Key Points
foundation for enterprise architecture, solutions
driven by business use cases
covers variety of use cases: support, self service, enterprise services, integration ...
References
Key Concepts
Functional Data Layers Architecture
Source: Deloitte
The purpose of a data platform is to collect, store, transform and analyze data and make that data available to (business) users or other systems. It is often used for #businessIntelligence, (advanced) #analytics (such as #machineLearning) or as a data hub.
The platform consists of several components that can be categorized into common layers that each have a certain function. These layers are: Data Sources, Integration Layer, Processing Layer, Storage Layer, Analytics Layer, #Visualization Layer, Security, and #DataGovernance (Figure 1).
Data Sources
This layer contains the different sources of the data platform. This can be any information system, like ERP or CRM systems, but it can also be other sources like Excel files, Text files, pictures, audio, video or streaming sources like IOT devices.
Ingestion Layer The ingestion layer is responsible for loading the data from the data sources into the data platform. This layer is about extracting data from the source systems, checking the data quality and storing the data in the landing or staging area of the data platform.
Processing Layer The processing layer is responsible for transforming the data so that it can be stored in the correct data model. Processing can be done in batches (scheduled on a specific time/day) or done real-time depending on the type of data source and the requirements for the data availability.
Storage Layer The data is stored in the storage layer. This can be a relational database or some other storage technologies such as cloud storage, Hadoop, NoSQL database or Graph database.
Analytics Layer In the analytics layer the data is further processed (analyzed). This can be all kinds of (advanced) analytics algorithms, for example for machine learning. The outcome of the analytics can be sent to the visualization layer or stored in the storage layer.
Visualization Layer The data is presented to the end-user in the visualization layer. This can be in the form of reports, dashboards, self-service BI tooling or #API ’s so that the data can be used by other systems.
Security One of the important tasks of a data platform is to guarantee that only users that are allowed to use the data have access. A common method is user authentication and authorization, but it can also be required that the data is encrypted (storage and in transfer) and that all activities on the data are audited so that is it known who has accessed or modified which data.
Data Governance
Data governance is about locating the data in a data catalog, collecting and storing metadata about the data, managing the master data and/or reference data, and providing insights on where the data in the data platform originates from (i.e., #datalineage).

Is Hadoop still valid for batch data processing?
Apache Spark and other open-source frameworks are better now for some use cases
Spark has been found to run 100 times faster in-memory, and 10 times faster on disk. It’s also been used to sort 100 TB of data 3 times faster than Hadoop MapReduce on one-tenth of the machines. Spark has particularly been found to be faster on machine learning applications, such as Naive Bayes and k-means.
Spark performance, as measured by processing speed, has been found to be optimal over Hadoop, for several reasons:
Spark is not bound by input-output concerns every time it runs a selected part of a MapReduce task. It’s proven to be much faster for applications
Spark’s DAGs enable optimizations between steps. Hadoop doesn’t have any cyclical connection between MapReduce steps, meaning no performance tuning can occur at that level.
However, if Spark is running on YARN with other shared services, performance might degrade and cause RAM overhead memory leaks. For this reason, if a user has a use-case of batch processing, Hadoop has been found to be the more efficient system.
Improve RAJG data virtualization layers with data consumption methods
add consumption models from sources, lakes
batch, transaction request, events, streams
add column for MDM, governance
Data Services Methods
Architecture styles define how different components of an application programming interface (API) interact with one another.
Here are the most used styles:
🔹SOAP:
Mature, comprehensive, XML-based
Best for enterprise applications
🔹RESTful:
Popular, easy-to-implement, HTTP methods
Ideal for web services
🔹GraphQL:
Query language, request specific data
Reduces network overhead, faster responses
🔹gRPC:
Modern, high-performance, Protocol Buffers
Suitable for microservices architectures
🔹WebSocket:
Real-time, bidirectional, persistent connections
Perfect for low-latency data exchange
🔹Webhook:
Event-driven, HTTP callbacks, asynchronous
Notifies systems when events occur
Are there any other famous styles I missed? 👇🏿
Source: ByteByteGo, Alex Xu

Data Event Message Communications
Most applications are integrated based on events with shared data.
An event occurs in PC1 ( Process Context 1 ) and 1 or more other dependent processes ( PC2 .. PCN ) will listen and react to the events and the related event data.
Sources and Handlers of Events? Function or Object? While pure functions can generate events, objects provide a context for the event beyond the current function.
Objects are key for automated processing of events. They go beyond functions, providing a valid context and the capability to handle responsibilities for events, behaviors and data.
They organize and simplify the use of functions and APIs.
Event requirements
consider async event handling requirements vs sync handling
requires saving state for later processing, replays and recovery
is event access based on push or pull model? in many scenarios, push may be more efficient for real-time responsive application flows
is event message persistence required?
what are the replay and recovery requirements?
are messages broadcast or handled by specific handler?
is the design for a configured handler ( eg API, database, Web Sockets or RPC )?
is the design for a registered event listener ( pub / sub messages, SSE ( Server Sent Events ) )?
what are the V's ( Volatility, Volume, Variety, Variance, Value, Validity ) ?
Frameworks for communicating Events
API service - a client can call an API to send an event object to a service for processing and a response ( can be sync or async invocation )
Database with SSE ( Server Sent Events ) and Streams. SSE doesn't require a database ( can be a service ) but the DB can persist the events for replay, recovery etc
Messaging with optional persistence, push or pull delivery models to clients supports a wide set of interaction models including push or pull delivery, async or sync, with broadcast or request / response handling
RPC - Remote Procedure - direct invocation of remote process from current process passing an event object and optionally returning a result object ( can be sync or async invocation )
Web Sockets - a synchronous interactive communications model between a 2 processes ( source and target ). a Web socket is created from an HTTP connection that is upgraded
SSE - Server Sent Events - from a data service or custom api service- 1 way async messages from server to client
Distributed Files sent using a file service ( SFTP, Rsync etc )
Blockchain agents - most DLTs offer transaction finality and a variety of environment events
Custom Communications Service - custom comm apps can be fully duplex
GEMS = Global Event Management System
supports the Modern Value Chain Networks
used by multiple solution layers: net apps, malls, stores, services providers, tools
modular solution that connects across networks and platforms with interfaces and adapters to connect many components
open standards-based platform composed primarily of sustainable, open frameworks with added open source connector services
project managed by an open foundation ( see Linux Foundation or ? )
provides solid NFR capabilities for most use cases
extensible on services, interfaces
manageable and maintainable
version tolerance with mutation policies
Steps to define GEMS
I have a clear idea of the problem I'm trying to solve but need to build a real doc to clarify the use cases with concrete examples. Firefly may be a big part of the solution since it can connect multiple DLT nets, can communicate in multiple ways at the services layer ( not just DLT ) and has basic event support capabilities.
If I name the solution it's a global event workflow service that does pub / sub ( both push and pull models ) across multiple networks connected by a supernode model. There are concrete examples I need to specify.
I've built a simple version of that type of service in the past on a single distributed platform on IBM i because the platform had built-in support for event workflows that could be connected over a distributed net.
EDA > Event Driven Architecture for a simple event workflow solution

