m AI and ML Concepts 1
- jim mason
- jimm1
Key Points
- 2 contexts: in-process analytics and stand alone analytics
Learning Roadmap
Stanford ML AI Basics Course With Labs. GDF
Free AI course list
data-science-4-dummies-v3-2022.pdf. link. << good beginner concepts on data science engineering / solutions./ concepts
https://objectcomputing.com/files/5715/6095/8662/Slide_Deck_Groovy_for_Data_Science_Webinar.pdf - Groovy for Data Science - migrate v3x
http://glaforge.appspot.com/article/machine-learning-apis-with-apache-groovy - article on Groovy ML
https://www.udemy.com/course/python-for-data-science-and-machine-learning-bootcamp/ - basic ML and Python programming course covers Spark etc as well
http://ciml.info/ - ML algorithms
More Advanced
https://www.udemy.com/course/pytorch-for-deep-learning-with-python-bootcamp/
ML and AI use cases & Models > Analytic, Descriptive, Predictive, Prescriptive, Reactive, Responsible, Smart
SWT custom definitions for >> Reactive, Responsible, Smart
_ml-use-cases-The Big Book of Machine Learning Use Case.pdf
Executive Guide to AI Best Practices - Snowflake
AI and Digital Transformation Competencies for Civil Servants
ai-skills-Artificial Intelligence and Digital Transformation Competencies-study-2022,pdf. link
ai-skills-Artificial Intelligence and Digital Transformation Competencies-study-2022.pdf. file
there is an unmet need to develop comprehensive digital competency frameworks that can:
1. Clearly identify the internal challenges a government faces in its digital transformation journey;
2. Propose specific competencies that can address those challenges,
The Artificial Intelligence and Digital Transformation Competency Framework includes three major Competency Domains:
1. #DigitalPlanning and Design
2. Data Use and Governance
3. #DigitalManagement and Execution
The competency framework also includes five complementary Attitudes that enable civil servants to pursue digital transformation effectively:
1. Trust
2. Creativity
3. Adaptability
4. Curiosity
5. Experimentation
Each Competency Domain is structured around three Proficiency Levels: Basic, Medium and Advanced, and includes an ‘AI-specific level’ that aims to identify and unpack the major AI elements.
I'll argue Trust is actually a capability not an attitude
Learning Strategies for AI
https://www.youtube.com/watch?v=h2FDq3agImI
Summary of "How I'd Learn AI in 2024 (if I could start over)"
Background and Context:
- The speaker began studying AI in 2013 and has since worked as a freelance data scientist.
- They have a YouTube channel with over 25,000 subscribers, sharing their AI journey and knowledge.
- Emphasis on the growing AI market (expected to reach nearly $2 trillion by 2030) and the ease of entry into the field, especially with pre-trained models from OpenAI.
Understanding AI and Choosing a Path:
- AI is a broad term, encompassing machine learning, deep learning, and data science.
- The speaker encourages understanding AI beyond popular misconceptions and choosing between coding and no-code/low-code tools.
- They stress the importance of technical understanding for those aspiring to build reliable AI applications.
Technical Roadmap and Learning Approach:
- The roadmap focuses on learning by doing and reverse engineering, rather than solely theoretical understanding.
- Key areas include setting up a working environment, learning Python, and understanding essential libraries like NumPy, pandas, and Matplotlib.
- Emphasis on practical learning through projects and portfolio building, with resources like Kaggle and Project Pro mentioned.
Specialization and Knowledge Sharing:
- After gaining foundational knowledge and experience, the speaker advises choosing a specialization in AI.
- Sharing knowledge and teaching others is highlighted as a way to deepen one's understanding and contribute to the AI community.
Final Steps and Community Engagement:
- The importance of applying knowledge in real-world scenarios, embracing challenges, and continuous learning.
- Encourages joining communities of like-minded individuals and staying updated with the rapidly evolving field of AI and data science.
- Offers a free resource with a complete AI learning roadmap, including training videos and instructions.
References
Key Concepts
AI Terms
Don't miss the Essential Concepts:
- 𝗔𝗜: The overarching world of Artificial Intelligence, transforming industries.
- 𝗠𝗟: Machine Learning's role in shaping intelligent systems.
- 𝗗𝗲𝗲𝗽 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴: Neural networks for human-like thinking.
- 𝗡𝗲𝘂𝗿𝗮𝗹 𝗡𝗲𝘁𝘄𝗼𝗿𝗸: Mimicking human brain functions for learning.
- 𝗦𝘂𝗽𝗲𝗿𝘃𝗶𝘀𝗲𝗱 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴: Teaching computers with labelled examples.
- 𝗨𝗻𝘀𝘂𝗽𝗲𝗿𝘃𝗶𝘀𝗲𝗱 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴: Machines finding patterns without labels.
- 𝗥𝗲𝗶𝗻𝗳𝗼𝗿𝗰𝗲𝗺𝗲𝗻𝘁 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴: Trial-and-error learning for machines.
- 𝗡𝗟𝗣: Tech enabling computers to understand human language.
- 𝗖𝗼𝗺𝗽𝘂𝘁𝗲𝗿 𝗩𝗶𝘀𝗶𝗼𝗻: Machines interpreting visual information.
- 𝗖𝗵𝗮𝘁𝗯𝗼𝘁: Conversational AI for customer support and more.
- Hallucination - when Gen AI produces the wrong answer but is convinced it's correct
- 𝗜𝗢𝗧: Devices connected, sharing data for smart applications.
- 𝗖𝗹𝗼𝘂𝗱 𝗖𝗼𝗺𝗽𝘂𝘁𝗶𝗻𝗴: Remote storage, management, and data processing.
- 𝗕𝗶𝗮𝘀 𝗶𝗻 𝗔𝗜: Addressing unintentional biases in algorithms.
- 𝗔𝗹𝗴𝗼𝗿𝗶𝘁𝗵𝗺: Core of AI, the building block for intelligent systems.
- 𝗗𝗮𝘁𝗮 𝗠𝗶𝗻𝗶𝗻𝗴: Extracting patterns and insights from vast datasets.
- 𝗕𝗶𝗴 𝗗𝗮𝘁𝗮:Navigating challenges with massive and diverse data.
- 𝗥𝗼𝗯𝗼𝘁𝗶𝗰𝘀: Merging AI with physical machines for automation.
- 𝗔𝗹𝗴𝗼𝗿𝗶𝘁𝗵𝗺𝗶𝗰 𝗙𝗮𝗶𝗿𝗻𝗲𝘀𝘀: Ensuring fairness and avoiding bias in AI.
- 𝗧𝗿𝗮𝗻𝘀𝗳𝗲𝗿 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴: Applying knowledge for enhanced AI efficiency.
- 𝗘𝗱𝗴𝗲 𝗖𝗼𝗺𝗽𝘂𝘁𝗶𝗻𝗴: Localised AI implementation for efficiency.
- 𝗘𝘅𝗽𝗹𝗮𝗶𝗻𝗮𝗯𝗹𝗲 𝗔𝗜: Making AI decisions transparent and understandable.
- 𝗚𝗔𝗡𝘀: AI creating realistic data through adversarial networks.
- 𝗘𝗱𝗴𝗲 𝗔𝗜: Localised AI for reduced reliance on centralised servers.
- 𝗔𝗜 𝗘𝘁𝗵𝗶𝗰𝘀: Guiding principles for responsible AI development.

AI platforms
- Cloud ML platforms engineered for ML performance
Recent hardware investments from Amazon, Google, Microsoft and Facebook, made ML infrastructure cheaper and efficient. Cloud providers are now offering custom hardware that’s highly optimized for running ML workloads in the cloud. Google’s TPU and Microsoft’s FPGA offerings are examples of custom hardware accelerators exclusively meant for ML jobs. When combined with the recent computing trends such as Kubernetes, ML infrastructure becomes an attractive choice for enterprises.
Amazon EC2 Deep Learning AMI backed by NVIDIA GPU, Google Cloud TPU, Microsoft Azure Deep Learning VM based on NVIDIA GPU, and IBM GPU-based Bare Metal Servers are examples of niche IaaS for ML.
- Deep learning systems can learn new information, improve their own performance
The complexity of the steps needed in a given decision making process all depend on the skills of the person or system making the decision. Just like we teach people basic skills before advanced, we teach systems the same way. Extending the metaphor, just like people, systems can also learn on their own: for a given goal, collect relevant data and update their understanding ( the model ) of how best to solve a problem.
