Decision Mgt and Rules Engines
- jim mason
- jimm1
Key Points
- basic delivery process: assessment = reqmts, design = design, build = develop, test, implement, support
- Software delivery steps for new solutions: define > design > plan > deliver > test > implement > support
- different domains: business, system, data, services, infrastructure
- different metadata and modeling for domains - are repositories reusable? how?
- different tools for modeling in a domain
- object-oriented design is the natural method of expression for systems concepts - goes back 50,000 years
- CAC is more important than inheritance ( Composition, Association, Collaboration ) in OO models and runtimes
- Use diagrams or pseudo code ?
- diagrams done right can say a lot but generally have a high cost to create and maintain
- pseudo code can be expressive if done right with the right levels of abstraction and using user terminology but may not be as communicative as diagrams
- Architecture standards: TOGAF, ITIL, BIAN, UML
- Agile concepts - Agile, SAFE, Scrum, Programs, Releases, Sprints, Epics, Stories, Use cases, Test cases
- Project Management Keys - business, project, technical, resources
- Enterprise Architecture provides support throughout solution delivery process for new and existing projects
- solution architecture supports functional requirements
- enterprise architecture supports non-functional requirements
- While each system should be designed with the appropriate design models and processes it is common to have:
- user journey flow for each key user type in the system showing the: pains, delights, decisions and feelings a user has over key system interactions
- if the new system is a replacement or upgrade, show both the old and new user journeys to understand the net impact for each audience
- key system process flows rows for process states / events, columns for key actors, top level system apis, top level shared DB updates
- for a distributed system, may need to show multiple systems ( eg a supplier and a consumer system etc )
- user journey flow for each key user type in the system showing the: pains, delights, decisions and feelings a user has over key system interactions
- Where possible, build visual models from specifications vs diagrams
- good tools create models from code and generate code from models
- at a minimum, good tools at least generate the related test cases
- diagrams are just pictures
- good tools create models from code and generate code from models
References
Key Concepts
Jim Change Management Concepts
3 work areas: support, operations, projects
Project Life Cycle: 3DIMS
- New or Existing Solutions
Define, Design, Plan, Deliver, Implement, Measure, Support
- Define current system and the need for change, vision, scope, requirements, change concepts and strategies ( POT? )
- Design the new solution - ( POC? or POV? ) - journeys, processes, metrics, services, solutions, executable test cases
- Plan the solution given a concrete design - deliverables, teams, roles, scope, success metrics
- Deliver - SAFE or Agile processes, environments, test cases, 3B resources ( borrow, buy, build ), test
- Measure - measure actual results against expected KPI's
- Support and Improve
Project Management
- GAPS - Goals, Assumptions, Problems, Solutions
- OARS - Objectives, Assumptions, Reviews, Steps
Success Factors - VCRS -
- Value, Cost, Risks, Support
Impact and Opportunity Factor Assessment - FACTUR3DT.IO
- Feelings, Accuracy, Cost, Timeliness, Utility, R3 ( Risks, Resources, Revenues ),
- I = the input ( current state ). O = the output or target state
Architecture Themes
BOCETSSSMQT
- BPE - Business Process Engineering
- CIP - Continuous Improvement Process Team
- CDS - Customer Driven Solutions
- EOS - Enterprise Open-Source
- TDD - Test Driven Delivery
- SDS - Smart Data Services
- SSM - Smart Service Management
- SOE - Service-Oriented Engineering
- SDD - Sprint Driven Delivery
- MDG - Model Driven Generation
- QMS - Quality Management Services
- T3 - Right Tools, Training and Talent
- VE - Validate Everything - trustless model
- VCN - Value Chain Networking analysis model for each role ( network value map )
In-sourcing with Quick Web Workshops
As a technology consultant I didn't have a skilled work force to run digital transformation projects so I "in-sourced" instead of "out-sourcing". My father used to say: "Consultants borrow your watch to tell you the time". I modified that to "I'll borrow your workforce to get this new project done".
I engineered projects so that I could train the workforce in a week or two to deliver a large part of the project. I would automate other parts of the deliverable where possible.
The end result? I had a very knowledgeable, motivated team that picked up new skills, understood the business and current systems well and was ready to support the delivered solution. Not rocket science.
Top level design artifacts
Where possible, create models vs diagrams
models can be visual but can also generate code ( eg UML to DDL etc )
Software Tiers and Layers
Business Use Case Model
Defines business scope and use case list
If needed, represent key use case relations and dependencies
Business Context Layer Model
key business processes modeled for top level use cases
Maybe business context diagrams for key use cases
Typically shows multiple participants ( businesses or departments depending on scope ) in the VCN
Highlights VSM events
Application Services Layer Model
Top level User - System interaction models
B2B interaction models for B2B processes
Information owners, producers, consumers, SOR - systems of record, distribution, synchronization, CTE - event subscriptions, handlers
Platform Services Layer Model
may be implemented as components, libraries or services
Infrastructure Services Layer Model
normally implemented as runtime environments and management services
Physical environments
Domain Driven Design
https://en.wikipedia.org/wiki/Domain-driven_design
Need Domain experts
G3 - Grails, Gorm, Groovy
add reverse engineering script from database schemas
https://martinfowler.com/tags/domain%20driven%20design.html
https://techbeacon.com/app-dev-testing/get-your-feet-wet-domain-driven-design-3-guiding-principles
Enterprise Architecture - Tiers and Layers View
aka the "stack" view of producers and consumers
logically layered from
business model
VSP - value stream process model
incorporates both activities and decisions participants make
app model
services model
decision model
information model
infrastructure model