Architectural blueprint for #EventDrivenArchitecture-#Microservices Systems
The following figure is an architectural diagram of an EDA-microservices-based enterprise system. Some microservices components and types are shown separately for better clarity of the architecture.
The EDA and microservices-specific components in this blueprint are:
·Event backbone. The event backbone is primarily responsible for transmission, routing, and serialization of events. It can provide APIs for processing event streams. The event backbone offers support for multiple serialization formats and has a major influence on architectural qualities such as fault tolerance, elastic scalability, throughput, and so on. Events can also be stored to create event stores. An event store is a key architectural pattern for recovery and resiliency.
§ Services layer. The services layer consists of microservices, integration, and data and analytics services. These services expose their functionality through a variety of interfaces, including REST API, UI, or as EDA event producers and consumers. The services layer also contains services that are specific to EDA and that address cross-cutting concerns, such as orchestration services, streaming data processing services, and so on.
§ Data layer. The data layer typically consists of two sublayers. In this blueprint, individual databases owned by microservices are not shown.
§ Caching layer, which provides distributed and in-memory data caches or grids to improve performance and support patterns such as CQRS. It is horizontally scalable and may also have some level of replication and persistence for resiliency.
§ Big data layer, which is comprised of data warehouses, ODS, data marts, and AI/ML model processing.
§ Microservices chassis. The microservices chassis provides the necessary technical and cross-cutting services that are required by different layers of the system. It provides development and runtime capabilities. By using a microservices chassis, you can reduce design and development complexity and operating costs, while you improve time to market, quality of deliverables, and manageability of a huge number of microservices.
§ Deployment platform: Elastic, cost optimized, secure, and easy to use cloud platforms should be used. Developers should use as many PaaS services as possible to reduce maintenance and management overheads. The architecture should also provision for hybrid cloud setup, so platforms such as Red Hat OpenShift should be considered.
Key architectural considerations
The following architectural considerations are extremely important for event-driven, microservices-based systems:
·Architectural patterns
§ Technology stack
§ Event modeling
§ Processing topology
§ Deployment topology
§ Exception handling
§ Leveraging event backbone capabilities
§ Security
§ Observability
§ Fault tolerance and response
Source: IBM
#TransformPartner – Your #DigitalTransformation Consultancy
Jim >>
The concepts shown are a good start but not adequate to meet the event solution models we are looking at. On our end, we are looking to define a more global model for different use cases than you have here. I'm sure your implementation can be successful for your use case.
Solve the CAP theorem for async acid event transactions
Raj Grover >>
Event processing topology
In hashtag#EDA , processing topology refers to the organization of producers, consumers, enterprise integration patterns, and topics and queues to provide event processing capability. They are basically event processing pipelines where parts of functional logic (processors) are joined together using enterprise integration patterns and queues and topics. Processing topology is a combination of the SEDA, EIP, and Pipes & Filter patterns. For complex event processing, multiple processing topologies can be connected to each other.
The following figure depicts a blueprint of a processing topology.

compare to Firefly Core Stack for Event Management
Firefly: Web3 Blockchain framework#FireflyFeaturesandServices
Apache Pulsar - Event messaging & streaming
Apache® Pulsar™ is an open-source, distributed messaging and streaming platform built for the cloud.
What is Pulsar
Apache Pulsar is an all-in-one messaging and streaming platform. Messages can be consumed and acknowledged individually or consumed as streams with less than 10ms of latency. Its layered architecture allows rapid scaling across hundreds of nodes, without data reshuffling.
Its features include multi-tenancy with resource separation and access control, geo-replication across regions, tiered storage and support for six official client languages. It supports up to one million unique topics and is designed to simplify your application architecture.
Pulsar is a Top 10 Apache Software Foundation project and has a vibrant and passionate community and user base spanning small companies and large enterprises
Apache EventMesh
EventMesh is a new generation serverless event middleware for building distributed event-driven applications.
key features EventMesh has to offer:
Built around the CloudEvents specification.
Rapidly extensible language sdk around gRPC protocols.
Rapidly extensible middleware by connectors such as Apache RocketMQ, Apache Kafka, Apache Pulsar, RabbitMQ, Redis, Pravega, and RDMS(in progress) using JDBC.
Rapidly extensible controller such as Consul, Nacos, ETCD and Zookeeper.
Guaranteed at-least-once delivery.
Deliver events between multiple EventMesh deployments.
Event schema management by catalog service.
Powerful event orchestration by Serverless workflow engine.
Powerful event filtering and transformation.
Rapid, seamless scalability.
Easy Function develop and framework integration.

Event Solutions Comparisons
Solace
https://www.slideshare.net/Pivotal/solace-messaging-for-open-data-movement

https://www.slideshare.net/MagaliBoulet/solace-an-open-data-movement-company


Hyperledger Firefly Distributed Ledger Event Management
https://hyperledger.github.io/firefly/
https://hyperledger.github.io/firefly/reference/events.html
swt>FireflySolutionReview-HyperledgerFireflyDistributedLedgerEventManagement
Hyperledger FireFly Event Bus
The FireFly event bus provides your application with a single stream of events from all of the back-end services that plug into FireFly.
Applications subscribe to these events using developer friendly protocols like WebSockets, and Webhooks. Additional transports and messaging systems like NATS, Kafka, and JMS Servers can be connected through plugins.
Each application creates one or more Subscriptions to identify itself. In this subscription the application can choose to receive all events that are emitted within a namespace, or can use server-side filtering to only receive a sub-set of events.
The event bus reliably keeps track of which events have been delivered to which applications, via an offset into the main event stream that is updated each time an application acknowledges receipt of events over its subscription.
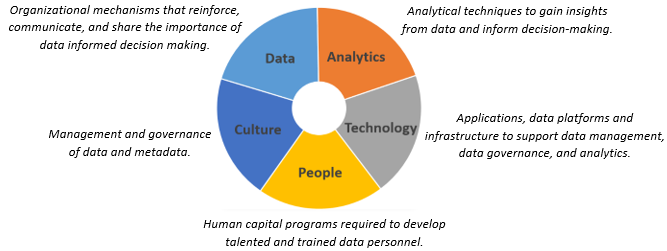
Federal Government Data Maturity Model (FGDMM)
https://www.dol.gov/agencies/odg/data-management-maturity-model
The Federal Data Strategy requires that agencies conduct data management maturity assessments. These assessments are useful in evaluating existing data management processes and capabilities, identifying how they meet mission needs, and suggesting opportunities for improvement. During FY2020, DOL developed a maturity assessment tool based off of the Advanced Analytics Capability Maturity Model (A2CM2).
Data Management Maturity Components
DOL assessed maturity in five core areas of data management including: data, analytics, technology, people, and culture.
Data Maturity Scale
The maturity scale in the models we use ranges from 1 (lowest level of capability) to 5 (highest level of capability).

