Key Points
- Popular NoSQL database with open-source and enterprise licenses available
- Mongo Atlas is the optional MongoDB cloud service running on AWS that is highly reslient
- Many products and languages can access MongoDB directly with a driver or using a 3rd party service Mongoose that provides SQL interface with added features
- Has features of a NoSQL database and some relational database features as well ( eg foreign key relations possible )
- Relation to CAP theorem for updates? MongoDB favors consistency with ACID transactions as default compared to other NoSQL DBs
- Compare to other open-source NoSQL databases ( Cassandra, CouchDB, LevelDB and more )
References
Key CSA Concepts
Solution
CSA Review Scope
Capabilities Summary
Candidate Use Cases
Solution editions and versions in focus
Related Standards
Internal How to Guidance on Usage
Mongo Export, Import using JSON files
on mongoexport commands add --pretty to get formatted json
Export using JSON files from Mongo shell
https://www.quackit.com/mongodb/tutorial/mongodb_export_data.cfm
after connection,
mongoexport --db music --collection artists --out /data/dump/music/artists.json
Export to a csv file
mongoexport --db music --collection artists --type=csv --fields _id,artistname --out /data/dump/music/artists.csv
Export a query to a file
mongoexport --db music --collection artists --query '{"artistname": "Miles Davis"}' --out /data/dump/music/miles_davis.json
Import JSON collection from Mongo shell
mongoimport -d datbase_name -c collection_name file_name
ex- mongoimport -d test -c users users.json
MongoDB for Node.js Developers
https://docs.mongodb.com/drivers/node/
MongoDb for Nodejs developer guides
https://docs.mongodb.com/drivers/node/quick-start
const { MongoClient } = require("mongodb");
// Replace the uri string with your MongoDB deployment's connection string.
const uri =
"mongodb+srv://<user>:<password>@<cluster-url>?retryWrites=true&writeConcern=majority";
const client = new MongoClient(uri);
async function run() {
try {
await client.connect();
const database = client.db('sample_mflix');
const collection = database.collection('movies');
// Query for a movie that has the title 'Back to the Future'
const query = { title: 'Back to the Future' };
const movie = await collection.findOne(query);
console.log(movie);
} finally {
// Ensures that the client will close when you finish/error
await client.close();
}
}
run().catch(console.dir);
Nodejs app to read, update Mongodb docs on Atlas
/*
nt-mongo-atlas2.js
https://docs.mongodb.com/drivers/node/quick-start
https://docs.mongodb.com/drivers/node/
https://docs.mongodb.com/drivers/node/usage-examples
find by ObjectId ex
https://docs.mongodb.com/drivers/node/usage-examples/findOne
https://kb.objectrocket.com/mongo-db/nodejs-mongodb-find-by-id-686
https://docs.mongodb.com/drivers/node/usage-examples/updateOne
https://docs.mongodb.com/drivers/node/usage-examples/replaceOne
https://wesbos.com/destructuring-objects
*/
var atitle = "\n nt-mongo-atlas2.js - test mongo read write to atlas \n";
console.log(`${atitle}`);
var astep = "start";
const { MongoClient } = require("mongodb");
const uri = "mongodb+srv://dbAdmin:u3KpFTzZBEIEQLzY@cluster0.pfjbe.mongodb.net/test-db";
const connectOptions = {useUnifiedTopology: true};
const client = new MongoClient(uri,connectOptions);
const { ObjectId } = require("mongodb").ObjectId;
var collection = null;
var device = null;
var database = null;
var storageKWH, _id, deviceName, deviceGroup, sumKWH;
async function run() {
try {
await client.connect();
database = client.db("test-db");
collection = database.collection("devices");
await queryDevice();
var {_id, deviceName, deviceGroup, storageKWH} = device;
console.log(`device found = ${deviceName} _id: ${_id}`);
sumKWH = storageKWH + 75;
console.log(` after energy load, sum of storageKWH = ${sumKWH}`);
await updateDevice(device, sumKWH);
console.log(`device energy load completed`);
} finally {
await client.close();
}
};
// https://docs.mongodb.com/drivers/node/usage-examples/findOne
async function queryDevice() {
console.log(`queryDevice called`);
// Query for a movie that has the title 'The Room'
// var query = { deviceName: "solar panel 3000 MW v4" };
var oid1 = new ObjectId("6000908b07564302da69e742");
var query = { _id: oid1};
var options = {
// sort matched documents in descending order by rating
sort: { deviceName: -1 },
// Include only the `title` and `imdb` fields in the returned document
projection: { _id: 1, deviceName: 1, deviceGroup: 1, storageKWH: 1 },
};
// console.log(`query = ${query}`);
device = await collection.findOne(query, options);
// since this method returns the matched document, not a cursor, print it directly
};
// https://docs.mongodb.com/drivers/node/usage-examples/updateOne
async function updateDevice(device, sumKWH) {
var {_id, deviceName, deviceGroup, storageKWH} = device;
var oid1 = new ObjectId(_id);
var filter = {_id: oid1}
var options = {
upsert: true
};
var updateDoc = {
$set: {
storageKWH: sumKWH,
energyStatus: "loaded"
},
};
const result = await collection.updateOne(filter, updateDoc, options );
console.log(`updateDevice "${deviceName}"" matched ${result.matchedCount} count completed with ${sumKWH}`);
};
run().catch(console.dir);
MongoDB Connections
Let’s get around to setting up a connection with the Mongo DB database. Jumping straight
into the code let’s do direct connection and then look at the code.