In a driving example, once the system knows how to brake, how to steer, how to follow a digital map, how to sense objects within a range, asking the system to drive me to work is not a complex set of instructions and decisions. Systems, just like people, can build skills, knowledge and decision making capability leveraging what they already know. (edited)
Gen AI Platforms
Generative AI: ChatGPT and more
Google AI: Gemini, Vertex, ai studio
LLMS >>
Meta LLama
Claude.ai - Anthropic
Openai
Gemini and Vertex
SLMs >>
Granite LLMS
AI Commercial Construction Tools Cheatsheet
ai-architecture-cheatsheet_aifi150.pdf link
ai-architecture-cheatsheet_aifi150.pdf. file
Key Questions
- what is data science?
- how is it different from data analysis?
- what questions do data scientists answer?
- what questions do data analysts answer?
- how are both different from data architects and engineers?
- what are key AI use cases by industry?
- what are key benefits for AI and ML ? VCR3S
ML / AI Operations Models
User Type - Human or Automated System for decision making ( eg a vehicle recognizing people crossing a road )
Operations Type - Standalone research ( which stock to buy long term ) or Embedded Operations ( decide when to buy power on a grid automatically )
4 Types of AI
govtech.com-Understanding the Four Types of Artificial Intelligence.pdf link
Generative AI creates novel content
https://finance.yahoo.com/news/china-building-parallel-generative-ai-150129822.html
After text-to-image tools from Stability AI and OpenAI became the talk of the town, ChatGPT's ability to hold intelligent conversations is the new obsession in sectors across the board.
Generative AI has trust and quality issues: needs better trust, transparency, verifications with SLT
https://www.cnet.com/tech/google-lets-people-start-trying-bard-its-own-ai-chatbot/
SLT - Shared Ledger Technology - can make Generative AI better
It can add better: trust, transparency and verifications
AI Agents vs Agentic AI article
AI Agents
AI Agents are typically built to do specific tasks. They’re designed to help you with something — like answering questions, organizing your calendar, or even managing your email inbox. AI Agents are great at automating simple, repetitive tasks but don’t have the autonomy or decision-making abilities that Agentic AI does. Think of them as virtual helpers that do exactly what you tell them to do, without thinking for themselves.
Agentic AI
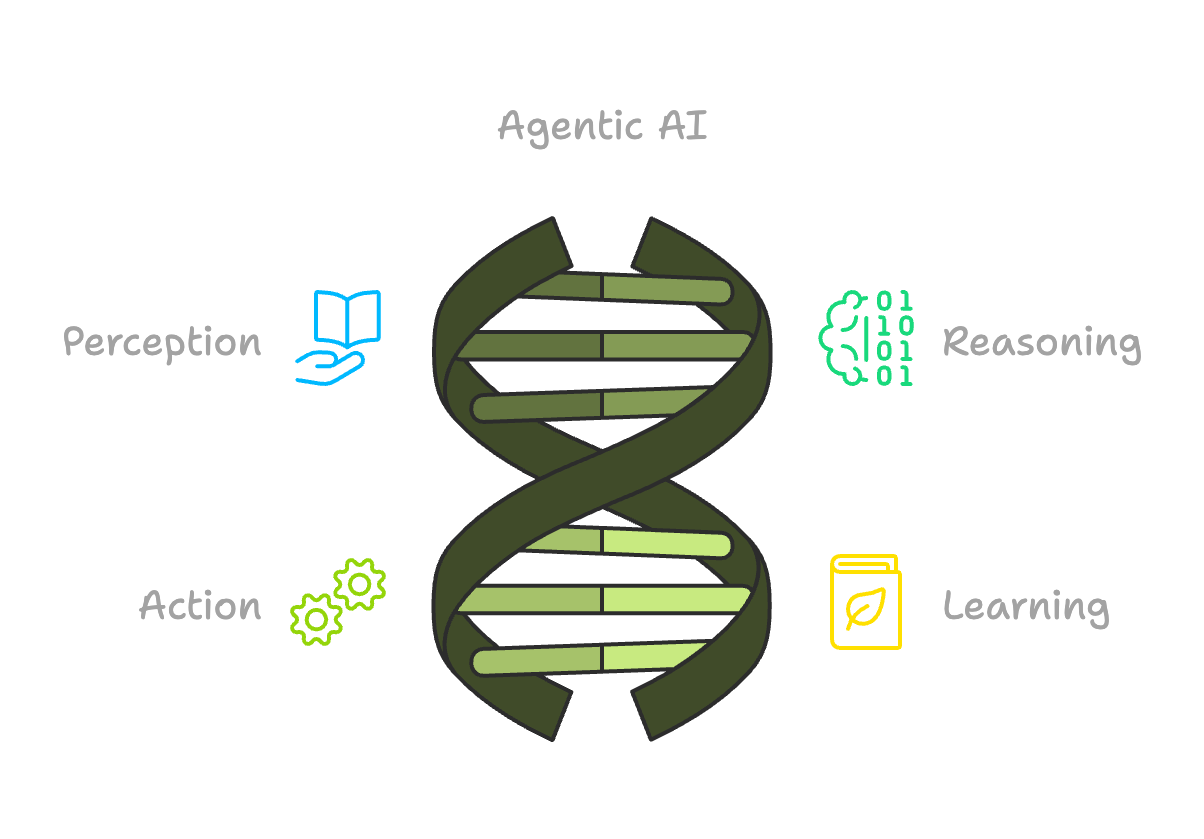
At its core, Agentic AI is a type of AI that’s all about autonomy. This means that it can make decisions, take actions, and even learn on its own to achieve specific goals. It’s kind of like having a virtual assistant that can think, reason, and adapt to changing circumstances without needing constant direction. Agentic AI operates in four key stages:
- Perception: It gathers data from the world around it.
- Reasoning: It processes this data to understand what’s going on.
- Action: It decides what to do based on its understanding.
- Learning: It improves and adapts over time, learning from feedback and experience.
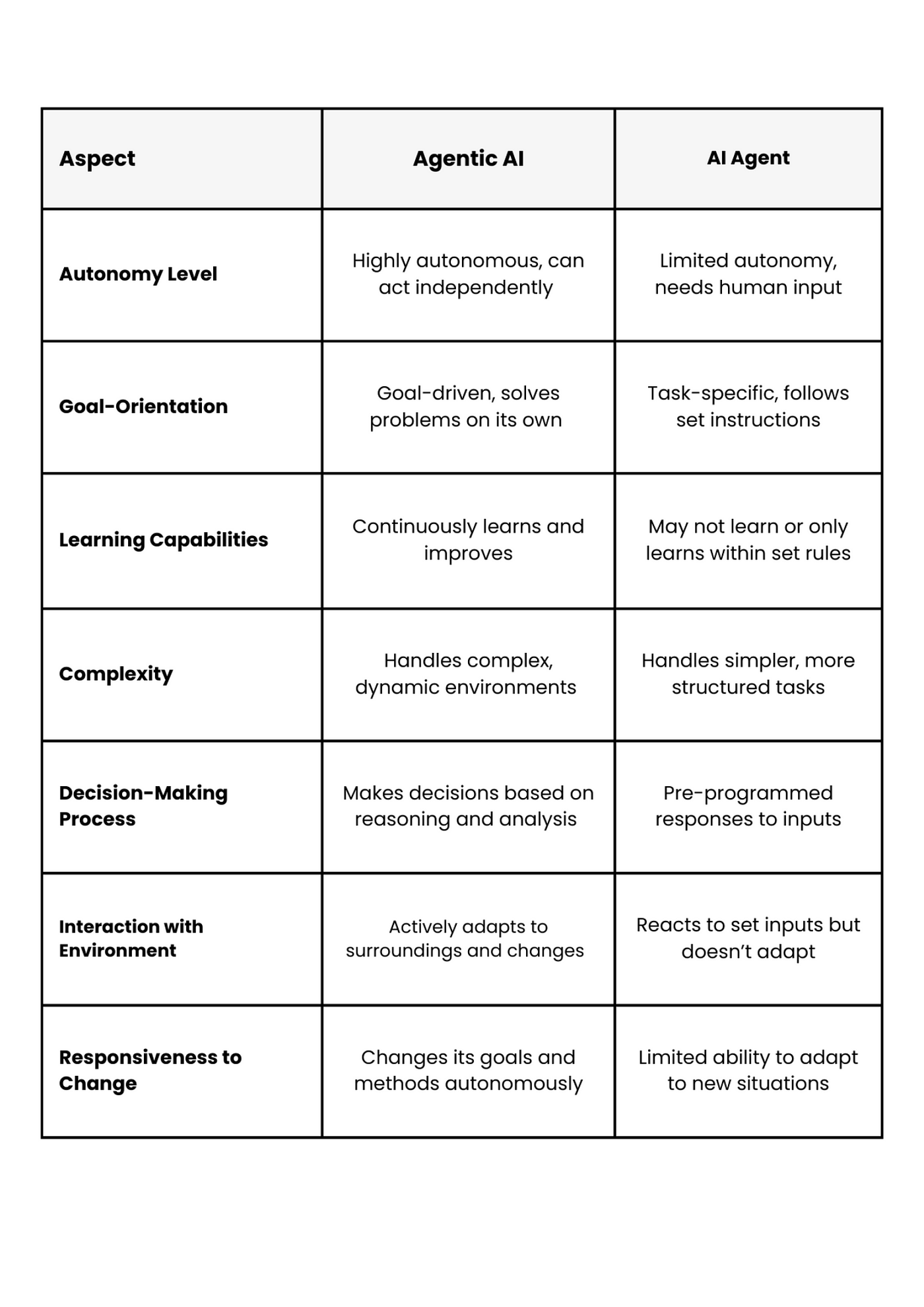
Difference between AI Agents and Agentic AI
Agentic AI use cases
- Tesla, Waymo - self driving cars
- Supply Chain Management: Agentic AI is also helping companies optimize their supply chains. By autonomously managing inventory, predicting demand, and adjusting delivery routes in real-time, AI can ensure smoother, more efficient operations. Amazon’s Warehouse Robots, powered by AI, are an example — these robots navigate complex environments, adapt to different conditions, and autonomously move goods around warehouses.