Current DMM Score for DOL dept

FCMS - Data Maturity Model - Raj G
FMCS #DataMaturity Model
FMCS examined the agency’s infrastructure, data availability, and capabilities utilizing the Federal Government Data Maturity Model (FGDMM). The FGDMM assesses six lanes with five milestones each. The lanes are: #Analytics Capability, #DataCulture, #DataManagement, Data Personnel, Data Systems and #Technology, and #DataGovernance. FMCS applied the FGDMM to assess current capability and supporting processes, to communicates the current capability status to agency leadership and stakeholders, and to develop a plan of action with milestones to enhance FMCS’s use of data.
Low capability definition: Disparate systems and groups, reactive data. Management at the individual system level, poor #dataquality, little decision-making capability.
High Capability definition: Transparency and mission ROI. Thorough executive collaboration and accountability for data quality, government-wide standards, automation, and decision support.
FMCS currently possesses moderate data capabilities and has room to build upon existing infrastructure to transition to higher capability. FMCS utilizes the Data Governance group in consultation with other agency stakeholders while planning to meet high capability designations of data.
Source: FMCS


ISR - DTR = Digital Transformation Review for target domain by SWT - DMMR
Data Maturity Life Cycle - DMBOK

EIM - Enterprise Information Management Model concepts
Data Management is the business of planning, controlling and delivering data and information assets. It is a common synonym for EIM (enterprise information management), IM (information management), IAM (information asset management) and other similar terms and includes the disciplines of development, execution and supervision of plans, policies, projects/programs and processes to control, protect, deliver and enhance the value of data and information.
There are various component parts to data management which altogether enable an organisation’s data to be kept relevant, reliable, available, secure and consistent. An effective data management capability must ensure all of these parts work in tandem with the requisite people, process and technology aspects.
EAL’s data management capability has been developed on top of the DAMA (Data Management Body of Knowledge) methodology. This industry standard provides an internationally recognised framework for designing a comprehensive data management capability. The traditional DAMA wheel summarises the 10 key areas of Data Management.
If an organisation experiences the following pain points, it may be because its data is not managed and maintained with the same rigor as other assets.
· Inaccurate, duplicate counting of financial figures in reports;
· No single version of truth exists for key information;
· Proliferation of customer accounts for the same customer leading to lack of standardised quotation;
· Lack of 360-degree visibility of supplier spend;
· Poor data security leading to vulnerability;
· Poor data quality and lack of timely access.
In the modern economy, data should be valued as an asset. To harvest the right data and ensure maximum value from it there is no substitute for investing in a data management capability.

Gartner's 4 Stage Model for an end-to-end #Data and #Analytics Architecture
Extend the #DataArchitecture to Acquire Streaming and Cloud-Born External Data The "Acquire" stage (see image) embraces all data, regardless of volume, source, speed and type, providing the raw materials needed to enable downstream business processes and analytic activities. For example, the emergence of IoT requires data and analytics professionals to proactively manage, integrate and analyze real-time data. Internal log data often must be inspected in real time to protect against unauthorized intrusion, or to ensure the health of the technology backbone. Strategic IT involvement in sensor and log data management on the technology edge of the organization will bring many benefits, including increased value as such data is used to enhance analytics and improve operations.
In doing so, organizations must shift their traditional focus from getting the data in and hoping someone uses it to determining how best to get information out to the people and processes that will gain value from it. The sheer volume of data can clog data repositories if technical professionals subscribe to a "store everything" philosophy. For example, machine-learning algorithms can assess incoming streaming data at the edge and decide whether to store, summarize or discard it. When deciding whether and when data will be stored, holistic thinking about how the data will be used is another key aspect of the "end-to-end" thinking required.
Above and beyond streaming data, there is so much value-added content available from third parties that organizations are often challenged to find, select and leverage it. Syndicated data comes in a variety of forms, from a variety of sources. Examples include:
■ Consumer data from marketing and credit agencies
■ Geo-location data for population and traffic information
■ Weather data to enhance predictive algorithms that drive diverse use cases from public safety to retail shopping patterns
■ Risk management data for insurance
The core of the "Organize" stage of the end-to-end architecture is the LDW. It is the data platform for analytics, as defined in Gartner's "Adopt Logical Data Warehouse Architectural Patterns to Mature Your Data Warehouse." Every data warehouse is an LDW initiative waiting to materialize. An LDW:
■ Provides modern, scalable data management architecture that is well-positioned to support the data and analytics needs of the digital enterprise
■ Supports an incremental development approach that leverages existing enterprise data warehouse architecture and techniques in the organization
■ Establishes a shared data access layer that logically relates data, regardless of source

Sample Software Architecture Stacks

Sample Data Infrastructure - Datacamp **
https://www.datacamp.com/community/blog/data-infrastructure-tools
Data Architecture Support for Analytics
https://drive.google.com/open?id=1hFkbBLpCb2TktVxTDQ7rpZDabZCf-btW
Gartner Model for Data and Data Analytics
In doing so, organizations must shift their traditional focus from getting the data in and hoping someone uses it to determining how best to get information out to the people and processes that will gain value from it. The sheer volume of data can clog data repositories if technical professionals subscribe to a "store everything" philosophy. For example, machine-learning algorithms can assess incoming streaming data at the edge and decide whether to store, summarize or discard it. When deciding whether and when data will be stored, holistic thinking about how the data will be used is another key aspect of the "end-to-end" thinking required.
Above and beyond streaming data, there is so much value-added content available from third parties that organizations are often challenged to find, select and leverage it. Syndicated data comes in a variety of forms, from a variety of sources. Examples include:
■ Consumer data from marketing and credit agencies
■ Geo-location data for population and traffic information
■ Weather data to enhance predictive algorithms that drive diverse use cases from public safety to retail shopping patterns
■ Risk management data for insurance
The core of the "Organize" stage of the end-to-end architecture is the LDW. It is the data platform for analytics, as defined in Gartner's "Adopt Logical Data Warehouse Architectural Patterns to Mature Your Data Warehouse." Every data warehouse is an LDW initiative waiting to materialize. An LDW:
■ Provides modern, scalable data management architecture that is well-positioned to support the data and analytics needs of the digital enterprise
■ Supports an incremental development approach that leverages existing enterprise data warehouse architecture and techniques in the organization
■ Establishes a shared data access layer that logically relates data, regardless of source