// Retrieve
var MongoClient = require('mongodb').MongoClient;
// Connect to the db
MongoClient.connect("mongodb://localhost:27017/exampleDb", function(err, db) {
if(!err) {
console.log("We are connected");
}
});
Let’s have a quick look at how the connection code works. The Db.connect method let’s use
use a uri to connect to the Mongo database, where localhost:27017 is the server host and
port and exampleDb the db we wish to connect to. After the url notice the hash containing
the auto_reconnect key. Auto reconnect tells the driver to retry sending a command to the
server if there is a failure during its execution.
Another useful option you can pass in is
poolSize, this allows you to control how many tcp connections are opened in parallel. The
default value for this is 5 but you can set it as high as you want. The driver will use a round-
robin strategy to dispatch and read from the tcp connection.
Mongo CRUD
insert docs example 1
// Retrieve
var MongoClient = require('mongodb').MongoClient;
// Connect to the db
MongoClient.connect("mongodb://localhost:27017/exampleDb", function(err, db) {
if(err) { return console.dir(err); }
var collection = db.collection('test');
var doc1 = {'hello':'doc1'};
var doc2 = {'hello':'doc2'};
var lotsOfDocs = [{'hello':'doc3'}, {'hello':'doc4'}];
collection.insert(doc1);
collection.insert(doc2, {w:1}, function(err, result) {});
collection.insert(lotsOfDocs, {w:1}, function(err, result) {});
});
query by key example 1
// Retrieve
var MongoClient = require('mongodb').MongoClient;
// Connect to the db
MongoClient.connect("mongodb://localhost:27017/exampleDb", function(err, db) {
if(err) { return console.dir(err); }
var collection = db.collection('test');
var docs = [{mykey:1}, {mykey:2}, {mykey:3}];
collection.insert(docs, {w:1}, function(err, result) {
collection.find().toArray(function(err, items) {});
var stream = collection.find({mykey:{$ne:2}}).stream();
stream.on("data", function(item) {});
stream.on("end", function() {});
collection.findOne({mykey:1}, function(err, item) {});
});
});
query with projection example
m MongoDB#QueryDocumentsViewsusingAggregate%26%24Project
update docs example 1 - field level updates
// Retrieve
var MongoClient = require('mongodb').MongoClient;
// Connect to the db
MongoClient.connect("mongodb://localhost:27017/exampleDb", function(err, db) {
if(err) { return console.dir(err); }
var collection = db.collection('test');
var doc = {mykey:1, fieldtoupdate:1};
collection.insert(doc, {w:1}, function(err, result) {
collection.update({mykey:1}, {$set:{fieldtoupdate:2}}, {w:1}, function(err, result) {});
});
var doc2 = {mykey:2, docs:[{doc1:1}]};
collection.insert(doc2, {w:1}, function(err, result) {
collection.update({mykey:2}, {$push:{docs:{doc2:1}}}, {w:1}, function(err, result) {});
});
});
Alright before we look at the code we want to understand how document updates work and
how to do the efficiently. The most basic and less efficient way is to replace the whole
document, this is not really the way to go if you want to change just a field
Mongo DB provides a whole set of operations that let you modify just
pieces of the document Atomic operations documentation. Basically outlined below.