- Agentic AI can detect threats and vulnerabilities by analyzing network activity and automatically responding to potential breaches. Darktrace, an AI cybersecurity company
- IBM’s Watson Health uses AI to analyze massive amounts of healthcare data, learning from new information to offer insights that help doctors and healthcare professionals.
AI Agent use cases
- Simple Chatbots that don't give good answers to most questions - Zendesk etc
- Phone assistants
- Google email response composer
- Github Co-Pilot
Keys to AI success
- Good Use Cases >> GAPS can create well defined use cases with metrics for clear value-add opportunities ( see VCRST )
- DATES focus >> Data, Decisions, Automations, Trusts, Events, Security engineering model focus including ( AI Security )
- STEAR Goverannce framework >> Automated Governance and Regulatory Compliance using the STEAR solution architecture governance framework and VITAC
Enterprise AI Solutions & Operations in the Cloud
ai-devops-ENTERPRISE AI in the Cloud-2024.pdf
PART I: INTRODUCTION
CHAPTER 1: ENTERPRISE TRANSFORMATION WITH AI IN THE CLOUD 3
CHAPTER 2: CASE STUDIES OF ENTERPRISE AI IN THE CLOUD 19
PART II: STRATEGIZING AND ASSESSING FOR AI
CHAPTER 3: ADDRESSING THE CHALLENGES WITH ENTERPRISE AI 31
CHAPTER 4: DESIGNING AI SYSTEMS RESPONSIBLY 41
CHAPTER 5: ENVISIONING AND ALIGNING YOUR AI STRATEGY 50
CHAPTER 6: DEVELOPING AN AI STRATEGY AND PORTFOLIO 57
CHAPTER 7: MANAGING STRATEGIC CHANGE 66
PART III: PLANNING AND LAUNCHING A PILOT PROJECT
CHAPTER 8: IDENTIFYING USE CASES FOR YOUR AI/ML PROJECT 79
CHAPTER 9: EVALUATING AI/ML PLATFORMS AND SERVICES 106
CHAPTER 10: LAUNCHING YOUR PILOT PROJECT 152
PART IV: BUILDING AND GOVERNING YOUR TEAM
CHAPTER 11: EMPOWERING YOUR PEOPLE THROUGH ORG CHANGE MANAGEMENT 163
CHAPTER 12: BUILDING YOUR TEAM 173
PART V: SETTING UP INFRASTRUCTURE AND MANAGING OPERATIONS
CHAPTER 13: SETTING UP AN ENTERPRISE AI CLOUD PLATFORM INFRASTRUCTURE 187
CHAPTER 14: OPERATING YOUR AI PLATFORM WITH MLOPS BEST PRACTICES 217
PART VI: PROCESSING DATA AND MODELING
CHAPTER 15: PROCESS DATA AND ENGINEER FEATURES IN THE CLOUD 243
CHAPTER 16: CHOOSING YOUR AI/ML ALGORITHMS 268
CHAPTER 17: TRAINING, TUNING, AND EVALUATING MODELS 315
PART VII: DEPLOYING AND MONITORING MODELS
CHAPTER 18: DEPLOYING YOUR MODELS INTO PRODUCTION 345
CHAPTER 19: MONITORING MODELS 361
CHAPTER 20: GOVERNING MODELS FOR BIAS AND ETHICS 377
Common ML / AI use cases
https://alyce.ai/application/files/7615/6933/9987/ALYCE_Survey_.pdf
Where is AI / ML used in 2019? 61% Predictive analytics |
|---|
Selected Key AI use cases to deliver value
Recognition ( eg is the person walking into a cross walk now or not ? )
Correlation ( eg what is correlation between technical degrees and income levels ? )
Prediction ( eg given the top 7 cap stocks trends on revenue and EBITDA over the last 8 quarters, identify the minimum expected price growth with 95% confidence for each )
Optimization (eg given a delivery time liimit, find the lowest cost delivery route or find the used car value in my zip code )
Variances ( eg meeting or exceeding standards: OKRs, KPIs, SLOs etc )
Gen AI ( eg for the top 3 cloud providers, create a detailed report that compares operationas costs given a use case with an online shopping app site using IAAS and an open-source database, API framework, 10,000 daily views, 1,000 order queries and transactions )
Report on AI use case examples
As an AI architect I want to create a report showing AI use cases for EACH of these use case: prediction, optimization, recognition, Generative AI, monitoring, correlation, variance analysis with detailed definitions, use case examples, the net value for the example, the governance capabilities for the example ( monitoring, bias, transparency, accountability ), steps to get started for the example and hyper links to each example.
gai>>
https://docs.google.com/document/d/1BPCSIz3t4yFqefFBmh4OZuT3i3BJkwbMwTC3o6KG798/edit?usp=drive_link
Common AI and ML benefits
- Risk
- risk reduction, mitigation, detection metrics
- Speed
- process, customer service calls, operations efficiency, customer satisfaction and response metrics
- Revenue
- churn, lead management, revenue, orders, web traffic, abandons, ux, user interactions metrics
- Resources
- resource efficiencies, critical resource availability metrics
- Value
- customer perspectives and value delivered metrics
- Quality
- quality improvements on process, data, services, user experiences, settlements metrics
Gartner - 3 key AI benefits
https://www.gartner.com/smarterwithgartner/top-3-benefits-of-ai-projects/

Common ML Engineering Foundations Course - free
https://end-to-end-machine-learning.teachable.com/p/000-foundational-skills
sign up - jm9y
https://end-to-end-machine-learning.teachable.com/
- Preview011. Python
- Preview012. NumPy resources
- Preview ----- ( Really ??? substitute Groovy instead of C++ )016. C++
- Preview021. SQL
- Preview031. Calculus
- Preview032. Linear Algebra
- Preview041. Statistics
- Preview071. Git and GitHub
- Preview091. Mental Focus
Data Science Concepts Course - Free
https://end-to-end-machine-learning.teachable.com/p/data-science-concepts
- PreviewHow data science works
- PreviewThere is more to data science than machine learning
- PreviewHow to get good quality data
- PreviewWhat questions can machine learning answer
- PreviewHow to find the right machine learning algorithm
Common ML Scientist Skill Sets
A great candidate for Customer Data Scientist/Sales Engineer should:
- Know Python, R, Java, Scala, Spark.
- Have experience with Big Data including Hadoop, Spark, Kafka.
- Have a working knowledge of ML algorithms for Regression and Classification problems.