Solutions evolve over time from new or changed business or infrastructure requirements
This is an update to the simple 4 domain TOGAF architecture
lays the foundation for AI, RI, VCN etc
Data Model for Key Entities and Relations
For Key Process Objects, id key states / events
Conceptual Features to cover in design
Epics cover
Context: user ( or organization ) wants, needs, sees, hears, knows, does, gets results
Stories: detail epic inputs, process, decisions, actions and outcomes as events for all parties
Conceptual Model Diagrams ( Current or Future State )?
The most effective tool in the Wittij Consulting interviewing toolkit is a diagramming activity.
We provide a case study, notation guidance, and some basic instructions to model something (details depend on the role). Many elements of it will be things that do not yet know. We ask people to spend no more than an hour working on it and submit it to us as if we were their client. It is not a graded pass/fail activity, but the next step in a discussion.
It is soooooo USEFUL!
1. Shows what someone can do vs. what they can say. Helps us figure out who is a good interviewer vs. who is good at what we do.
2. Gives people applying a taste of what they will be doing if they come onboard. Some take a look and decide it isn't for them!
3. Creates opportunities to see how someone researches, follows instructions, coordinates, delivers, communicates, and takes feedback.
It is so much more useful than an online test. Those help you learn what someone already knows. Obviously, someone needs to have the right foundational knowledge for a role, but how they figure out new things and deliver results is so much more important.
We recommend it for many roles, but definitely for our clients looking for Enterprise and Solution Architects, where visual abstraction is a critical skill
Current and Future State Analysis
- Document systems, actors, goals, key metrics, system flows, entities, entity life cycles, key events, key decisions, transaction flows, data models, analytics models, GRC solutions
- Document who and why change is needed
- Document concepts for change - what, why, how, who, when, how much, why not
- FACTUR3DT.IO analysis on issues and opportunities for new state
- Feelings, Accuracy, Costs, Timeliness, Utility, Risks on Impacts and Opportunities
- Review existing system models as context for new system
- Model the new system and related infrastructure changes
- Consider architecture themes: BPM, OIP, EOS, CDS, TDD, SDM, SSM, SOE, QM, MDG, T3
- Review sponsors, champion visions, commitments to the change
- Define goals, responsibilities, objectives, metrics, acceptance criteria for project and operations, risk mitigation ( business, project, technology, resources )
Design: Build executable models of existing, proposed systems to validate differences, benefits, changes
Design concept document notes gdoc
Design process
- Define the business context.
- Define the business Network.
- Define the roles within the business Network.
- Define the goals and capabilities for each role in the network.
- Define the business case for each role
- Define the subsystems that cover the network capabilities.
- Define the relations to other subsystems as producers, consumers or both
- Within each subsystem Define:
- Define the use cases for each role to support the goals and capabilities.
- Define for each use case the process And the related events and listeners
- Define the object model to support each use case.
- For each object, Define the object purpose, relations, life cycle, key attributes
- Define the component services it support use case processes and the object model
- Source component services internally and externally
- Define the components service interfaces as actions, request, responses , events
- Define how component services are Discovered, Hired, registered, unregistered
- For external services, Define the service action interfaces and events as well as available data streams
Simple Design Process Model: RDD Capabilities
for a given domain sbs
xuc > goals > actors > capabilities > jepl services > object model > data model erd
interfaces to other domain sbs
data models for domain
reference data
metadata
entity master data
entity transactions
entity history
Thanks. Nice article on the basics of information and data flows.
I also use event sequence diagrams to show responsibilities, key events for flows which help define decision points and routes.
Design concept document notes gdoc
Object Design Models for requirements
- natural method to specify structure, behavior, responsibilities, capabilities with metadata support
- supports natural system modeling from a user view
- supports round-trip engineering using metadata
- primary interaction methods: composition, association, collaboration
- inheritance and typeOf are optional constructs to use only in the right use case
Digital Transformation Concepts
https://www.slideshare.net/KelltonTech/api-strategy-with-ibm-api-connect