Data Architecture Deliverables
https://drive.google.com/open?id=1LxtIcQ0yKmilUsej27KlAF1jdBXUogud
Data Architecture Concepts
https://drive.google.com/open?id=1p0enDE1WPMMeF8WyClqPaBPGM3ChXEW9
Snowflake Data Lake EBook v2
Cloud-Data-Lakes-For-Dummies-2nd-Snowflake-Special-Edition.pdf file
Overview
Flowing Data into the Lake
Understanding the Problems with Traditional Data Lakes Acknowledging Interim Solutions: Cloud Object Stores
Reviewing Modern Requirements
Explaining Why You Need a Modern Cloud Data Lake
Looking at Which Industries Use Modern Data Lakes and Why
Planning
Plan Data Lake
Step 1: Review Requirements
Step 2: Migrate or Start Fresh
Step 3: Establish Success Criteria
Step 4: Evaluate Solutions
Step 5: Set Up a Proof of Concept
Step 6: Quantify Value
Data Architecture Best Practices
https://drive.google.com/open?id=1ryNqjIE3LCY6Jxik_4V-urf2aCp9QLr0
Data Architecture vs Enterprise Architecture
https://drive.google.com/open?id=1O5q-cppIU3UZrFCJyQmHRWzROHTvKl-b
Data Architecture Strategy
https://drive.google.com/open?id=1Ke7goNNWm_lUu_RXiOkhfdUs2vqNFK4w
Define an Enterprise Data Strategy
Questions to Define Data Strategy - RajG
six-components-of-a-data-strategy

Data Architecture Options

Data Architecture Data Lakes
Build Enterprise Data Architecture
Build a Data Architecture Roadmap - infotech
Build_a_Data_Architecture_Roadmap__Phases_1_3-infotech.pdf link

Building an Enterprise Data Strategy – Where to Start? 2018
how to build an enterprise data strategy - self assessment
https://drive.google.com/open?id=1d_XCHd0B4vXbhCq_VAYRiwICSGyt9zsI link
data-architecture-build-strategy-dataversitydatastrategyburbankfeb2018-180227040559.pdf file
Enterprise vs Embedded Databases
Enterprise Databases > client - server model for mutliple clients and shared data, transactions
can support SQL, NoSQL or both
MySQL, Postgres, Mongo, more
neo4j - graph db
vector dbs - for ai
time series db - influxdb or mysql jem
Embedded Databases > single app to access the database - external options ?? jdbc etc - usually no
can support SQL, NoSQL or both
Sqlite, CouchDb
jdbc drivers - cdata
Data Lake Platform Concepts
khub.Data Services - Candidate Solutions
DWH > Data Lake > Lake House > Data Mesh concepts

data-delta-lake-up-&-running_er2.pdf. link. OReilly ebook
file
data-lake-databricks-rise_of_the_data_lakehouse_feb_2023_v2. link
 file
file
Lakehouse vs Data Lake - use cases & architecture - video
Architecture Deep Dive: Explore the technical intricacies of Data Lakes and Data Lakehouses, including their architectural differences and how they impact data storage, processing, and serving.
Table Formats: Review the file and table formats used to store and manage data, including their origin story, strengths and weaknesses, and ecosystem maturity.
Scalability and Performance: Understand how each solution scales in response to growing data volumes and their respective impacts on query performance and data processing efficiency.
Best Practices for Migration and Integration: Learn advanced techniques for transitioning from Data Lakes to Lakehouses, focusing on data migration, schema evolution, and integrating transactional processing capabilities for real-time analytics.
What’s a Data Mesh?
Data Mesh 101: What is Data Mesh? video - 10 m
https://www.youtube.com/watch?v=zfFyE3xmJ7I
Key features of a data mesh
core components - data mart, DDD ( domain design ), event streaming, microservices
missing trust model, client authorization to resources concepts, life cycle concepts for the products, data age versions
centralized event systems for distributed assets
common shared models for real-time operations reducing issues on traditional ELT models
integrates operations more effectively as data and service across a VCE
curated, shared, real-time data products and services

a>> compare Kafka, Pulsar, Event Mesh

test confluence cloud for free

Watch as Berglund introduces data mesh's four principles: data ownership by domain, data as a product, data available everywhere by self-serve, and data governed where it is. These principles will be further explored throughout the Data Mesh 101 course. Use the promo code DATAMESH101 to get $25 of free Confluent Cloud usage: https://cnfl.io/try-cloud-with-data-m... Promo code details: https://cnfl.io/promo-code-disclaimer...
LEARN MORE
► What Is Data Mesh, and How Does it Work? ft. Zhamak Dehghani: https://developer.confluent.io/podcas...
► An Introduction to Data Mesh: https://www.confluent.io/blog/benefit...
► The Definitive Guide to Building a Data Mesh with Event Streams: https://www.confluent.io/blog/how-to-...
► A Complete Guide to Data Mesh: https://developer.confluent.io/learn/...
► Why Data mesh? ft. Ben Stopford: https://developer.confluent.io/podcas...
► What is Data Mesh?: https://developer.confluent.io/learn/...
► Kafka Summit: Apache Kafka and the Data Mesh: https://www.confluent.io/events/kafka...
APIs can Integrate a Data Mesh
Create an AWS Data Lake
Build a Modern #DataArchitecture and #DataMesh pattern at scale using #AWS Lake Formation tag-based access control
Customers are exploring building a data mesh on their AWS platform using AWS Lake Formation and sharing their #datalakes across the organization. A data mesh architecture empowers business units (organized into domains) to have high ownership and autonomy for the technologies they use, while providing technology that enforces data security policies both within and between domains through data sharing. Data consumers request access to these data products, which are approved by producer owners within a framework that provides decentralized governance, but centralized monitoring and auditing of the data sharing process. As the number of tables and users increase, data stewards and administrators are looking for ways to manage permissions on data lakes easily at scale. Customers are struggling with “role explosion” and need to manage hundreds or even thousands of user permissions to control data access. For example, for an account with 1,000 resources and 100 principals, the data steward would have to create and manage up to 100,000 policy statements. As new principals and resources get added or deleted, these policies have to be updated to keep the permissions current.
Lake Formation tag-based access control (TBAC) solves this problem by allowing data stewards to create LF-tags (based on their business needs) that are attached to resources. You can create policies on a smaller number of logical tags instead of specifying policies on named resources. LF-tags enable you to categorize and explore data based on taxonomies, which reduces policy complexity and scales permissions management. You can create and manage policies with tens of logical tags instead of the thousands of resources. Lake Formation TBAC decouples policy creation from resource creation, which helps data stewards manage permissions on many databases, tables, and columns by removing the need to update policies every time a new resource is added to the data lake. Finally, TBAC allows you to create policies even before the resources come into existence. All you have to do is tag the resource with the right LF-tag to make sure existing policies manage it.
The following diagram illustrates the relationship between the data producer, data consumer, and central governance accounts.
In the diagram, the central governance account box shows the tagging ontology that will be used with the associated tag colors. These will be shared with both the producers and consumers, to be used to tag resources.