- $inc - increment a particular value by a certain amount
- $set - set a particular value
- $unset - delete a particular field (v1.3+)
- $push - append a value to an array
- $pushAll - append several values to an array
- $addToSet - adds value to the array only if its not in the array already
- $pop - removes the last element in an array
- $pull - remove a value(s) from an existing array
- $pullAll - remove several value(s) from an existing array
- $rename - renames the field
- $bit - bitwise operation
delete docs example 1
delete by key example
// Retrieve
var MongoClient = require('mongodb').MongoClient;
// Connect to the db
MongoClient.connect("mongodb://localhost:27017/exampleDb", function(err, db) {
if(err) { return console.dir(err); }
var collection = db.collection('test');
var docs = [{mykey:1}, {mykey:2}, {mykey:3}];
collection.insert(docs, {w:1}, function(err, result) {
collection.remove({mykey:1});
collection.remove({mykey:2}, {w:1}, function(err, result) {});
collection.remove();
});
});
Mongo Query
a find query returns an implicit cursor as part of the result set
the query below uses the next operator to pull the next document after the query ran with the limit applied
db.getCollection('vehicles').find({$and: [
{"lotDate" : {$lte: ISODate("2019-10-02T05:00:00.000Z")}},
{"lotDate" : {$gte: ISODate("2019-09-27T05:00:00.000Z")}}
]}).limit(20).next()
a find query where a document field is checked for equality on the literal value provided
db.getCollection('vehicles').find({'vehicleBuildInfo.vin': "1FAHP35N78W241105"})
db.getCollection('vehicles').find({$and: [{'vehicleBuildInfo.model': "Focus"},{'vehicleBuildInfo.year': "2008"}]})
Query with Regex Examples
https://www.guru99.com/regular-expressions-mongodb.html
{ "email": {$regex: "Mason", $options: "i"}}
or // without options
{ "email": /mason/}
Query Documents Views using Aggregate & $Project
// get count of photos in a vehicle
db.getCollection('vehicles').aggregate([
{$match: { 'dealerId': "58a4cd88c950220037cc0a38"} },
{$project: {'vehicleBuildInfo.vin': true, 'photo_count': {$size: "$media.photos"}}},
{$match: { 'photo_count': {$gte: 50}} }
])
// list orgs from org collection using a projection ( no real aggregation )
db.orgs.aggregate([{$project:{_id:true, "orgName":true, "status":true}}])
Mongo Pipelines - Read and Write - aggregate
One Mongo Pipeline Architecture with Kafka for networks
https://www.mongodb.com/blog/post/getting-started-with-the-mongodb-connector-for-apache-kafka-and-mongodb-atlas?fbclid=IwAR1wRmhFPzONiNRkN3ujUwL-NvAcozRb0AvtO0bS-PUxA48nvUEPTkPIRd8

Aggregation Pipelines
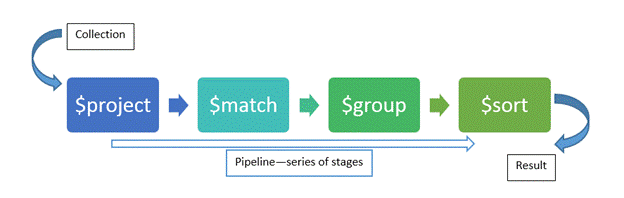
The aggregation pipeline is a framework for data aggregation modeled on the concept of data processing pipelines. Documents enter a multi-stage pipeline that transforms the documents into aggregated results. For example:
First Stage: The $match stage filters the documents by the status field and passes to the next stage those documents that have status equal to "A".
Second Stage: The $group stage groups the documents by the cust_id field to calculate the sum of the amount for each unique cust_id.
Pipeline
The MongoDB aggregation pipeline consists of stages. Each stage transforms the documents as they pass through the pipeline. Pipeline stages do not need to produce one output document for every input document; e.g., some stages may generate new documents or filter out documents.
Aggregation Pipeline Stages
The aggregate command can return either a cursor or store the results in a collection. When returning a cursor or storing the results in a collection, each document in the result set is subject to the BSON Document Size limit, currently 16 megabytes; if any single document that exceeds the BSON Document Size limit, the command will produce an error. The limit only applies to the returned documents; during the pipeline processing, the documents may exceed this size. The db.collection.aggregate() method returns a cursor by default.
Memory Restrictions
Pipeline stages have a limit of 100 megabytes of RAM. If a stage exceeds this limit, MongoDB will produce an error. To allow for the handling of large datasets, use the allowDiskUse option to enable aggregation pipeline stages to write data to temporary files.
Operators come in three varieties: stages, expressions, and accumulators.
When calling aggregate on a collection, we pass a list of stage operators. Documents are processed through the stages in sequence, with each stage applying to each document individually. Most importantly remember, that aggregation is a “pipeline” and is just exactly that, being “piped” processes that feed input into the each stage as it goes along. The output from the first thing goes to the next thing and then that manipulates to give input to the next thing and so on.
To read more about this Pipeline process their beautiful official documentation page.
Aggregation Pipeline Quick Reference - v4.2
aggregation-pipelines-docs.mongodb.com-Aggregation Pipeline Quick Reference.pdf
Aggregation examples
You can use aggregate to NOT aggregate as well.
Using multiple $match operations you can filter quickly a collection starting with the conditions that are indexed on the collection first.
This creates ( in theory ) a smaller result set that the non-indexed filters can be applied to second resulting in decent performance queries given the indexes.
multi-stage filters using aggregate - $match sets
//vehicles w future lot dates
db.getCollection('vehicles').find({$and: [{"ingestion.rawData.lot date" : {$lte: ISODate("2019-12-01T05:00:00.000Z")}},{"docinfo.createdAt" : {$gte: ISODate("2019-09-20T05:00:00.000Z")}}]}).sort({lotDate: -1})
create a table of acquisitionSource value counts
db.getCollection('vehicles').aggregate([
{ $group: { _id: "$acquisitionSource", count: {$sum: 1 }}},
{ $match: { count: {$gte: 10} }}
])filter and aggregate example
db.orders.aggregate([
{ $match: { status: "A" } },
{ $group: { _id: "$cust_id", total: { $sum: "$amount" } } }
])
use aggregate to create an efficient pipeline using existing indexes first in the pipeline
db.getCollection('vehicles').aggregate([
{ $match: { "vehicleBuildInfo.year": {$gte: 2018} }},
{ $match: { "dealerId" : "5967c3ad6bcc9819a8c44a81"}}
])
use project to define a new result view including generated fields from expressions
db.getCollection('vehicles').aggregate([
{ $match: { "dealerId" : "5967c3ad6bcc9819a8c44a81"}},
{ $project: {_id: true, "lotDate": true, "car_type": {$concat: ["$vehicleBuildInfo.make", "--", "$vehicleBuildInfo.model"]}}}
])
Accumulators
https://docs.mongodb.com/manual/reference/operator/aggregation/#accumulators-group
Some operators that are available as accumulators for the $group stage are also available for use in other stages but not as accumulators. When used in these other stages, these operators do not maintain their state and can take as input either a single argument or multiple arguments. For details, refer to the specific operator page.