Enterprise Architecture
Defines the overall architecture for business information systems.
Focuses on the non-functional requirements for solutions
Provides a long-term model for managing IT
Tiers and Layers models of business information systems
- Layers: business > applications > services > data flows > network > stores > assets
- Tiers: client > network > server
Value Analytics
Value Stream Mapping for a process
https://www.lucidchart.com/pages/value-stream-mapping
https://drive.google.com/open?id=1bpoWVlnQob4SuNMkybIISqGqperneJmO
Value Chain Networking for independent entities
key design method for any blockchain network
See FACTUR3DT.IO analysis for before and after impacts
User Journeys
Beginner's Guide to User Journeys
https://uxplanet.org/a-beginners-guide-to-user-journey-mapping-bd914f4c517c
The 8-steps process of user journey mapping
Choose a scope. ...
Create a user persona. ...
Define scenario and user expectations. ...
Create a list of touchpoints. ...
Take user intention into account. ...
Sketch the journey. ...
Consider a user's emotional state during each step of interaction. ...
Validate and refine user journey.
User Journey Template

User Journey Decision Model Extension - SWT - add decisions to pain points, delights, feelings
User Journeys show the user's
- pain points
- delight moments
- feelings
Now add user decision points
at each step
- model the decisions the user makes
- define the input data for each decision
- define the algorithms for the decision
User Journeys and User Flows
https://medium.com/sketch-app-sources/user-journey-maps-or-user-flows-what-to-do-first-48e825e73aa8
user-flows-medium.com-User Journey Maps or User Flows what to do first.pdf
User Flows
User Flows focus on a path often actions to perform. Makes easy to validate if the solution’s processes are complete. User Flows make the solution easy to understand to the team almost instantly.
UX Flow may not be linear — it contains decision nodes, paths, modes, and loops that show all possible interactions with the product.
Usually flows do not focus on users feeling or multiple layers of the solution. Their main purpose is to visualize the flow through the solution.
User Journeys
Journey Maps focus on more on the experience of the customer, try to detect pain points or moments of delight. They may focus on different aspects of a solution, not only the mobile app but also the back-end server.
While User Flows have got more formal rules (probably because their flowchart origins), Customer Journey Maps are very various. There are examples around the web of maps that are very different from each other.
TOGAF - The Object Group Architecture Framework
https://www.opengroup.org/togaf
TOGAF introduction
http://www.opengroup.org/library/w182
TOGAF reference cards
https://publications.opengroup.org/n180

TOGAF concepts
togaf-concepts-2018-cio-mag.pdf
TOGAF overview
TOGAF_oveview_2007_Lankhorst.pdf
Archimate modeling language
The ArchiMate® modelling language is an open and independent Enterprise Architecture standard that supports the description, analysis and visualisation of architecture within and across business domains. ArchiMate is one of the open standards hosted by The Open Group® and is fully aligned with TOGAF®. ArchiMate aids stakeholders in assessing the impact of design choices and changes.
archimate 3.0 spec
https://publications.opengroup.org/c179

business structure


application behavior

Process dependency relationships

Archi modeling tool - the TOGAF modeling tool
https://www.archimatetool.com/
The Archi® modelling toolkit is targeted toward all levels of Enterprise Architects and Modellers. It provides a low cost to entry solution to users who may be making their first steps in the ArchiMate modelling language, or who are looking for an open source, cross-platform ArchiMate modelling tool for their company or institution and wish to engage with the language within a TOGAF® or other Enterprise Architecture framework.
Base Archimate is now open-source software

