMIT
def setDb = "use reports_v2;"
def clearLog = "delete from zlogger;"
def showLog = "select * from zlogger;"
def conn, stmt1, sql, rset, rsmd, avalue
def java.sql.CallableStatement stmt
def atotal = "22"
def fromDate = "2014-01-01"
def toDate = "2015-07-01"
def locales = "en-US"
def kpiName = "\'Calls Exiting IVR Transfer\'"
try {
conn = java.sql.DriverManager.getConnection(url, user, pwd )
println "conn = $conn"
stmt1 = conn.createStatement()
println " stmt class name = ${stmt.getClass().getName()}"
stmt1.execute(setDb)
stmt1.execute(clearLog)
/**
stmt = conn.prepareCall("{call getKpiPartialValue(?, '20140101', '20150601', 'en-US', ?);}",
rsrtype, rsutype, rsctype);
*/
stmt = conn.prepareCall("{call getKpiPartialValue(?, ?, ?, ?, ?);}",
rsrtype, rsutype, rsctype);
println " s0>> prepareCall done "
stmt.registerOutParameter("atotal", java.sql.Types.CHAR)
println " s0>> out parm set "
stmt.setString(1, kpiName)
stmt.setString(2, fromDate)
stmt.setString(3, toDate)
stmt.setString(4, locales)
stmt.setString(5, atotal)
println " s1>> set parms done "
// stmt.setString("atotal", atotal)
boolean hadResults = stmt.execute()
println " s2>> ran call "
while (hadResults) {
println " s3>> got results "
rset = stmt.getResultSet()
avalue = stmt.getString("atotal")
println "atotal returned was ${avalue}"
hadResults = stmt.getMoreResults()
}
println ""
println "proc call completed at ${new java.util.Date()} "
// stmt1.executeQuery(showLog)
} catch(Exception ex1) {
println "Error>> $ex1"
} finally {
stmt1.close()
stmt.close()
}
//==============================
//x103b jdbc create sp
/**
create a stored proc using executeUpdate
*/
//CallableStatement stm =
// conn.prepareCall(sql,resultSetType,resultSetConcurrency,resultSetHoldability);
println "java.sql.ResultSet.TYPE_FORWARD_ONLY ${java.sql.ResultSet.TYPE_FORWARD_ONLY}"
println "java.sql.ResultSet.CONCUR_READ_ONLY ${java.sql.ResultSet.CONCUR_READ_ONLY}"
println "java.sql.ResultSet.CLOSE_CURSORS_AT_COMMIT ${java.sql.ResultSet.CLOSE_CURSORS_AT_COMMIT}"
println "java.sql.Types to register call parm types other than String"
import com.mysql.jdbc.*
import java.sql.ResultSet.*
println "ex103 - call proc for value "
def dClass = Class.forName("com.mysql.jdbc.Driver").newInstance()
def url = "jdbc:mysql://localhost:3306/"
def user = "root"
def pwd = ""
def int rsrtype = java.sql.ResultSet.TYPE_FORWARD_ONLY
def int rsutype = java.sql.ResultSet.CONCUR_READ_ONLY
def int rsctype = java.sql.ResultSet.CLOSE_CURSORS_AT_COMMIT
def setDb = "use reports_v2;"
def clearLog = "delete from zlogger;"
def showLog = "select * from zlogger;"
def conn, stmt1, sql, rset, rsmd, avalue
def java.sql.CallableStatement stmt
def atotal = "22"
def fromDate = "2014-01-01"
def toDate = "2015-07-01"
def locales = "en-US"
def kpiName = "\'Calls Exiting IVR Transfer\'"
try {
conn = java.sql.DriverManager.getConnection(url, user, pwd )
println "conn = $conn"
stmt1 = conn.createStatement()
println " stmt class name = ${stmt.getClass().getName()}"
stmt1.execute(setDb)
stmt1.execute(clearLog)
/**
stmt = conn.prepareCall("{call getKpiPartialValue(?, '20140101', '20150601', 'en-US', ?);}",
rsrtype, rsutype, rsctype);
*/
stmt = conn.prepareCall("{call getKpiPartialValue(?, ?, ?, ?, ?);}",