The following accumulator operators are also available in the $project, $addFields, and $set stages.
| Name | Description |
|---|
$avg | Returns an average of the specified expression or list of expressions for each document. Ignores non-numeric values. |
$max | Returns the maximum of the specified expression or list of expressions for each document |
$min | Returns the minimum of the specified expression or list of expressions for each document |
$stdDevPop | Returns the population standard deviation of the input values. |
$stdDevSamp | Returns the sample standard deviation of the input values. |
$sum | Returns a sum of numerical values. Ignores non-numeric values. |
more expressions include Javascript ...
can define variable expressions
$let | Defines variables for use within the scope of a subexpression and returns the result of the subexpression. Accepts named parameters. Accepts any number of argument expressions. |
Tip - Pipelines - create Multi-Level Groupings - 2 options
https://stackoverflow.com/questions/23001784/mongodb-query-for-2-level-grouping
Example
Suppose I have documents that, among others, have these fields:
{
"class" : String,
"type" : String,
"name" : String,
}
Target Output
Suppose I have documents that, among others, have these fields:
{
"class" : String,
"type" : String,
"name" : String,
}
For example, many like this:
{
"class": "class A",
"type": "type 1",
"Name": "ObjectA1"
}
{
"class": "class A",
"type": "type 2",
"Name": "ObjectA2_1"
}
{
"class": "class A",
"type": "type 2",
"Name": "ObjectA2_2"
}
{
"class": "class B ",
"type": "type 3",
"Name": "ObjectB3"
}
What I want is a query that returns me the following structure
{
"class A" : {
"type 1" : ["ObjectA1"],
"type 2" : ["ObjectA2_1", "ObjectA2_2"]
},
"class B" : {
"type 3" : ["ObjectB3"]
}
}
Option 1 - Multi-level grouping with aggregation groups
I found a workaround for what I needed. It's not the same but solves my problem.
db.myDb.aggregate(
{
$group:{
_id: {
class_name : "$class",
type_name : "$name"
},
items: {
$addToSet : "$name"
}
}
},
{
$group:{
_id : "$_id.class_name",
types : {
$addToSet : {
type : "$_id.type_name",
items : "$items"
}
}
}
})
this gave me something like:
{
_id : "class A",
types: [
{
type: "type 1",
items: ["ObjectA1"]
},
{
type: "type 2",
items: ["ObjectA2_1", "ObjectA2_2"]
}
]
},
{
_id : "class B",
types: [
{
type: "type 3",
items: ["ObjectB3"]
}
]
}
Both code and example were written here so there may be typos.
Option 2 - Multi-level grouping with aggregation groups and map-reduce code
The problem with using the aggregation framework will be that you cannot specify an arbitrary key name for a property of an object. So reshaping using that would not be possible without being able to specify all of the possible key names.
So to get the result you would need to work something in JavaScript such as mapReduce:
First define a mapper:
var mapper = function () {
var key = this["class"];
delete this._id;
delete this["class"];
emit( key, this );
};
Then a reducer:
var reducer = function (key, values) {
var reducedObj = {};
values.forEach(function(value) {
if ( !reducedObj.hasOwnProperty(value.type) )
reducedObj[value.type] = [];
reducedObj[value.type].push( value.Name );
});
return reducedObj;
};
And because you have ( in your sample at least ) possible items that will be emitted from the mapper with only 1 key value you will also need a finalize function:
var finalize = function (key,value) {
if ( value.hasOwnProperty("name") ) {
value[value.type] = value.name;
delete value.type;
delete value.name;
}
return value;
};
Then you call the mapReduce function as follows:
db.collection.mapReduce(
mapper,
reducer,
{ "out": { "inline": 1 }, "finalize": finalize }
)
And that gives the following output:
"results" : [
{
"_id" : "class A",
"value" : {
"type 1" : [
"ObjectA1"
],
"type 2" : [
"ObjectA2_1",
"ObjectA2_2"
]
}
},
{
"_id" : "class B ",
"value" : {
"type" : "type 3",
"Name" : "ObjectB3"
}
}
],
While the result is formatted in a very mapReduce way, it is definitely much the same as your result.