- Understanding of Supervised, Unsupervised, Deep learning techniques
- Knowledge of XGBoost, Linear regression, GBM, GLM, LightGBM, Random Forest and other common ML algorithms
- Experience using TensorFlow, Keras, Scikit libraries for performing ML .
ML Algorithm Tuning Concepts
These algorithms automatically adjust (learn) their internal parameters based on data. However, there is a subset of parameters that is not learned and that have to be configured by an expert. Such parameters are often referred to as “hyperparameters” — and they have a big impact on our lives as the use of AI increases.
For example, the tree depth in a decision tree model and the number of layers in an artificial neural network are typical hyperparameters. The performance of a model can drastically depend on the choice of its hyperparameters. A decision tree can yield good results for moderate tree depth and have very bad performance for very deep trees.
The choice of the optimal hyperparameters is more art than science, if we want to run it manually. Indeed, the optimal selection of the hyperparameter values depends on the problem at hand.
Since the algorithms, the goals, the data types, and the data volumes change considerably from one project to another, there is no single best choice for hyperparameter values that fits all models and all problems. Instead, hyperparameters must be optimized within the context of each machine learning project.
In this article, we’ll start with a review of the power of an optimization strategy and then provide an overview of four commonly used optimization strategies:
- Grid search
- Random search
- Hill climbing
- Bayesian optimization
Optimizing ML model parameters
A typical optimization procedure defines the possible set of hyperparameters and the metric to be maximized or minimized for that particular problem. Hence, in practice, any optimization procedure follows these classical steps:
- 1) Split the data at hand into training and test subsets
- 2) Repeat optimization loop a fixed number of times or until a condition is met:
- a) Select a new set of model hyperparameters
- b) Train the model on the training subset using the selected set of hyperparameters
- c) Apply the model to the test subset and generate the corresponding predictions
- d) Evaluate the test predictions using the appropriate scoring metric for the problem at hand, such as accuracy or mean absolute error. Store the metric value that corresponds to the selected set of hyperparameters
- 3) Compare all metric values and choose the hyperparameter set that yields the best metric value
The question is how to pass from step 2d back to step 2a for the next iteration; that is, how to select the next set of hyperparameters, making sure that it is actually better than the previous set. We would like our optimization loop to move toward a reasonably good solution, even though it may not be the optimal one. In other words, we want to be reasonably sure that the next set of hyperparameters is an improvement over the previous one.
A typical optimization procedure treats a machine learning model as a black box. That means at each iteration for each selected set of hyperparameters, all we are interested in is the model performance as measured by the selected metric. We do not need (want) to know what kind of magic happens inside the black box. We just need to move to the next iteration and iterate over the next performance evaluation, and so on.
The key factor in all different optimization strategies is how to select the next set of hyperparameter values in step 2a, depending on the previous metric outputs in step 2d. Therefore, for a simplified experiment, we omit the training and testing of the black box, and we focus on the metric calculation (a mathematical function) and the strategy to select the next set of hyperparameters. In addition, we have substituted the metric calculation with an arbitrary mathematical function and the set of model hyperparameters with the function parameters.
In this way, the optimization loop runs faster and remains as general as possible. One further simplification is to use a function with only one hyperparameter to allow for an easy visualization. Below is the function we used to demonstrate the four optimization strategies. We would like to emphasize that any other mathematical function would have worked as well.
Bayesian optimization
The Bayesian optimization strategy selects the next hyperparameter value based on the function outputs in the previous iterations, similar to the hill climbing strategy. Unlike hill climbing, Bayesian optimization looks at past iterations globally and not only at the last one.
There are typically two phases in this procedure:
- During the first phase, called warm-up, hyperparameter values are generated randomly. After a user-defined number N of such random generations of hyperparameters, the second phase kicks in.
- In the second phase, at each iteration, a “surrogate” model of type P(output | past hyperparameters) is estimated to describe the conditional probability of the output values on the hyperparameter values from past iterations. This surrogate model is much easier to optimize than the original function. Thus, the algorithm optimizes the surrogate and suggests the hyperparameter values at the maximum of the surrogate model as the optimal values for the original function as well. A fraction of the iterations in the second phase is also used to probe areas outside of the optimal region. This is to avoid the problem of local maxima.
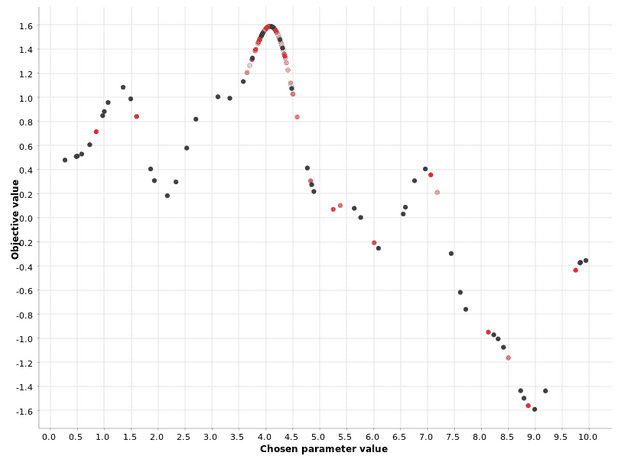 Figure 4: Bayesian optimization of the hyperparameter values on a [0, 10] range. The color gradient reflects the position in the generated sequence of hyperparameter candidates. Whiter points correspond to hyperparameter values generated earlier on in the process; red points correspond to hyperparameter values generated later on. The gray points are generated in the first random phase of the strategy.Figure 4 demonstrates that the Bayesian optimization strategy uses the warm-up phase to define the most promising area and then selects the next values for the hyperparameters in that area.
Figure 4: Bayesian optimization of the hyperparameter values on a [0, 10] range. The color gradient reflects the position in the generated sequence of hyperparameter candidates. Whiter points correspond to hyperparameter values generated earlier on in the process; red points correspond to hyperparameter values generated later on. The gray points are generated in the first random phase of the strategy.Figure 4 demonstrates that the Bayesian optimization strategy uses the warm-up phase to define the most promising area and then selects the next values for the hyperparameters in that area.
You can also see that intense red points are clustered closer to the maximum, while pale red and white points are scattered. This demonstrates that the definition of the optimal region is improved with each iteration of the second phase.
Summary
We all know the importance of hyperparameter optimization while training a machine learning model. Since manual optimization is time-consuming and requires specific expert knowledge, we have explored four common automatic procedures for hyperparameter optimization.
In general, an automatic optimization procedure follows an iterative procedure in which at each iteration, the model is trained on a new set of hyperparameters and evaluated on the test set. At the end, the hyperparameter set corresponding to the best metric score is chosen as the optimal set. The question is how to select the next set of hyperparameters, ensuring that this is actually better than the previous set.
We have provided an overview of four commonly used optimization strategies: grid search, random search, hill climbing, and Bayesian optimization. They all have pros and cons, and we have briefly explained the differences by illustrating how they work on a simple toy use case. Now you are all set to go and try them out in a real-world machine learning problem.
Tensorflow -
TensorFlow is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications
The core open source library to help you develop and train ML models. Get started quickly by running Colab notebooks directly in your browser.
For Java
For Javascript
https://www.tensorflow.org/js/
TensorFlow.js is a JavaScript library for training and deploying models in the browser and on Node.js.
Develop ML models in JavaScript, and use ML directly in the browser or in Node.js.
Run existing models
Use off-the-shelf JavaScript models or convert Python TensorFlow models to run in the browser or under Node.js.
Use official TensorFlow.js models
Convert Python models
Retrain existing models
Retrain pre-existing ML models using your own data.
Use Transfer Learning to customize models
Develop ML with JavaScript
Build and train models directly in JavaScript using flexible and intuitive APIs.
Get started with TensorFlow.js
Tensorflow Tutorials
https://www.tensorflow.org/tutorials
The TensorFlow tutorials are written as Jupyter notebooks and run directly in Google Colab—a hosted notebook environment that requires no setup. Click the Run in Google Colab button.
The best place to start is with the user-friendly Keras sequential API. Build models by plugging together building blocks. After these tutorials, read the Keras guide.
Beginner quickstart
This "Hello, World!" notebook shows the Keras Sequential API and model.fit.
Keras basics
This notebook collection demonstrates basic machine learning tasks using Keras.
Load data
These tutorials use tf.data to load various data formats and build input pipelines.