Data Pipeline Concepts
Modern Enterprise Data Pipelines
Build a Data Management Plan for the Organization

Data Architecture Support for Web Sockets at the application level
Web Sockets in Java
https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API/Writing_WebSocket_servers
https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API/Writing_a_WebSocket_server_in_Java
Writing WebSocket servers](/en-US/docs/Web/API/WebSockets_API/Writing_WebSocket_servers
https://github.com/TooTallNate/Java-WebSocket // example on Github from simple server and client
Article on Java web sockets client and server apps with source
https://medium.com/swlh/how-to-build-a-websocket-applications-using-java-486b3e394139
https://github.com/javiergs/Medium/tree/main/Websockets
Web Sockets with Spring
https://www.baeldung.com/websockets-spring
Web sockets in Nodejs
https://drive.google.com/file/d/1NxyaDws6ncWn3cehk-KxhEHK6kEh_5tC/view?usp=sharing
https://drive.google.com/file/d/1wr30FhzWCDgC_CSp22LL17nvieA4_LI3/view?usp=sharing
Data Architecture Support for Streams for Messaging at the application level
Kafka pull messaging model
Kotlin tutorial for client and server code
https://medium.com/swlh/async-messaging-with-kotlin-and-kafka-488e399e4e17
Introduction to Kafka Spring
https://www.baeldung.com/spring-kafka
Push messaging model
ActiveMQ
ActiveMQ as a broker interacting with a Camel ActiveMQ client
Difference between Message Topics and Queues
https://activemq.apache.org/how-does-a-queue-compare-to-a-topic
Topics
In JMS a Topic implements publish and subscribe semantics. When you publish a message it goes to all the subscribers who are interested - so zero to many subscribers will receive a copy of the message. Only subscribers who had an active subscription at the time the broker receives the message will get a copy of the message.
Queues
A JMS Queue implements load balancer semantics. A single message will be received by exactly one consumer. If there are no consumers available at the time the message is sent it will be kept until a consumer is available that can process the message. If a consumer receives a message and does not acknowledge it before closing then the message will be redelivered to another consumer. A queue can have many consumers with messages load balanced across the available consumers.
So Queues implement a reliable load balancer in JMS.
RabbitMQ
Data Architecture Support for Event Streams for Async Server Data Flow with SSE
SSE better over HTTP/2 with multiplexing connections
for more on HTTP2 see m TCP Networks
limited to UTF-8 tex encoded data with 2 new line separators between messages

Is the client app and server running HTTP2? ( required for useful SSE without connection limits over the single TLS connection )
https://dev.to/lek890/the-http-1-1-to-http-2-transition-for-web-apps-2bjm
For more on HTTP see m TCP Networks
for chrome browser, validate the app is running on a TLS server using HTTP2
chrome://net-internals/#http2
creates an option to capture http logs to file - scan for HTTP2 in log
HTTP2 standards for Server Sent Events SSE - part of HTML specification
https://html.spec.whatwg.org/multipage/server-sent-events.html
issue> servers drop http connections
Legacy proxy servers are known to, in certain cases, drop HTTP connections after a short timeout. To protect against such proxy servers, authors can include a comment line (one starting with a ':' character) every 15 seconds or so.
issue> Avoid http chunking is using event-stream connections
HTTP chunking can have unexpected negative effects on the reliability of this protocol, in particular if the chunking is done by a different layer unaware of the timing requirements. If this is a problem, chunking can be disabled for serving event streams.
issue> Client HTTP per server connection limitations
Clients that support HTTP's per-server connection limitation might run into trouble when opening multiple pages from a site if each page has an EventSource to the same domain. Authors can avoid this using the relatively complex mechanism of using unique domain names per connection, or by allowing the user to enable or disable the EventSource functionality on a per-page basis, or by sharing a single EventSource object using a shared worker.
Excellent article comparing SSE to Web Sockets
https://www.smashingmagazine.com/2018/02/sse-websockets-data-flow-http2/
Grails Guide for Server Sent Event - SSE - Tutorial - v3
https://guides.grails.org/grails3/server-sent-events/guide/index.html
Using_server-sent_events tutorial - PHP example but concepts ok
https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events/Using_server-sent_events
compare SSE and Web Sockets ***
https://javascript.info/server-sent-events
Java Server Sent Events in Spring **
https://www.baeldung.com/spring-server-sent-events
Developing real-time Web apps with Server Sent Events tutorial ***
https://auth0.com/blog/developing-real-time-web-applications-with-server-sent-events/
SSE-tutorial-auth0.com-Developing Real-Time Web Applications with Server-Sent Events.pdf
Pros
very efficient protocol, memory performance for event streams
W3C standard to return server results for client requests async
Cons
support UTF-8 data transfers only ( json docs ? )
Data Architecture Support for Services
Data Architecture Support for Integration
Spark
Camel
Airflow
Data Architecture Support for MDM
rajg - 12 best practices for MDM Data Governance
12 Best Practices For #MasterDataManagement
1 Any master #datamanagement solution requires the consolidation of master data objects from different systems.
2 In addition to the Content Consolidation scenario, Master Data Harmonization enables consistent maintenance and distribution of master data records – focusing on global attributes.
3 Maintaining a subset of master data attributes is sometimes insufficient. Therefore MDM also supports the central maintenance of a complete object definition, including dependencies to other objects, on the master data server.
4 Use Content Consolidation to search for master data objects across linked systems
5 Use Content Consolidation to identify identical or similar objects
6 Use Content Consolidation to cleanse objects as needed
7 Use Business context grouping to determine which data objects belong together in a business sense.
8 Use Client-specific data control to control data at the local level so that individual systems can receive only the data they need, only at the time they need it.
9 Use capabilities to synchronously check for the existence of duplicates during master data maintenance in a way that safeguards #dataquality without interrupting time critical work.
10 Use workflows to check master data for accuracy and redundancy, enrich objects according to individual requirements, and release them for distribution.
11 To improve efficiency, automate distribution. This involves the use of event triggers, with target systems being determined according to the business context of the event.
12 Use the maintenance of a complete object definition including object dependencies in a centralized server for master data.
Source: PAT Research