But if you really did want to take that further, you can always do the following:
Define another mapper:
var mapper2 = function () {
emit( null, this );
};
And another reducer:
var reducer2 = function (key,values) {
reducedObj = {};
values.forEach(function(value) {
reducedObj[value._id] = value.value;
});
return reducedObj;
};
Then run the first mapReduce with the output to a new collection:
db.collection.mapReduce(
mapper,
reducer,
{ "out": { "replace": "newcollection" }, "finalize": finalize }
)
Followed by a second mapReduce on the new collection:
db.newcollection.mapReduce(
mapper2,
reducer2,
{ "out": { "inline": 1 } }
)
And there is your result:
"results" : [
{
"_id" : null,
"value" : {
"class A" : {
"type 1" : [
"ObjectA1"
],
"type 2" : [
"ObjectA2_1",
"ObjectA2_2"
]
},
"class B " : {
"type" : "type 3",
"Name" : "ObjectB3"
}
}
}
MapReduce examples
https://docs.mongodb.com/manual/core/map-reduce/
in theory, filtering before map-reduce makes queries more efficient since you are ( in theory ) processing less data.
Potential Value Opportunities
Potential Challenges
Mongo v2.x challenges
http://snmaynard.com/2012/10/17/things-i-wish-i-knew-about-mongodb-a-year-ago/
Selective counts are slow even if indexed
For example, when paginating a users feed of activity, you might see something like,
db.collection.count({username: "my_username"});In MongoDB this count can take orders of magnitude longer than you would expect. There is an open ticket and is currently slated for 2.4, so here’s hoping they’ll get it out. Until then you are left aggregating the data yourself. You could store the aggregated count in mongo itself using the $inc command when inserting a new document.
Inconsistent reads in replica sets
When you start using replica sets to distribute your reads across a cluster, you can get yourself in a whole world of trouble. For example, if you write data to the primary a subsequent read may be routed to a secondary that has yet to have the data replicated to it. This can be demonstrated by doing something like,
// Writes the object to the primary
db.collection.insert({_id: ObjectId("505bd76785ebb509fc183733"), key: "value"});
// This find is routed to a read-only secondary, and finds no results
db.collection.find({_id: ObjectId("505bd76785ebb509fc183733")});
This is compounded if you have performance issues that cause the replication lag between a primary and its secondaries to increase to minutes or even hours in some cases.
You can control whether a query is run on secondaries and also how many secondaries are replicated to during the insert, but this will affect performance and could block forever in some cases!
Range queries are indexed differently
I have found that range queries use indexes slightly differently to other queries. Ordinarily you would have the key used for sorting as the last element in a compound index. However, when using a range query like $in for example, Mongo applies the sort before it applies the range. This can cause the sort to be done on the documents in memory, which is pretty slow!
// This doesn't use the last element in a compound index to sort
db.collection.find({_id: {$in : [
ObjectId("505bd76785ebb509fc183733"),
ObjectId("505bd76785ebb509fc183734"),
ObjectId("505bd76785ebb509fc183735"),
ObjectId("505bd76785ebb509fc183736")
]}}).sort({last_name: 1});
At Heyzap we worked around the problem by building a caching layer for the query in Redis, but you can also run the same query twice if you only have two values in your $in statement or adjust your index if you have the RAM available.
You can read more about the issue or view a ticket.
Mongo’s BSON ID is awesome
Mongo’s BSON ID provides you with a load of useful functionality, but when I first started using Mongo, I didn’t realize half the things you can do with them. For example, the creation time of a BSON ID is stored in the ID. You can extract that time and you have a created_at field for free!
// Will return the time the ObjectId was created
ObjectId("505bd76785ebb509fc183733").getTimestamp();
The BSON ID will also increment over time, so sorting by id will sort by creation date as well. The column is also indexed automatically, so these queries are super fast. You can read more about it on the 10gen site.
Index all the queries
When I first started using Mongo, I would sometimes run queries on an ad-hoc basis or from a cron job. I initially left those queries unindexed, as they weren’t user facing and weren’t run often. However this caused performance problems for other indexed queries, as the unindexed queries do a lot of disk reads, which impacted the retrieval of any documents that weren’t cached. I decided to make sure the queries are at least partially indexed to prevent things like this happening.
Always run explain on new queries
This may seem obvious, and will certainly be familiar if you’ve come from a relational background, but it is equally important with Mongo. When adding a new query to an app, you should run the query on production data to check its speed. You can also ask Mongo to explain what its doing when running the query, so you can check things like which index its using etc.
db.collection.find(query).explain()
{
// BasicCursor means no index used, BtreeCursor would mean this is an indexed query
"cursor" : "BasicCursor",
// The bounds of the index that were used, see how much of the index is being scanned
"indexBounds" : [ ],
// Number of documents or indexes scanned
"nscanned" : 57594,
// Number of documents scanned
"nscannedObjects" : 57594,
// The number of times the read/write lock was yielded
"nYields" : 2 ,
// Number of documents matched
"n" : 3 ,
// Duration in milliseconds
"millis" : 108,
// True if the results can be returned using only the index
"indexOnly" : false,
// If true, a multikey index was used
"isMultiKey" : false
}
I’ve seen code deployed with new queries that would take the site down because of a slow query that hadn’t been checked on production data before deploy. It’s relatively quick and easy to do so, so there is no real excuse not to!
Profiler
MongoDB comes with a very useful profiler. You can tune the profiler to only profile queries that take at least a certain amount of time depending on your needs. I like to have it recording all queries that take over 100ms.