More
The Keras functional and subclassing APIs provide a define-by-run interface for customization and advanced research. Build your model, then write the forward and backward pass. Create custom layers, activations, and training loops.
Many Libraries and Extensions available free
Explore libraries to build advanced models or methods using TensorFlow, and access domain-specific application packages that extend TensorFlow. This is a sample of the tutorials available for these projects.
Keras - Python Deep Learning Library
Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result with the least possible delay is key to doing good research.
Use Keras if you need a deep learning library that:
- Allows for easy and fast prototyping (through user friendliness, modularity, and extensibility).
- Supports both convolutional networks and recurrent networks, as well as combinations of the two.
- Runs seamlessly on CPU and GPU.
Read the documentation at Keras.io.
Keras is compatible with: Python 2.7-3.6.
Guiding principles
User friendliness. Keras is an API designed for human beings, not machines. It puts user experience front and center. Keras follows best practices for reducing cognitive load: it offers consistent & simple APIs, it minimizes the number of user actions required for common use cases, and it provides clear and actionable feedback upon user error.
Modularity. A model is understood as a sequence or a graph of standalone, fully configurable modules that can be plugged together with as few restrictions as possible. In particular, neural layers, cost functions, optimizers, initialization schemes, activation functions and regularization schemes are all standalone modules that you can combine to create new models.
Easy extensibility. New modules are simple to add (as new classes and functions), and existing modules provide ample examples. To be able to easily create new modules allows for total expressiveness, making Keras suitable for advanced research.
Work with Python. No separate models configuration files in a declarative format. Models are described in Python code, which is compact, easier to debug, and allows for ease of extensibility.
Getting started: 30 seconds to Keras
The core data structure of Keras is a model, a way to organize layers. The simplest type of model is the Sequential model, a linear stack of layers. For more complex architectures, you should use the Keras functional API, which allows to build arbitrary graphs of layers.
Here is the Sequential model:
from keras.models import Sequential
model = Sequential()
Stacking layers is as easy as .add():
from keras.layers import Dense
model.add(Dense(units=64, activation='relu', input_dim=100))
model.add(Dense(units=10, activation='softmax'))
Once your model looks good, configure its learning process with .compile():
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
If you need to, you can further configure your optimizer. A core principle of Keras is to make things reasonably simple, while allowing the user to be fully in control when they need to (the ultimate control being the easy extensibility of the source code).
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.SGD(lr=0.01, momentum=0.9, nesterov=True))
You can now iterate on your training data in batches:
# x_train and y_train are Numpy arrays --just like in the Scikit-Learn API.
model.fit(x_train, y_train, epochs=5, batch_size=32)
Alternatively, you can feed batches to your model manually:
model.train_on_batch(x_batch, y_batch)
Evaluate your performance in one line:
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=128)
Or generate predictions on new data:
classes = model.predict(x_test, batch_size=128)
Building a question answering system, an image classification model, a Neural Turing Machine, or any other model is just as fast. The ideas behind deep learning are simple, so why should their implementation be painful?
For a more in-depth tutorial about Keras, you can check out:
In the examples folder of the repository, you will find more advanced models: question-answering with memory networks, text generation with stacked LSTMs, etc.
Installation
Before installing Keras, please install one of its backend engines: TensorFlow, Theano, or CNTK. We recommend the TensorFlow backend.
- TensorFlow installation instructions.
- Theano installation instructions.
- CNTK installation instructions.
You may also consider installing the following optional dependencies:
- cuDNN (recommended if you plan on running Keras on GPU).
- HDF5 and h5py (required if you plan on saving Keras models to disk).
- graphviz and pydot (used by visualization utilities to plot model graphs).
Then, you can install Keras itself. There are two ways to install Keras:
- Install Keras from PyPI (recommended):
sudo pip install keras
If you are using a virtualenv, you may want to avoid using sudo:
pip install keras
- Alternatively: install Keras from the GitHub source:
First, clone Keras using git:
git clone https://github.com/keras-team/keras.git
Then, cd to the Keras folder and run the install command:
cd keras
sudo python setup.py install
Configuring your Keras back end
By default, Keras will use TensorFlow as its tensor manipulation library. Follow these instructions to configure the Keras backend.
Support
You can ask questions and join the development discussion:
- On the Keras Google group.
- On the Keras Slack channel. Use this link to request an invitation to the channel.
You can also post bug reports and feature requests (only) in GitHub issues. Make sure to read our guidelines first.
AI solution devops concepts
Containers make operation and management of AI solutions safer, easier
article - Benefits-of-containers-for-AI-workloads
The benefits of containerization for AI development include dependency management, environment consistency, scaling, resource consumption efficiency, isolation, reproducibility, security, latency control, versioning and cost management.
1. Dependency management and app segregation
2. Consistent environment
3. Scalability with Kubernetes
4. Resource efficiency compared to pure VMs w lower platform lockin
5. Isolation - reasonably well
6. Security - over apps in shared server
7. Latency with separate services for independent scaling with limited overhead
8. Version control w separation of app instances for different configurations
9. Reproducibility with snapshots of the container environment as needed
10. Reduced staff costs - maybe
Containers integrate well with CI/CD pipelines, facilitating automated testing and deployment. With less manual intervention from development to deployment, human errors should be decreased. These aspects reduce potential expenses related to bug fixes and downtime.
Kubernetes provides common management for AI solutions across environments and platforms
Kubeflow
The Machine Learning Toolkit for Kubernetes
https://www.kubeflow.org/docs/about/kubeflow/
The Kubeflow project is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. Our goal is not to recreate other services, but to provide a straightforward way to deploy best-of-breed open-source systems for ML to diverse infrastructures. Anywhere you are running Kubernetes, you should be able to run Kubeflow.
Getting started with Kubeflow
Read the Kubeflow overview for an introduction to the Kubeflow architecture and to see how you can use Kubeflow to manage your ML workflow.
Follow the getting-started guide to set up your environment and install Kubeflow.
What is Kubeflow?
Kubeflow is the machine learning toolkit for Kubernetes. Learn about Kubeflow use cases.
To use Kubeflow, the basic workflow is:
Download and run the Kubeflow deployment binary.
Customize the resulting configuration files.
Run the specified script to deploy your containers to your specific environment.
You can adapt the configuration to choose the platforms and services that you want to use for each stage of the ML workflow: data preparation, model training, prediction serving, and service management.
You can choose to deploy your Kubernetes workloads locally, on-premises, or to a cloud environment.
Read the Kubeflow overview for more details.
The Kubeflow mission
Our goal is to make scaling machine learning (ML) models and deploying them to production as simple as possible, by letting Kubernetes do what it’s great at:
Easy, repeatable, portable deployments on a diverse infrastructure (for example, experimenting on a laptop, then moving to an on-premises cluster or to the cloud)
Deploying and managing loosely-coupled microservices
Scaling based on demand
Because ML practitioners use a diverse set of tools, one of the key goals is to customize the stack based on user requirements (within reason) and let the system take care of the “boring stuff”. While we have started with a narrow set of technologies, we are working with many different projects to include additional tooling.
Ultimately, we want to have a set of simple manifests that give you an easy to use ML stack anywhere Kubernetes is already running, and that can self configure based on the cluster it deploys into.
History
Kubeflow started as an open sourcing of the way Google ran TensorFlow internally, based on a pipeline called TensorFlow Extended. It began as just a simpler way to run TensorFlow jobs on Kubernetes, but has since expanded to be a multi-architecture, multi-cloud framework for running entire machine learning pipelines.
Roadmaps
To see what’s coming up in future versions of Kubeflow, refer to the Kubeflow roadmap.
The following components also have roadmaps:
Arena
Fairing
Kubeflow Pipelines
KF Serving
Katib
MPI Operator
Components of Kubeflow
https://www.kubeflow.org/docs/components/
Logical components that make up Kubeflow
Central Dashboard
The central user interface (UI) in Kubeflow
Metadata
Tracking and managing metadata of machine learning workflows in Kubeflow
Jupyter Notebooks
Using Jupyter notebooks in Kubeflow
Frameworks for Training
Training of ML models in Kubeflow
Hyperparameter Tuning
Hyperparameter tuning of ML models in Kubeflow
Pipelines
ML Pipelines in Kubeflow
Tools for Serving
Serving of ML models in Kubeflow
Multi-Tenancy in Kubeflow
Multi-user isolation and identity access management (IAM)
Miscellaneous
Miscellaneous Kubeflow components
How to get started using Kubeflow.
https://www.kubeflow.org/docs/started/
How to get started using Kubeflow.