Hibernate
GORM
Data Architecture Support for Security
Distributed Data Architecture
Sharding Strategies
disributed-db-sharding-strategies1.pdf
This article looks at four data sharding strategies for distributed SQL including algorithmic, range, linear, and consistent hash.
Data sharding helps in scalability and geo-distribution by horizontally partitioning data. A SQL table is decomposed into multiple sets of rows according to a specific sharding strategy. Each of these sets of rows is called a shard. These shards are distributed across multiple server nodes (containers, VMs, bare-metal) in a shared-nothing architecture. This ensures that the shards do not get bottlenecked by the compute, storage, and networking resources available at a single node. High availability is achieved by replicating each shard across multiple nodes. However, the application interacts with a SQL table as one logical unit and remains agnostic to the physical placement of the shards. In this section, we will outline the pros, cons, and our practical learnings from the sharding strategies adopted by these databases.
Data Driven Organization Maturity Levels
{kind=link}

Cloud Data Platform Design
https://livebook.manning.com/book/designing-cloud-data-platforms/brief-contents/v-1/
1 Introducing the Data Platform
2 Why a Data Platform and not just a Data Warehouse
3 Getting bigger and leveraging the Big 3 — Google, Amazon and Microsoft
4 Getting data into the platform
5 Organizing and processing data
6 Real time data processing and analytics
7 MetaData
8 Schema management
9 Cloud data warehouses
10 Serving and Orchestration Layers — Applications, BI, and ML
11 Cloud cost optimizations
Data Governance Concepts and Tools
https://profisee.com/data-governance-what-why-how-who/
data-governance-profisee.com-Data Governance What Why How Who 15 Best Practices.pdf
The Importance of Data Governance for All - Jim Mason
Linkedin comment on data governance importance
Corporations have recognized the importance of data governance for awhile for many reasons: standards & regulatory compliance, privacy, security, interoperability and, lately, a key value driver for success. Many governments are focusing heavily on data governance today as well. With the rise of automation, analytics, AI, DLT and IoT, the importance of data quality and governance is the key to success for any initiative using those technologies today. The disciplines for data quality and governance were historically high in manufacturing many years ago but all other sectors now value that focus.
India’s Data Governance Framework Policies Report
india-data-governance-framework-policy-2023.pdf link
What the Data Governance Program Objectives are
(a) To accelerate Digital Governance.
(b) To have standardized data management and security standards across whole of Government;
(c) To accelerate creation of common standard based public digital platforms while ensuring privacy, safety, and trust;
(d) To have standard APIs and other tech standards for Whole of Government Data management and access.
(e) To promote transparency, accountability, and ownership in Non-personal data andDatasets access. For purposes of safety and trust, any non-personal data sharing by any entity can be only via platforms designated and authorised by IDMO.
(f) To build a platform that will allow Dataset requests to be received and processed.
(g) To build Digital Government goals and capacity, knowledge and competency in Government departments and entities.
(h) To set quality standards and promote expansion of India Datasets program and overall non-personal Datasets Ecosystem.
(i) To ensure greater citizen awareness, participation, and engagement.
Data Governance Goals - Security, Compliance, Value, Quality - - SCVQ
This means that organizations who successfully do this consider the who – what – how – when – where and why of data to not only ensure security and compliance, but to extract value from all the information collected and stored across the business – improving business performance.
According to the 2019 State of Data Management, data governance is one of the top 5 strategic initiatives for global organizations in 2019. Since technology trends such as Machine Learning and AI rely on data quality
Data Governance Processes - Strategic and Tactical
The key instrument for establishing a sustainable data strategy is data governance. This provides the framework for how an organization “ consciously ” wants to use data and what value data has for the organization, how data can be protected and how compliance - compliant handling is regulated. In addition, data governance is supported with a coordinated set of services, methods and tools actively the change to a data-oriented organization and enables them to constantly improve their data intelligence.
What are the building blocks of data governance?
There is no standard which components or topics are included in data governance.
Data interoperability
Establish policies and procedures that enable the organization to design information systems so that s data can be used consistently across and beyond the boundaries of silos
Data Model
Establishing principles and requirements for the development, maintenance and implementation of a standard data model
Data scope
Establishing policies and procedures for evaluating and prioritizing high value and high-risk data.
Data Accountability Partnership
Defining the responsibility of data in roles along the data lineage and empowering people to fill their role and act accordingly
Data Catalog
The data catalog provides a central view of metadata to facilitate traceability of the origin and use of data assets within the organization.
•A “data lineage ” within the data catalog provides information about the use, processing, quality and performance of data throughout its life cycle, from initial creation to subsequent deletion.
•The "Shopping for Data" approach enables the value-oriented and democratized use of data.
Data quality
Establishing principles and procedures to enable a value-based view, control and quality assurance of data with regard to correctness, relevance and reliability, depending on the purpose that the data is intended to fulfill in a specific context .
Data sharing
Enables data assets to be reused with valid business justification, both internally and externally, based on established policies and procedures.
Data retention, archiving, decommissioning
The data must be archived and deleted in accordance with the relevant data protection policies, regulations and procedures.
Source: Business Information Excellence

Data Governance Management Concepts
nformation services based on Big Data #analytics require data governance that can satisfy needs for corporate governance. While existing data governance focuses on data quality but Big Data governance needs to be established in consideration of a broad sense of Big Data services such as analysis of social trends and predictions of change. To achieve goals of Big Data services, strategies need to be established with alignment to the vision of the corporation. For successful implementation of Big Data services, there is needed a framework to enable initiation ofa Big Data project as a guide and method. We propose the Big Data Governance Framework to facilitate successful implementation in this study.
Big Data governance framework presents additional criteria from existing data governance focused on data quality level. The Big Data governance framework focuses on timely, reliable, meaningful, and sufficient data services. The objective of Big Data services is what data attributes should be achieved based on Big Data analytics. In addition to the quality level of Big Data, personal information protection strategy and data disclosure/accountability strategy are needed to prevent problems.
This study conducted case analysis about the National Pension Service (NPS) of South Korea based on the Big Data Governance Framework we propose. Big Data services in the public sector are an inevitable choice to improve quality of life of people. Big Data governance and its framework are essential components for the realization of Big Data services’ success. In case-analyses, we identified vulnerabilities or risk areas, and we hope that these case studies will be used as major references to implement Big Data services without problems.
Source: Hee Yeong Kim June-Suh Cho Hankuk University of Foreign Studies