// Will profile all queries that take 100 ms
db.setProfilingLevel(1, 100);
// Will profile all queries
db.setProfilingLevel(2);
// Will disable the profiler
db.setProfilingLevel(0);
The profiler saves all the profile data into the capped collection system.profile. This is just like any other collection so you can run some queries on it, for example
// Find the most recent profile entries
db.system.profile.find().sort({$natural:-1});
// Find all queries that took more than 5ms
db.system.profile.find( { millis : { $gt : 5 } } );
// Find only the slowest queries
db.system.profile.find().sort({millis:-1});
You can also run the show profile helper to show some of the recent profiler output.
The profiler itself does add some overhead to each query, but in my opinion it is essential. Without it you are blind. I’d much rather add small overhead to the overall speed of the database to give me visibility of which queries are causing problems. Without it you may just be blissfully unaware of how slow your queries actually are for a set of your users.
Useful Mongo commands
Heres a summary of useful commands you can run inside the mongo shell to get an idea of how your server is acting. These can be scripted so you can pull out some values and chart or monitor them if you want.
db.currentOp() - shows you all currently running operations
db.killOp(opid) - lets you kill long running queries
db.serverStatus() - shows you stats for the entire server, very useful for monitoring
db.stats() - shows you stats for the selected db
db.collection.stats() - stats for the specified collection
Monitoring
While monitoring production instances of Mongo over the last year or so, I’ve built up a list of key metrics that should be monitored.
Index sizes
Seeing as how in MongoDB you really need your working set to fit in RAM, this is essential. At Heyzap for example, we would need our entire indexes to sit in memory, as we would quite often query our entire dataset when viewing older games or user profiles.
Charting the index size allowed Heyzap to accurately predict when we would need to scale the machine, drop an index or deal with growing index size in some other way. We would be able to predict to within a day or so when we would start to have problems with the current growth of index.
Current ops
Charting your current number of operations on your mongo database will show you when things start to back up. If you notice a spike in currentOps, you can go and look at your other metrics to see what caused the problem. Was there a slow query at that time? An increase in traffic? How can we mitigate this issue? When current ops spike, it quite often leads to replication lag if you are using a replica set, so getting on top of this is essential to preventing inconsistent reads across the replica set.
Index misses
Index misses are when MongoDB has to hit the disk to load an index, which generally means your working set is starting to no longer fit in memory. Ideally, this value is 0. Depending on your usage it may not be. Loading an index from disk occasionally may not adversely affect performance too much. You should be keeping this number as low as you can however.
Replication lag
If you use replication as a means of backup, or if you read from those secondaries you should monitor your replication lag. Having a backup that is hours behind the primary node could be very damaging. Also reading from a secondary that is many hours behind the primary will likely cause your users confusion.
I/O performance
When you run your MongoDB instance in the cloud, using Amazon’s EBS volumes for example, it’s pretty useful to be able to see how the drives are doing. You can get random drops of I/O performance and you will need to correlate those with performance indicators such as the number of current ops to explain the spike in current ops. Monitoring something like iostat will give you all the information you need to see whats going on with your disks.
Monitoring commands
There are some pretty cool utilities that come with Mongo for monitoring your instances.
mongotop - shows how much time was spend reading or writing each collection over the last second
mongostat - brilliant live debug tool, gives a view on all your connected MongoDB instances
Monitoring frontends
MMS - 10gen’s hosted mongo monitoring service. Good starting point.
Kibana - Logstash frontend. Trend analysis for Mongo logs. Pretty useful for good visibility.
MongoDB memory errors
out of memory on sort operations
db.getCollection('vehicles').find({$and: [{"docinfo.createdAt" : {$gte: ISODate("2019-09-20T05:00:00.000Z")}}]}).sort({lotDate: -1})failed on memory error during sort
Error: error: {
"ok" : 0,
"errmsg" : "Executor error during find command :: caused by :: errmsg: \"Sort operation used more than the maximum 33554432 bytes of RAM. Add an index, or specify a smaller limit.\"",
"code" : 96,
"codeName" : "OperationFailed",
"operationTime" : Timestamp(1569854890, 1),
Solutions
segregate data queries to shard the full data set based on a criteria ( eg query by year or month or ?? )
Sort operation used more than the maximum 33554432 bytes of RAM. Add an index, or specify a smaller limit
Candidate Solutions
Robo 3T - free excellent Mongo client for testing Mongo statements
Studio 3T - GUI enchanced Mongo dev environment with lower learning curve
Mongo Compass - Mongo's free client tool
Mongoose - framework to use SQL statements to return Mongo data or do CRUD operations - runs in Nodejs
Mongo drivers - allow connecting other applications to MongoDb ( ODBC, JDBC Java and more )
Mongo CLI - REPL editor to test from command line - aka Mongo Shell
Mongo Shell
Export Query Robo 3T to json file example
https://stackoverflow.com/questions/28733692/how-to-export-json-from-mongodb-using-robomongo
You can use tojson to convert each record to JSON in a MongoDB shell script.
Run this script in RoboMongo:
var cursor = db.getCollection('foo').find({}, {});
while(cursor.hasNext()) {
print(tojson(cursor.next()))
}
This prints all results as a JSON-like array.