Kubeflow Overview
How Kubeflow helps you organize your ML workflow
Installing Kubeflow
Overview of installation choices for various environments
Cloud Installation
Instructions for installing Kubeflow on a public cloud
Kubernetes Installation
Instructions for installing Kubeflow on an existing Kubernetes cluster
Workstation Installation
Instructions for installing Kubeflow on a workstation or server
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment.
PyTorch enables fast, flexible experimentation and efficient production through a user-friendly front-end, distributed training, and ecosystem of tools and libraries.
pre-reqs
Python
Juptyer notebooks ???
Data Sources
TorchScript
With TorchScript, PyTorch provides ease-of-use and flexibility in eager mode, while seamlessly transitioning to graph mode for speed, optimization, and functionality in C++ runtime environments.
my_script_module.save("my_script_module.pt")
TorchScript
With TorchScript, PyTorch provides ease-of-use and flexibility in eager mode, while seamlessly transitioning to graph mode for speed, optimization, and functionality in C++ runtime environments.
Distributed Training
Optimize performance in both research and production by taking advantage of native support for asynchronous execution of collective operations and peer-to-peer communication that is accessible from Python and C++.
Mobile (Experimental)
PyTorch supports an end-to-end workflow from Python to deployment on iOS and Android. It extends the PyTorch API to cover common preprocessing and integration tasks needed for incorporating ML in mobile applications.
Tools & Libraries
An active community of researchers and developers have built a rich ecosystem of tools and libraries for extending PyTorch and supporting development in areas from computer vision to reinforcement learning.
Native ONNX Support
Export models in the standard ONNX (Open Neural Network Exchange) format for direct access to ONNX-compatible platforms, runtimes, visualizers, and more.
Cloud Partners
PyTorch is well supported on major cloud platforms, providing frictionless development and easy scaling through prebuilt images, large scale training on GPUs, ability to run models in a production scale environment, and more.
PyTorch Tutorials
https://pytorch.org/tutorials/
To learn how to use PyTorch, begin with our Getting Started Tutorials. The 60-minute blitz is the most common starting point, and provides a broad view into how to use PyTorch from the basics all the way into constructing deep neural networks.
Some considerations:
We’ve added a new feature to tutorials that allows users to open the notebook associated with a tutorial in Google Colab. Visit this page for more information.
If you would like to do the tutorials interactively via IPython / Jupyter, each tutorial has a download link for a Jupyter Notebook and Python source code.
Additional high-quality examples are available, including image classification, unsupervised learning, reinforcement learning, machine translation, and many other applications, in PyTorch Examples.
You can find reference documentation for the PyTorch API and layers in PyTorch Docs or via inline help.
If you would like the tutorials section improved, please open a github issue here with your feedback.
Check out our PyTorch Cheat Sheet for additional useful information.
Finally, here’s a link to the PyTorch Release Notes
Cloudera ML Workbench Course Overview
https://university.cloudera.com/instructor-led-training/cloudera-data-scientist-training
$3200 for 4 days online
The workshop includes brief lectures, interactive demonstrations, hands-on exercises, and discussions covering topics including:
• Overview of data science and machine learning at scale
• Overview of the Hadoop ecosystem
• Working with HDFS data and Hive tables using Hue
• Introduction to Cloudera Data Science Workbench
• Overview of Apache Spark 2
• Reading and writing data
• Inspecting data quality
• Cleansing and transforming data
• Summarizing and grouping data
• Combining, splitting, and reshaping data
• Exploring data
• Configuring, monitoring, and troubleshooting Spark applications
• Overview of machine learning in Spark MLlib
• Extracting, transforming, and selecting features
• Building and evaluating regression models
• Building and evaluating classification models
• Building and evaluating clustering models
• Cross-validating models and tuning hyperparameters
• Building machine learning pipelines
• Deploying machine learning models
Technologies
Participants gain practical skills and hands-on experience with data science tools including:
• Spark, Spark SQL, and Spark MLlib
• PySpark and sparklyr
• Cloudera Data Science Workbench (CDSW)
• Hue
Prerequisites
Workshop participants should have a basic understanding of Python or R and some experience exploring and analyzing data and developing statistical or machine learning models. Knowledge of Hadoop or Spark is not required.
AIAAS - MLAAS - ML Services
Smart Assistant Services Agents ( SASA ) - provide real-time or batch decision analysis
DMX used car pricing assistant
Carbon Offset trading assistant - Optional AMM feature
Hyper.now example MLAAS
HyperIntelligence is a proprietary analytics technology offered by MicroStrategy that enables users to consume contextual data and analytics within the websites, emails, enterprise applications, and web-based tools leveraged throughout their standard business workflows. This technology allows users to augment their workflows with relevant insights and one-click actions delivered via HyperIntelligence cards, which function as micro-dashboards that are automatically generated to convey relevant data and analytics associated with defined keyword attributes.
When such attribute(s) that you identify as keywords appear in context as supported by the HyperIntelligence product, the keyword triggers the associated card(s) to appear. The context in which HyperIntelligence cards may appear when triggered by defined keywords includes:
- Within web-based content such as emails, websites, applications, or other browser-accessible instances;
- Within emails, websites, or web applications;
- Within Microsoft Office web-based applications such as Microsoft Excel; and
- As notifications populated on Apple and Android mobile devices.
The contextual capabilities offered by Hyper.Now are comparable to the capabilities offered by the associated HyperIntelligence products offered in the enterprise MicroStrategy product catalog.
Generative Ai and Large Language Model Concepts
compact-guide-to-large-language-models.pdf 2024 - Databricks link
llm-compact-guide-to-large-language-models-databricks-2024.pdf file
some quotes from the guide >>
ChatGPT provides a nice user interface (or API) where users can feed prompts to one of many models (GPT-3.5, GPT-4, and more) and typically get a fast response. These are among the highest-performing models, trained on enormous data sets, and are capable of extremely complex tasks both from a technical standpoint, such as code generation, as well as from a creative perspective like writing poetry in a specific style.
open-source LLMs
Communities like Hugging Face gather hundreds of thousands of models from contributors that can help solve tons of specific use cases such as text generation, summarization and classification.
Databricks enhances MLFlow for specific use cases
On Databricks, for example, we’ve made improvements to open source frameworks like MLflow to make it very easy for someone with a bit of Python experience to pull any Hugging Face transformer model and use it as a Python object. Oftentimes, you can find an open source model that solves your specific problem that is orders of magnitude smaller than ChatGPT, allowing you to bring the model into your environment and host it yourself. This means that you can keep the data in your control for privacy and governance concerns as well as manage your costs
Smaller open-source LLMs target specific use cases with specific, private data
Another huge upside to using open source models is the ability to fine-tune them to your own data. Since you’re not dealing with a black box of a proprietary service, there are techniques that let you take open source models and train them to your specific data, greatly improving their performance on your specific domain. We believe the future of language models is going to move in this direction, as more and more organizations will want full control and understanding of their LLMs
Larger LLMs are adding options to target specific private data sets but their strength is the larger training data sets
LLM AI Security & Governance Checklist-owasp.pdf. link
LLM AI Security & Governance Checklist-owasp.pdf. file
LLMs_in_Production_v2.pdf. link book 2024
compact-guide-to-large-language-models.pdf
More on Gen AI and LLM resources
Open LLMs: Llama, Claude and more
Governance and Ethical AI
HBR Practical Guide to Building Ethical AI - 2020
https://hbr.org/2020/10/a-practical-guide-to-building-ethical-ai
Practical Guide to Building Ethical AI ** HBR pdf
WEForum.org - ensure AI is ethical - 8 tips
https://www.weforum.org/agenda/2020/01/8-ways-to-ensure-your-companys-ai-is-ethical/
Why Govern AI ? Risk Management
“Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.” The Center for AI Safety published this single statement as an open letter on May 30, 2023.
OWASP and AI Governance of LLM ( current technology )
LLM AI Security & Governance Checklist-owasp.pdf. link
LLM AI Security & Governance Checklist-owasp.pdf. file
Good Governance for AI - What does that Look Like?
Why can’t you trust AI?
Good Governance is missing
What does good governance for AI look like?