BPM software toolsets
https://www.techjockey.com/blog/free-open-source-bpm-software-businesses-2019
Archimate is free and linked to TOGAF models
Which are diagramming vs modeling tools??
Modeling tools are machine readable outputs that can be used by generators ( eg think SQL DDL etc )
Diagrams don't have a machine readable format useful for software generation tools
In a services architecture, which comes first - the service or the process?
depends on how services are implemented.
If there are no agents providing top-level process flows, then the client application is the top process level and services are typically microservices
In an agent architecture, an agent may manage an entire business process flow for the client
generally microservices will provide a flexible, modular archtiecture for assembly of functions by a parent service or application
The challenge with microservices is assembling all the data and function a service needs in a reusable manner
Other open-source tools include:
- Red Hat Process Automation Manager
- Alfresco Process Services
- Modelio
- Camunda
- RunaWFE
- jBPM
- Activiti
- Joget
- jSonic BPM
- Bonitasoft BPM
- Adobe LiveCycle
- ARIS Express
- Bizagi
- ProcessMaker
- Orchestra
- Cubetto
- ARCWAY Cockpit
- SYDLE SEED
- Visio
- Lucidchart
UML Basics
https://tallyfy.com/uml-diagram/
Behavioral UML Diagram
- Activity Diagram
- Use Case Diagram
- Interaction Overview Diagram
- Timing Diagram
- State Machine Diagram
- Communication Diagram
- Sequence Diagram
Structural UML Diagram
- Class Diagram
- Object Diagram
- Component Diagram
- Composite Structure Diagram
- Deployment Diagram
- Package Diagram
- Profile Diagram
Class Diagram
- UML Class - Like CRC card - name, purpose, attributes, behaviors, implements
- attributes and methods are public, private or protected
- Class relationships - uses, consumes, produces, inherits - shows cardinality, role names
- association shows direction - A to B, B to A, both A B
- composition shows a diamond arrow
Composition is a strong association in which the part can belong to only one whole -- the part cannot exist without the whole. Composition is denoted by a filled diamond at the whole end.
Aggregation is a kind of "light” composition (semantics open, to be accommodate to user needs). Aggregation is denoted by a empty diamond at the whole end

A dependency is a relation between two classes in which a change in one may force changes in the other. Dependencies are drawn as dotted lines.
A constraint is a condition that every implementation of the design must satisfy. Constraints are written in curly braces { }.

Object diagrams
Object diagrams show instances instead of classes. They are useful for explaining small pieces with complicated relationships, especially recursive relationships.
Each rectangle in the object diagram corresponds to a single instance. Instance names are underlined in UML diagrams.
Class or instance names may be omitted from object diagrams as long as the diagram meaning is still clear

Action Diagrams
Sequence Diagrams
Thanks. Nice article on the basics of information and data flows.
I also use event sequence diagrams to show responsibilities, key events for flows which help define decision points and routes.
https://en.wikipedia.org/wiki/Sequence_diagram
Component Diagrams
Deployment Diagrams
Conceptual Architecture Diagram
Combines Deployment and Action for use case Actors
Other UML Diagrams
Timing Diagrams
JEPL - Jims ( Java ) Event Process Language
simple object-based process flows based on events, outcomes
event / condition > actor > actions > outcome events / conditions
the events / condition step can reference other outcome labels as input events
creates a static flow
to view real sequences, need to execute groovy dynamic models using DSL and expando with default printString outputs to console
works ok for conceptual system process flows
JEPL process design flows template
attached old version
gdrive new version
gsheet template
an Inspection Process JEPL Flow example
https://drive.google.com/file/d/1FLCekj72xrrOtTis1ZL0TkqnQKFYlX42/view?usp=sharing
gsheet
related BPM diagram for a JEPL Flow
_mobi_vid2-inspection-flow.jpg
{kind=link}

REST API Design
https://www.guru99.com/soa-principles.html SOA principles summary
https://swagger.io/docs/ OpenAPI for REST design docs
m REST API design and tools OpenAPI details
Flowchart Basics
https://en.wikipedia.org/wiki/Flowchart
Flowchart symbol cheat sheet
https://www.breezetree.com/articles/flow-chart-symbols
Flowchart symbol types


types of flowcharts
Decision flowcharts, logic flowcharts, systems flowcharts, product flowcharts, and process flowcharts are just a few of the different types of flowcharts that are used in business and government
BPM example
https://en.wikipedia.org/wiki/Business_process_mapping

State life cycle diagrams
https://en.wikipedia.org/wiki/State_diagram
good for MDM and transaction state ( eg orders, shipments etc )

Data flow diagrams
https://en.wikipedia.org/wiki/Data-flow_diagram
When using UML, the activity diagram typically takes over the role of the data-flow diagram.