The result is not really JSON! Some types, such as dates and object IDs, are printed as JavaScript function calls, e.g., ISODate("2016-03-03T12:15:49.996Z").
Might not be very efficient for large result sets, but you can limit the query. Alternatively, you can use mongoexport.
Robo 3T example - using js in Mongo console
var cursor = db.getSiblingDB('authentication').getCollection('dealers').find({_id: ObjectId("58a4cd88c950220037cc0a38")},{'name.common': 1, _id: false});
var myrec = null;
while(cursor.hasNext()) {
// print(tojson(cursor.next()))
myrec = cursor.next();
};
print(tojson(myrec.valueOf('name.common')));output
{ "name" : { "common" : "Jacksonville Chrysler Jeep Dodge" } }
Export Robo 3T example using robomong.js script on startup
https://github.com/Studio3T/robomongo/wiki/How-to-export-to-CSV
Export/Import to/from JSON and CSV features are under development.
Until these features are available, here is workaround solution how to export to CSV using Robomongo shell:
Workaround Solution: How to export to CSV
1) Create .robomongorc.js file with the following function into your home directory.
(Note: Specials thanks to @jeff-phil for this function: https://github.com/Studio3T/robomongo/issues/348#issuecomment-29362405 and @Ian Newson for the way to do it for aggregates https://stackoverflow.com/questions/16468602/mongoexport-aggregate-export-to-a-csv-file/48928948#48928948 )
// Export to CSV function
function toCSV (deliminator, textQualifier)
{
var count = -1;
var headers = [];
var data = {};
var cursor = this;
deliminator = deliminator == null ? ',' : deliminator;
textQualifier = textQualifier == null ? '\"' : textQualifier;
while (cursor.hasNext()) {
var array = new Array(cursor.next());
count++;
for (var index in array[0]) {
if (headers.indexOf(index) == -1) {
headers.push(index);
}
}
for (var i = 0; i < array.length; i++) {
for (var index in array[i]) {
data[count + '_' + index] = array[i][index];
}
}
}
var line = '';
for (var index in headers) {
line += textQualifier + headers[index] + textQualifier + deliminator;
}
line = line.slice(0, -1);
print(line);
for (var i = 0; i < count + 1; i++) {
var line = '';
var cell = '';
for (var j = 0; j < headers.length; j++) {
cell = data[i + '_' + headers[j]];
if (cell == undefined) cell = '';
line += textQualifier + cell + textQualifier + deliminator;
}
line = line.slice(0, -1);
print(line);
}
}
DBQuery.prototype.toCSV=toCSV; //regular find
DBCommandCursor.prototype.toCSV=toCSV; //aggregates
2) Close/open Robomongo to load the script.
3) Example usage:
db.getCollection('csv_coll').find({}).toCSV()
Output on Robomongo shell:
_id,name,surname,age
"584ac96e93775e9ffab70f52","alex","desouza","4"
"58d21b2a8a7c03ab0860fd7d","john","wick","40"
"58d21b378a7c03ab0860fd7e","mike","costanza","44"
Export Query Mongo Shell to json file example
use $out
Mongoose for SQL access to MongoDB
https://mongoosejs.com/docs/index.html
First be sure you have MongoDB and Node.js installed.
Next install Mongoose from the command line using npm:
$ npm install mongoose
Now say we like fuzzy kittens and want to record every kitten we ever meet in MongoDB. The first thing we need to do is include mongoose in our project and open a connection to the test database on our locally running instance of MongoDB.
var mongoose = require('mongoose');
mongoose.connect('mongodb://localhost/test', {useNewUrlParser: true});
We have a pending connection to the test database running on localhost. We now need to get notified if we connect successfully or if a connection error occurs:
var db = mongoose.connection;
db.on('error', console.error.bind(console, 'connection error:'));
db.once('open', function() {
});
Once our connection opens, our callback will be called. For brevity, let's assume that all following code is within this callback.
With Mongoose, everything is derived from a Schema. Let's get a reference to it and define our kittens.
var kittySchema = new mongoose.Schema({
name: String
});
So far so good. We've got a schema with one property, name, which will be a String. The next step is compiling our schema into a Model.
var Kitten = mongoose.model('Kitten', kittySchema);
A model is a class with which we construct documents. In this case, each document will be a kitten with properties and behaviors as declared in our schema. Let's create a kitten document representing the little guy we just met on the sidewalk outside:
var silence = new Kitten({ name: 'Silence' });
console.log(silence.name);
Kittens can meow, so let's take a look at how to add "speak" functionality to our documents:
kittySchema.methods.speak = function () {
var greeting = this.name
? "Meow name is " + this.name
: "I don't have a name";
console.log(greeting);
}
var Kitten = mongoose.model('Kitten', kittySchema);
Functions added to the methods property of a schema get compiled into the Model prototype and exposed on each document instance:
var fluffy = new Kitten({ name: 'fluffy' });
fluffy.speak();
We have talking kittens! But we still haven't saved anything to MongoDB. Each document can be saved to the database by calling its save method. The first argument to the callback will be an error if any occurred.
fluffy.save(function (err, fluffy) {
if (err) return console.error(err);
fluffy.speak();
});
Say time goes by and we want to display all the kittens we've seen. We can access all of the kitten documents through our Kitten model.