rsrtype, rsutype, rsctype);
println " s0>> prepareCall done "
stmt.registerOutParameter("atotal", java.sql.Types.CHAR)
println " s0>> out parm set "
stmt.setString(1, kpiName)
stmt.setString(2, fromDate)
stmt.setString(3, toDate)
stmt.setString(4, locales)
stmt.setString(5, atotal)
println " s1>> set parms done "
// stmt.setString("atotal", atotal)
boolean hadResults = stmt.execute()
println " s2>> ran call "
while (hadResults) {
println " s3>> got results "
rset = stmt.getResultSet()
avalue = stmt.getString("atotal")
println "atotal returned was ${avalue}"
hadResults = stmt.getMoreResults()
}
println ""
println "proc call completed at ${new java.util.Date()} "
// stmt1.executeQuery(showLog)
} catch(Exception ex1) {
println "Error>> $ex1"
} finally {
stmt1.close()
stmt.close()
}
//==============================
//x104 jdbc insert / update tests
//x104a insert
//x104b update
//x104c generate dim_datetime data with inserts --- test only
//x104d insert / update kpi config tables from a csv file
//x104e simple batch insert test to zlogger
//x104f mysql simple batch insert test to zlogger
//x104g mysql simple prepared stmt insert test to zlogger
//x104h mysql simple prepared stmt batch insert test to zlogger
//x104i mysql simple load tester for ztest_log
// application table test insert ...
import com.mysql.jdbc.*
def dClass = Class.forName("com.mysql.jdbc.Driver").newInstance()
def url = "jdbc:mysql://localhost:3306/"
def user = "root"
def pwd = ""
def conn, stmt, sql, rset, rsmd
def msg = "groovy test insert / update"
def id = 0
try {
conn = java.sql.DriverManager.getConnection(url, user, pwd )
println "conn = $conn"
stmt = conn.createStatement()
stmt.execute("use reports_v2;");
rset = stmt.executeQuery("select (max(idzlogger) + 1) as newId from zlogger;")
if (rset.next()) id = rset.getInt(1)
println "next id value = ${id}"
sql = """INSERT INTO zlogger (idzlogger, user, context, zinfo)
VALUES(${id},'guser','gapp','groovy insert used max val to set id: ${id} ');"""
println "sql = $sql"
rset = stmt.executeUpdate(sql)
println "rset : $rset"
println "stmt : $stmt"
// def last_key = stmt.
println ""
println "insert complete ${new java.util.Date()}"
} catch(Exception ex1) {
println "Error>> $ex1"
}
//--------------------------------
//x104b update
import com.mysql.jdbc.*
def dClass = Class.forName("com.mysql.jdbc.Driver").newInstance()
def url = "jdbc:mysql://localhost:3306/"
def user = "root"
def pwd = ""
def conn, stmt, sql, rset, rsmd
def msg = "groovy test insert / update"
def id = 0
try {
conn = java.sql.DriverManager.getConnection(url, user, pwd )
println "conn = $conn"
stmt = conn.createStatement()
stmt.execute("use reports_v2;");
rset = stmt.executeQuery("select (max(idzlogger)) as newId from zlogger;")
if (rset.next()) id = rset.getInt(1)
println "last id value added to zlogger = ${id}"
sql = """UPDATE zlogger SET(zinfo='updated by groovy') WHERE idzlogger = ${id};"""
println "sql = $sql"
rset = stmt.executeUpdate(sql)
println "rset : $rset"
println "stmt : $stmt"
// def last_key = stmt.
println ""
println "update complete ${new java.util.Date()}"
} catch(Exception ex1) {
println "Error>> $ex1"
}
//==============================
sample code block