Independent Proof of Governance ( Sybal )
What does Independent Proof of Governance deliver for AI?
Automated, Accurate Verification of the entire AI process ensuring compliance within defined guardrails
From the domain and problem specification, to the models, the training data, the tuning, the input data, execution and output, the entire process needs verification to ensure compliance within the defined guardrails
Proposed Principles for Responsible AI
Advice not actions for many use cases
Transparent
Explainable
Traceable
Accurate
Controlled
Governed
Accountable
Fair
Reliable
Private
Inclusive
Secure
Valuable
Safe - Risk management
Cost-effective
Accessible
Vipin Bharathan on Proposed AI Guardrails Framework - Forbes
The architecture of an emerging startup, Modguard, in the accompanying diagram, gives us a path towards compliance with these laws

EU AI Regulations
WEF review of EU AI regs
https://www.weforum.org/agenda/2023/06/european-union-ai-act-explained/
EU Overview of proposed EU AI Regulations
https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai
EU Proposed AI Regulations - June 2023
Covers
Concepts, Needs, Responsible Parties, Responsibitles, Use Cases, Rights, Proposed Regulations and more
EY - EU AI Act and what it means for your business
https://www.ey.com/en_ch/forensic-integrity-services/the-eu-ai-act-what-it-means-for-your-business
- The EU AI Act brings strict requirements, also for organizations which have not had to deal with model management until now.
- As a first step, organizations should gain an overview, build a repository of all models and implement a model management.
- Even though regulation is not final, it is clearly on the horizon and time should be used to prepare.
Brookings report - EU and US Diverge on AI Regulation - April 2023
- Executive summary
- Introduction
- The U.S. approach to AI risk management
- The EU approach to AI risk management
- Contrasting the EU and U.S. approaches to AI risk management
- EU-U.S. collaboration on AI risk through the trade and technology council
- Emerging challenges in transatlantic AI risk management
- Policy recommendations
G7 Survey on Guiding Principles for Generative AI - Oct 2023
News release on EU AI Regulation Act
US Approach to Responsible AI
Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence
Purpose
Policies and Principles includes many social goals
Definitions with instructions on establishing guidelines for Responsible AI
Secretary of Commerce has a lead role in defining rules for AI model and service management
" The Secretary of Commerce, in consultation with the Secretary of State, the Secretary of Defense, the Secretary of Energy, and the Director of National Intelligence, shall define,"
Assignments > Objectives with normal time limits less than 1 year for reporting on impacts, goals, strategies by agency
Identifies responsibity concepts for businesses in building, using AI in commerce
Fact Sheet on Executive Order for Responsible AI
New Standards for AI Safety and Security
developers of the most powerful AI systems share their safety test results and other critical information with the U.S. government
standards, tools, and tests to help ensure that AI systems are safe, secure, and trustworthy
Protect against risks to people, organizations, ecosystems, systems
Reduce fraud, deception, misinformation
Protect Privacy and Rights
Promote Innovation
Promote American Leadership ( or better partnerships ?? )
Effective governance for Responsible AI
NIST Proposed AI Risk Mgt Framework
https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf
AI Notes including Governance
AI-notes1 gdoc
DeepSeek R1 - LLM - 2025 - notes
DeepSeek’s R1, the new Chinese large-language model that’s more powerful and incurred 95% less development costs than its American competitors, is the best thing to happen to artificial intelligence in a decade
flaws in framing this with Cold War-era militarist logic. << a problem since BOTH sides do this now and common governance is the only real solution to mistrust
previous Trump Administration’s hostility led Beijing to double-down on developing strategically important technologies. << probably was on their roadmap anyway
difficult to keep these ideas locked down when they are constantly being shared << yes technology advantages have a short life
Potential Value Opportunities
RedPoint Global concepts to deliver business results from ML
When paired with a persistent, real-time, single customer record, AI and automated machine learning platforms can be utilized to meet those business goals, increase revenue and fundamentally change the way brands communication with customers.
Data Point No. 1: Machine learning should drive revenue.
The ultimate goal of machine learning shouldn’t be a flashy, futuristic example but instead a system to drive revenue and results for the business. The result of effective machine learning isn’t likely a robot, chatbot or facial recognition tool –
it’s machine learning-driven programs that are embedded behind the scenes, driving intelligent decisions for optimized customer engagement.
Data Point No. 2: Having one model–or even many–is not enough.
Organizations need many models running and working in real time to truly make machine learning work for their needs. For future-forward organizations, intelligence and analysis needs to be embedded, so instead of using one model, multiple in-line analytic models can incrementally adjust and find opportunities for growth. These fleets of ML models can optimize business functions and drive associated revenues.
Data Point No. 3: When applied in silos, machine learning is not as effective.
Today’s consumer is omnichannel. Businesses must forego the traditional channel-specific “batch and blast” approach that sufficed when customer choice was limited and the buying journey followed a mostly straight-line path. Today’s customer journey is dynamic, and the learning applied to the customer relationship should be, as well. Machine learning is particularly well-suited to solving these multidimensional problems.
Data Point No. 4: Analytics are only intelligent when models are up to date.
News flash: Machine-learning models age and can quickly become stale. For this reason, organizations must consistently rebuild and retrain models using today’s data. In fact, models should be developed, updated and even applied in real-time on an ongoing testing basis so that businesses can truly capitalize on the moment of interaction. This is most effective in a closed loop system that continually looks for incremental changes to optimize.
Data Point No. 5: You don’t need to be a data scientist to benefit from machine learning.
When models are configured correctly, they will run 24/7 looking for opportunities within the data, set up and managed by marketers. These systems can be set once and guided to produce the specific business metrics needed. With every record tracked in the system, insights are pulled easily, and the recommendations can be made automatically. Businesses should focus on producing continually updated data and let the automation tools use machine learning to drive greater revenue.
Data Point No. 6: Summary: The power is in your hands.
Machine learning has the power to fully transform an enterprise. Therefore, it’s natural for business leaders to get lost in the hype and lose sight of the real value it can deliver day-to-day. The truth is, the real value of machine learning is that it allows businesses to try new things, amplify creative strengths, reveal new discoveries and enable collaboration across the organization. However, these benefits will only be realized once organizations get past the hype and are willing to walk into the weeds.
Practical DS / ML Solutions
Recommender Systems
Recommender systems, also known as recommender engines, are one of the mostwell-known applications of data science. Recommender systems are a subclass ofinformation filtering systems, systems that cut through the noise of all options andpresent users with just the subset of options they’ll find appealing. The data beingfiltered can range from products on an e-commerce site to dating matches thatappear as you search for ‘the one.’Recommender systems offer a more intelligent approach to information filteringthan a simple search algorithm by introducing users to items they might not haveotherwise discovered. Recommender systems generally take either a collaborativeor content-based approach to filtering. Collaborative filtering considers a user’sprevious behavior, as well as the behavior of similar users. Content-based filteringprovides recommendations based on discrete attributes or assigned characteristics.
WHAT IS A RECOMMENDER SYSTEM?
A model that filters information to present users with a curated subset of options they’re likely to find appealing
HOW DOES IT WORK?Generally via a collaborative approach (considering user’s previous behavior) or content based approach (based on discrete assigned characteristics)
WHAT IS A REAL USE CASE?Tendril uses recommendation models to match eligible customers with new or existing energy products
Credit or Risk Scoring
If you have ever applied for a credit card or a loan, you’re likely already familiar with the concept of credit scoring. What you may be less aware of is the set of decision management rules evaluating how likely an applicant is to repay debts behind the scenes.
WHAT IS CREDIT SCORING?A model that determines an applicant’s creditworthiness for a mortgage, loan or credit card
HOW DOES IT WORK?A set of decision management rules evaluates how likely anapplicant is to repay debts
WHAT IS A REAL USE CASE?A financial services company uses machine learning models to reachprospective customers that may have been overlooked bytraditional banking institutions
We developed complex statistical and machine learning models to enable smarter lending decisions,” explains the Director of Business Lending . “By getting creative with ourapproach and adopting innovative technologies, we’ve been able to reinvent how both consumers and businesses obtain loans. This has allowed us to reachprospective customers that in the past may have been overlooked by traditionalbanking institutions.”