another data governance model

Sustainable Data Concepts
sustainable data architecture concepts
Cloud Web DB Environment Concepts
My quick take on some of the criteria you mention for the different options:
Cloud servers don't create database corruption risks
The one point I don't agree with is corruption risks on cloud servers. Most databases ( MySQL, Postgres etc ) do not have corruption risks when properly configured. I've operated data centers at Fidelity and other companies. We don't see database corruption.
Cloud servers do have response risks but that's not significant
We see 1 second response now from our AWS cloud servers all day long for Web database applications. Does it ever go higher ? rarely. Is a local database server going to be faster? Yes but sub-second response is not a requirement for these applications clearly
Cloud server availability risks are less than a local server risks
All servers have availability risks. Yes cloud servers can have an outage that can prevent access but that's extremely rare and short term. The beauty of the cloud solution is the availability is higher over time than a local database server. Given the application and database, it makes more sense to run it from the cloud where the service is more reliable and accessible.
If you want a local backup of the Web app and the database on the Sea Colony office computer that can be done. Just a daily backup of the cloud database to the office system. That provides a simple disaster-recovery option locally as a fallback.
Cloud servers provide highly available, secure access
Admin access is secured
The database itself is secured and managed by admin access only. Access logs show any administrator access on the database as an audit trail. The same for the Web application server
Web application access is secured
The Web application runs on TLS encryption ( HTTPS ) with digital certificate to ID the server correctly.
In addition the Web application will allow only registered users access and the user access is also logged as an audit trail.
Only designated administrators will approve user access requests to the Web application.
Web application can serve public information as needed
If there is information that is not private and access controlled ( eg Sea Colony community photos etc ), that content can be served without requiring user login. Public content will still use TLS encryption to reduce the threats of hackers etc.
Database design based on your proposed model
I think it's not hard to create a multi-user Web app for a set of authorized users with a common database like MySQL. That allows any authorized user to access the app at any time from any device.
Your starting data model concept makes sense on the tables, content. I can create a data model this weekend for MySQL to look at. We can revise it as needed based on feedback from the team.
I'd like to get input from all on these issues.
SWT Real-time Data Mesh Architecture for multiple use cases: automated operations dashboard, AI model tuning
As lead data architect, desgned a data mesh to support 2 completely different use cases in a single data mesh for a large company Customer Call Center solution
MySQL was selected as the database: enterprise open-source, high speed and scale, wide usage, excellent SQL standard support, wide variety of tools
MySQL was used for both the ODS ( Operational Data Store ) and the Federated Data Warehouse
Data Mesh Concepts
Custom data services layers were created to:
Perform high speed, data validation and loads from the data lake to the ODS
Continuously query, transform, aggregate, load new data from the ODS to the data warehouse
A standard data transformer template was created in to rapidly generate procedures to load the warehouse from the ODS
developers created 2 SQL statements and added them to the template to generate the procedures in MySQL - a select and an upsert statement
ODS - Operational Data Store
the ODS supported 2 completely differently use cases
use case: real-time operations dashboard
high-speed, real-time operations dashboard graphics with data alerts for performance exceed SLIs defined by data policies
the goal was every call would be included in the aggregated data results within 120 seconds after the call completed
use case: data management to tune AI models for voice recognition
Federated Data Warehouse
Highcharts was the the BI tool used to generate all dashboard UI
built in data services reduced the need for data transformations by the BI team - they just made simple queries to the provided views or procedures
the data services layer views provided high performance indexed views of the warehouse data aggregates
for complex, real-time query generation, simple procedure calls initiated a data transformation workflow with reusable and shared data frames for performance that eliminated the need to use typical data transformation libraries for languages like Python
2 different use cases for a data mesh
ingestion sources >> an omni-channel data lake with 90% of the transactions coming from IVR nodes with customer call voice recognition, 10% from messaging apis
Rabbit MQ was the messaging backbone connecting IVR nodes and receiving messages from other systems
Java JDBC high speed loaders loaded the ODS from the message streams ( batch fetch ) that gave an 800% improvement over prior Hibernate loader
ODS >> Operational data store ( MySQL )
Accomodated up to 1 billion new rows per day in the design
The Java loaders wrote in bulk to the transaction tables, a control table tracked the process status of the related transaction tables ( similar to blockchain without hashes)
The data model for the AI voice recognition was very complex ( snowflake with 6 total levels )
The top level was the call record or instance
The ODS did not allow updates on the primary transaction tables to improve load speed
The ODS was idempotent supporting replay by batch using the control table
AI scientists could select any batches from the control table based on filters to replay
Replay purged the transaction records and reran the related batches using the control table
This allowed unlimited tuning of AI models
The replay processes ran at a lower priority in MySQL than the new data loads ensuring those had priority performance for operations analytics dashboard
The mulitple priority models high utilitization of server capacity effectively
The BCP model used MySQL binary log as the designated commit point for transactions which guaranteed RPO of 100% with a reasonable RTO
Potential Value Opportunities
Potential Challenges
Candidate Solutions
MDM - Master Data Management
MDG - Master Data Governance
Sample Data Services Pipeline Solution - Teallium
https://3j3fcqfu91e8lyzv2ku31m63-wpengine.netdna-ssl.com/assets/pdf/tealium_overview.pdf