Kitten.find(function (err, kittens) {
if (err) return console.error(err);
console.log(kittens);
})
We just logged all of the kittens in our db to the console. If we want to filter our kittens by name, Mongoose supports MongoDBs rich querying syntax.
Kitten.find({ name: /^fluff/ }, callback);
This performs a search for all documents with a name property that begins with "Fluff" and returns the result as an array of kittens to the callback.
Congratulations
That's the end of our quick start. We created a schema, added a custom document method, saved and queried kittens in MongoDB using Mongoose. Head over to the guide, or API docs for more.
Mongoose Aggregation Example
https://medium.com/@paulrohan/aggregation-in-mongodb-8195c8624337
JOI Schemas for NoSQL Dbs on Servers
JOI Schema Tutorial - Scotch.io
https://scotch.io/tutorials/node-api-schema-validation-with-joi
JOI Features Article
https://medium.com/@rossbulat/joi-for-node-exploring-javascript-object-schema-validation-50dd4b8e1b0f
a schema with keys and fields
const schema = Joi.object().keys({
username: Joi.string().alphanum().min(6).max(16).required(),
password: Joi.string().regex(/^[a-zA-Z0-9]{6,16}$/).min(6).required()
}).with('username', 'password');
has a key definition included in the schema definition up front
this example extends a schema to add a key definition
//define base object
const base = Joi.object().keys({
a: Joi.number(),
b: Joi.string()
});// add a c key onto base schema
const extended = base.keys({
c: Joi.boolean()
});
with tests keys, peers for schema
with() is one of many Joi methods that test schema conditions. with() takes 2 arguments, key and peers. Peers can either be a string (a single peer), or an array of peers. What with() is saying is this:
For each of these peers being present, key also must be present for the schema to be valid.
without() method at our disposal, which defines which fields should not be present if a key is present!
arrays
To allow undefined values in arrays, we can use sparse(). We can define a strict length for an array, with length(), as well as the schema for our array items:
const schema = Joi.array().items(Joi.string(), Joi.number());
// array may contain strings and numbers
create objects and validate
let myObj = {
username: req.body.username,
password: req.body.password
};
const result = await Joi.validate(myObj, schema);
describe and compile methods
describe() and compile() are complimentary methods of Joi that help us “unwrap” and “wrap up” schema.
- “unwrapped schema”: A JSON representation of our schema object. To generate such JSON, we use
Joi.describe(schema). - “wrapped up” schema: A
Joi.object() we defined above, as a Joi formatted object. We can instantiate a Joi object from a JSON schema description by using Joi.compile(schema).
describe and compile methods
Remember our form data structure
Yup Schemas for data validation on front-ends
https://medium.com/@rossbulat/introduction-to-yup-object-validation-in-react-9863af93dc0e
With Yup, we create a Yup formatted object that resembles our intended schema for an object, and then use Yup utility functions to check if our data objects match this schema — hence validating them.
Form validation is by no means the only use case for Yup — use it to validate any object that you need to, whether you are retrieving data from your APIs or an external API library, or simply working with multiple objects or arrays within your project that need to adhere to a particular schema.
a data form example
{
email_address: email <required>
full_name: string, <required>
house_no: int,
address_1: string <required>,
address_2: string,
post_code: string <required>
timestamp: date <required>
}yup schema for the data form
const checkoutAddressSchema = yup.object().shape({ email_address: yup
.string()
.email()
.required(),
full_name: yup
.string()
.required(),
house_no: yup
.number()
.required()
.positive()
.integer(),
address_1: yup
.string()
.required(),
address_2: yup
.string(),
post_code: yup
.string()
.required(),
timestamp: yup
.date()
.default(() => (new Date()),
}),});
Data types such as string, integer, boolean, array, object and date are all callable validators within Yup
assign default values
...
timestamp: yup
.date()
.default(() => (new Date()),
}
...
sample form data submitted in an app
let addressFormData = {
email_address: 'ross@jkrbinvestments.com',
full_name: 'Ross Bulat',
house_no: null,
address_1: 'My Street Name',
post_code: 'AB01 0AB',
}check if the object is valid
const valid = await checkoutAddressSchema.isValid(addressFormData);
validate the data using the schema will run the default methods
await checkoutAddressSchema.validate(addressFormData);
cast just checks the data and fixes it if not valid
checkoutAddressSchema.cast(addressFormData);
more yup
Remember our form data structure
outlined at the top of the article? This can be retrieved from a Yup object with the describe() method.
combine 2 schemas into one? Use the concat() method.
Yup has some great string utilities, such as trim(), that removes whitespace around a string. uppercase() and lowercase() are available to enforce capitalising or not.
Yup also has some great number utilities, such as min() and max(), as well as round(), morethan(), lessthan(), and truncate()
Yup supports regex, allowing you to utilize regular expressions.
Can Yup do conditional formatting ? Yes using custom default functions
Step-by-step guide for Example
sample code block
Recommended Next Steps
Related articles