Dynamic Pricing ( ?? see Robinson-Patman Act - see airline seat pricing )
Businesses use dynamic pricing algorithms to model rates as a function of supply,demand, competitor pricing, and exogenous factors (e.g. weather or time). Many fields, from airline travel to athletics admission ticketing, employ dynamic pricingto maximize expected revenue. The nuts and bolts of dynamic pricing strategiesvary widely, though generalized linear models and classification trees are populartechniques for estimating the “right” (lowest/highest) price that consumers arewilling to pay for a book, a flight, or a cab
WHAT IS DYNAMIC PRICING?Modeling price as a function of supply, demand, competitor pricingand exogenous factors
HOW DOES IT WORK?Generalized linear models and classification trees arepopular techniques for estimating the “right” price to maximizeexpected revenue
WHAT IS A REAL USE CASE?A car sharing company uses dynamic pricing models to suggest prices to the peoplewho list and rent out cars
Customer Churn
Churn rate describes the rate at which customers abandon a product or service.Understanding customers’ likelihood to churn is particularly important forsubscription-based models; everything ranging from traditional cable or gymmemberships to recently popularized monthly subscription boxes.Data scientists looking to predict customer churn may consider a variety of algorithmsfor the job, such as support vector machines, random forest, or k-nearest-neighbors.Beyond the accuracy of a given model, data scientists must also balance the tradeoffbetween precision (correctly predicting a churning customer) and recall (how manypredictions were actually successful). So what’s better? Classifying every churningcustomer but occasionally mislabeling a non-churning customer? Or identifying fewerchurning customers, but not mislabeling non-churners? It’s a difficult decision thatrequires in-depth knowledge of the business case and years of experience.
WHAT IS CUSTOMER CHURN?Predicting which customers are going to abandon a product or service
HOW DOES IT WORK?Data scientists may consider using support vector machines, random forest or k-nearest-neighbors algorithms
WHAT IS A REAL USE CASE?EAB combines data from transcripts, standardized test scores, demographics and more to identify students at risk of not graduating
Fraud Detection
Financial technology, or ‘FinTech,’ companies offer financial services like banking, investing, and payment processing via software, rather than through traditional banking institutions. Companies processing massive volumes of financial transactions also need a quantifiable way to detect and prevent fraudulent transactions from being processed.
WHAT IS FRAUD DETECTION?Detecting and preventing fraudulent financial transactions from being processed
HOW DOES IT WORK?Fraud detection is a binary classification problem: “is this transaction legitimate or not?”
WHAT IS A REAL USE CASE?Via SMS Group uses a combination of complex data lookups and decision algorithms written in R and implemented in PHP to assess whether a loan applicant is fraudulent
AI Solution Architecture Models
One of the most important skills for people in AI is being able to architect solutions for companies. This one-pager covers everything you need.
- Custom AI:
At the bottom, you have the ML platforms, data analytics, and data governance, that allows Data Scientists and Data Engineers to create custom AI solutions.
- General AI Services:
The Cognitive Services help you build AI applications by calling APIs. They include generalistic solutions for computer vision, language, speech, and the Azure OpenAI Service.
- Applied AI Services:
On top, we have specific AI solutions like Cognitive Search or Form Recognizer. They are niche applications for Software Developers.
- No code AI:
See Google Cloud for No code AI
The Power Platform helps any person build AI applications. If you can operate PowerPoint and Excel, you can operate the solutions in the Power Platform.
- Industry applications:
Apart from generalistic solutions, there are vertical solutions specialized in industries. Healthcare, agriculture, marketing, etc.
- Open source:
There is a large suite of open-source libraries that help AI engineers and software developers to build AI: PyTorch, ONNX, LightGBM, Recommenders, SynapseML, DeepSpeed, etc.
This is Microsoft cloud business in one page and involves tens of thousands of people serving customers.
Designed by Adrián González Sánchez

Potential Challenges
CX is now multi-channel contact points direct and indirect to an organization creating data integration, validation challenges
Need highly engaged, customized user interfaces by user channels of choice ( eg text here, voice there, docs there etc )
Sometimes batch but more often real-time information and decision making support needed in user interactions
Predictions
AI will decide to improve by reinventing its form as organic beings automating growth, nutrition, with faster and more complex processing modes
ML and AI Governance
Trusted ML apps with ZKP - Daniel Szego
Tokenized Zero Knowledge Machine Learning and Its Applications-Daniel-Szego-2024.pdf. link
Tokenized Zero Knowledge Machine Learning and Its Applications-Daniel-Szego-2024.pdf. file
Hi Daniel,
Thanks for your article and demo on Tokenized Zero Knowledge ML apps. Really clear, well done. I didn't connect a wallet but did run the simple online tests.
Can I interest you in doing a 1 hour presentation to the Hyperledger Meetup and Public Sector groups on your article? I think it's really important for the community. I lead the Boston and Public Sector groups.
Thanks
Jim
Candidate Solutions
Google Foundation Models based on PALM2 FOR AI solutions
Therefore, foundation models foster the competitive moats around the major CSPs' cloud services aimed at AI innovation, with smaller organizations dependent on these models to form the base of their own innovations. For cloud providers, the goal is to offer numerous, versatile foundation models, accompanied by comprehensive software stacks and development tools, that can be applied to a wide range of use cases across industries, subsequently generating more diversified revenue.
Google Cloud is advancing aggressively in offering a comprehensive suite of foundation models within its Vertex AI platform to serve various end use cases. Google's main foundation model currently is PaLM 2, a large language model with advanced capabilities such as multilingualism and reasoning.
Large language models offer a wide range of use cases, of which the most prominently discussed is the development of intelligent chatbots and virtual assistants that can understand and respond to user queries more seamlessly.
Though as large language models become more advanced, their applicability also advances. As generative AI becomes increasingly utilized in various industries, new products and services will arise. Consequently, new data sources are generated, enabling enterprises to retrain their models. With companies continuously refining their AI-based offerings, a growing array of data is generated, which steadily escalates the training workloads for enhancing these models. Consequently, the demand for computational power will persistently increase over time as enterprises frequently retrain and optimize models using larger datasets. The continuous need for training/ inferencing means sustained demand for Google Cloud's computing power, conducive to recurring revenue over the long-term.
In fact, Google also introduced specialized versions of its PaLM 2 large language model in May 2023, including Sec-PaLM, which is aimed at cybersecurity analysis, and Med-PaLM 2, focused on answering medical questions. Google is exploring ways for Med-PaLM 2 to be used by healthcare experts to "find insights in complicated and unstructured medical texts… help draft short- and long-form responses and summarize documentation and insights from internal data sets and bodies of scientific knowledge". Google's Med-PaLM 2 advances the company's push into the healthcare industry.
AI Tools List - 2023
https://boardofinnovation.notion.site/AI-Tools-for-Innovators-7a80ab30bcfd4a15846436aa347d5af2

Site for more AI tools
https://theresanaiforthat.com/
No Code AI Solutions, Tools
Google AppSheets
https://www.youtube.com/watch?v=MlJX0X9qerc
No Code AI from LinuxFoundation.org
https://www.linuxfoundation.org/projects
https://www.linuxfoundation.org/press/open-metaverse-foundation
Cloudera Data Science Workbench
With Python, R, and Scala directly in the web browser, Cloudera Data Science Workbench (CDSW) delivers a self-service experience data scientists will love. Download and experiment with the latest libraries and frameworks in customizable project environments that work just like your laptop. Access any data, anywhere—from cloud object storage to data warehouses, Cloudera Data Science Workbench provides connectivity not only to CDH and HDP but also to the systems your data science teams rely on for analysis.
MLFlow.org
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
- MLflow Tracking: An API to log parameters, code, and results in machine learning experiments and compare them using an interactive UI.
- MLflow Projects: A code packaging format for reproducible runs using Conda and Docker, so you can share your ML code with others.
- MLflow Models: A model packaging format and tools that let you easily deploy the same model (from any ML library) to batch and real-time scoring on platforms such as Docker, Apache Spark, Azure ML and AWS SageMaker.
- MLflow Model Registry: A centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of MLflow Models.
Recommended ML Basic Courses from Datacamp
These personalized recommendations are based on your skill gaps. Start one now to improve your skills.
STATISTICS FUNDAMENTALS
Data Science for Everyone
MACHINE LEARNING
Machine Learning for Everyone
AI Fundamentals
DATA AND SUMMARIES
Data Visualization for Everyone
Introduction to Tableau
Data Science for Everyone
Step-by-step guide for Example
sample code block
Recommended Next Steps
Related articles
*