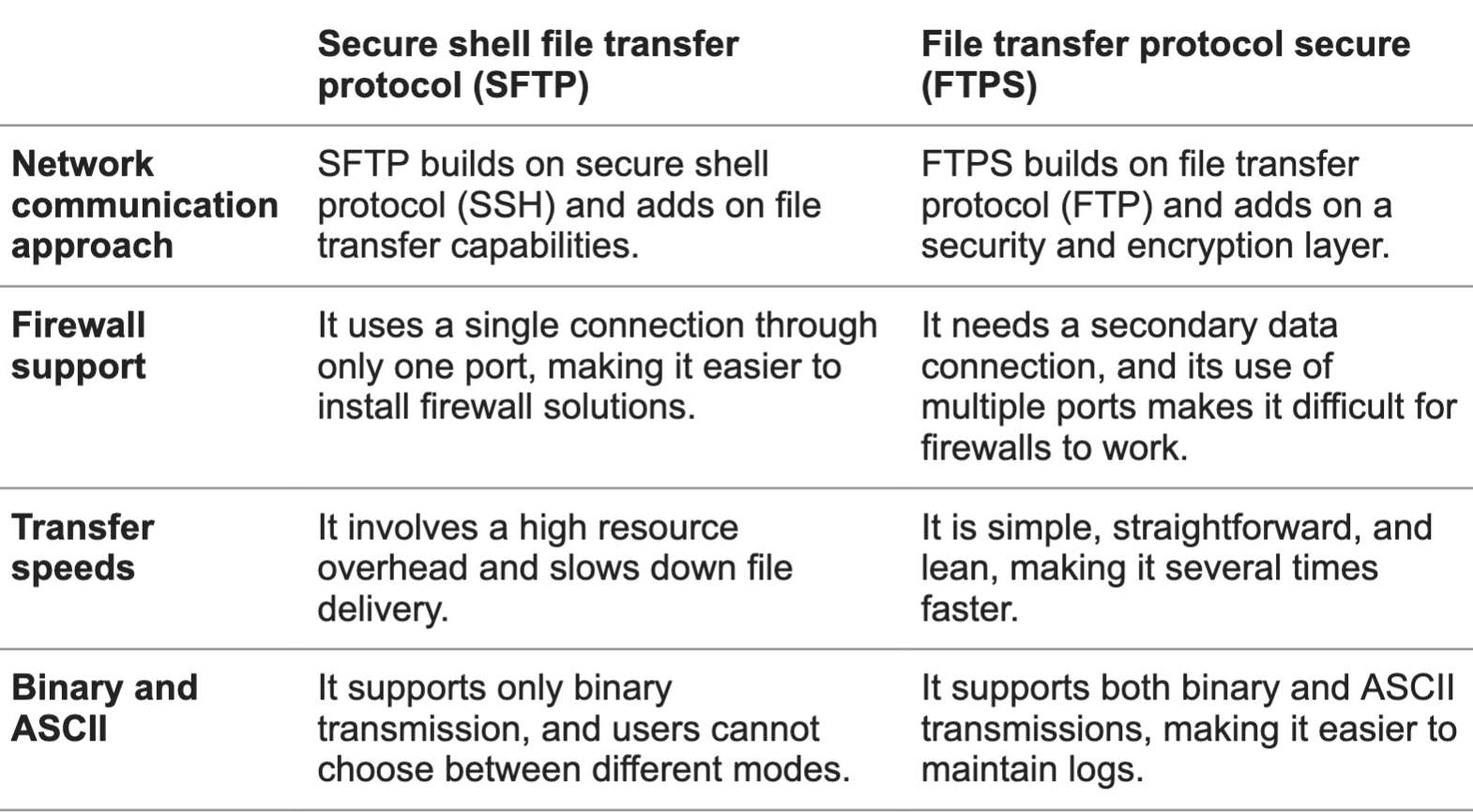
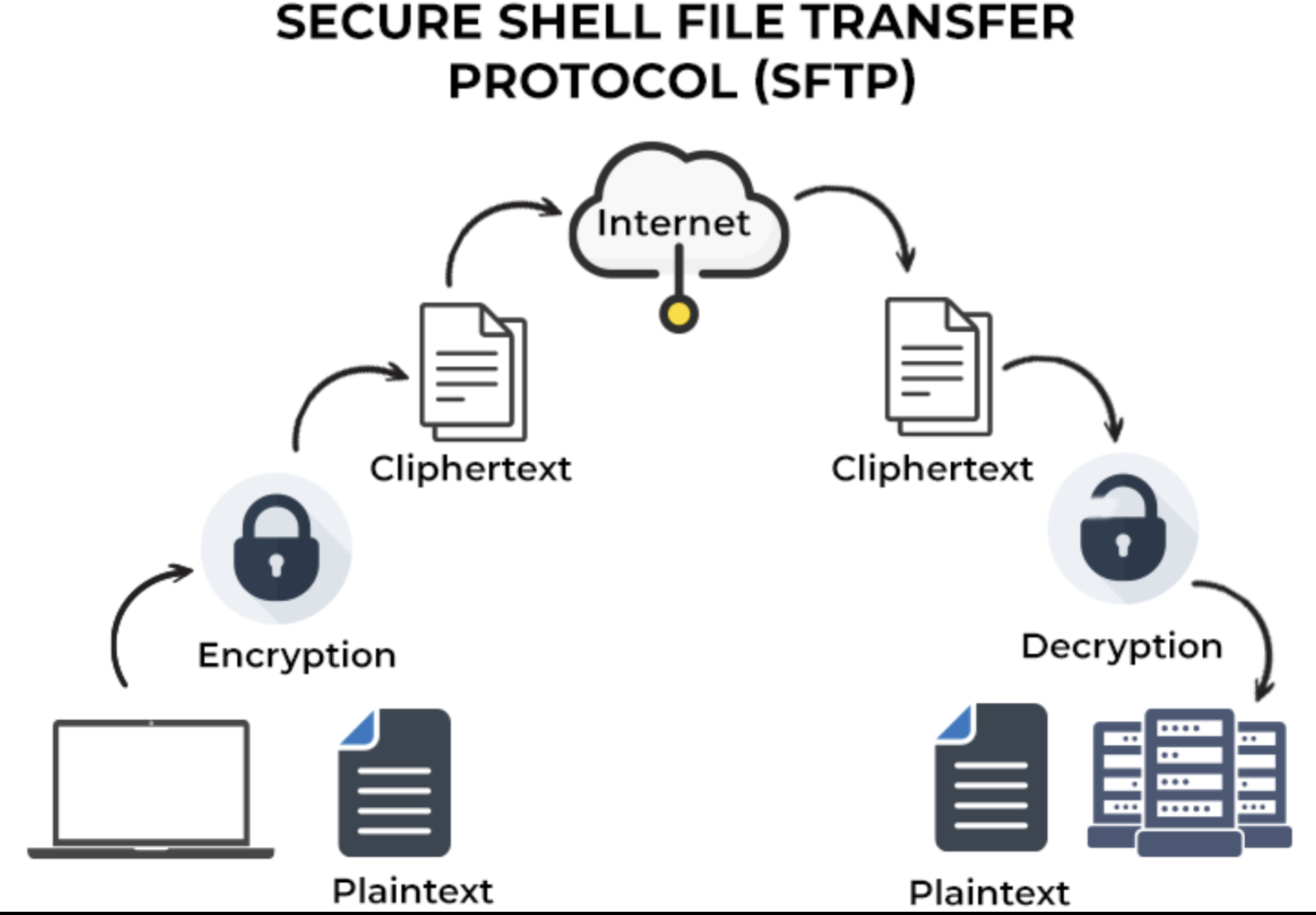
SFTP secure shell vs FTPS encrypted ftp explained

Step-by-step guide for Example
sample code block