Data Dissemination Diagrams
https://www.togaf-modeling.org/models/data-architecture/data-dissemination-diagrams.html
show the relationship between data entities, business services, and application components. The diagram shows how the logical entities are to be physically realized by application components

ERD - Entity Relationship Diagram
used to show relationships between data or object types
Action Diagram example 1
vertical swim lanes for actors
show process steps and decision routes

Activity Diagrams for process & decision flows
https://en.wikipedia.org/wiki/Activity_diagram
combine functional flowchart and data flow ( or state ) diagrams
Activity diagrams are constructed from a limited number of shapes, connected with arrows.[4] The most important shape types:
- ellipses represent actions;
- diamonds represent decisions;
- bars represent the start (split) or end (join) of concurrent activities;
- a black circle represents the start (initial node) of the workflow;
- an encircled black circle represents the end (final node).
Arrows run from the start towards the end and represent the order in which activities happen.
Can be useful for decision flows

BPM modeling methods
https://tallyfy.com/business-process-modeling-techniques/
using business process modeling techniques:
- You can spot tasks that are redundant and eliminate them.
- You can improve process efficiency by looking for areas where work gets held up because of bottlenecks in the process.
- You can ensure that efficient processes are repeated in the same way every time, even when a new staffer must perform part of the process.
BPMN
- Flow objects:
Events are represented by circles, activities fit into rectangular boxes with rounded corners, and gateways or control points are represented with diamond shapes. - Connecting objects:
Since tasks are interconnected, we join them up to show their sequence. Solid lines indicate task transfers, and dashed ones indicate messages. - Swim lanes:
A single sub-process in your workflow could require the sharing of responsibility. Swim lanes detail how these shared responsibilities are distributed and how they interact. The sub-task is the “pool” and the “lanes” represent people or departments. Artifacts:
If you need to add extra information that isn’t a sequence flow or message flow but that helps to explain a process, you can use artifacts. Dotted lines point to the flow object the extra information expands on. Squares outlined with dots and dashes group elements in the diagram, and text annotations are added with a square bracket.
Business Process with Swim lanes for Responsibilities

System Process Flow with Infrastructure Tiers and Process Step Layers
Note: normally this system process flow would have the infrastructure tiers as shown but would have major process sequences vertically,

BPM with Artifacts

Data Flow Diagrams for a Process
For given process, connect:
Entities, processes, information flows, events
Book a room example

Functional Flow Diagrams
focus is the order of execution of tasks or functions in a sequence of ordered blocks.

Can break down to HIPO - hierarchical input process output diagrams

Gantt Chart
summarizes major tasks in time period sequence to reflect start, stop times and dependencies

PERT Chart
Program Evaluation and Review Technique (PERT) diagrams, which seek to break business process flows into timelines by estimating the shortest, longest, and likeliest times for the completion of each step in a business process.
helpful in setting goals and targets and in comparing different process approaches to determine which will be more efficient

Rules Engines
Drools - EOS Rules Engine, Workbench
https://docs.jboss.org/drools/release/7.31.0.Final/drools-docs/html_single/index.html
https://github.com/kiegroup/drools
Drools is a Business Rules Management System (BRMS) solution. It provides a core Business Rules Engine (BRE), a web authoring and rules management application (Drools Workbench), full runtime support for Decision Model and Notation (DMN) models at Conformance level 3 and an Eclipse IDE plugin for core development.
An open source rule engine, DMN engine and complex event processing (CEP) engine for Java™ and the JVM Platform.
Drools is a business rule management system with a forward-chaining and backward-chaining inference based rules engine, allowing fast and reliable evaluation of business rules and complex event processing. A rule engine is also a fundamental building block to create an expert system which, in artificial intelligence, is a computer system that emulates the decision-making ability of a human expert.
Drools is open source software, released under the Apache Software License. It is written in 100% pure Java™, runs on any JVM and is available in the Maven Central repository too.
More information can be found on the following links:
 Drools Workbench (web UI for authoring and management)
Drools Workbench (web UI for authoring and management) Drools Expert (business rules engine)
Drools Expert (business rules engine) Drools Fusion (complex event processing features)
Drools Fusion (complex event processing features) jBPM (process/workflow integration for rule orchestration/flow)
jBPM (process/workflow integration for rule orchestration/flow) OptaPlanner (automated planning)
OptaPlanner (automated planning)
These projects have community releases from JBoss.org that come without support. Community releases focus on fast paced innovation to give you the latest and greatest, with releases every few months that include both features and fixes. Red Hat JBoss BRMS is our enterprise product for mission critical releases,
KIE - Knowledge is Everything Suite
https://github.com/kiegroup/drools
KIE (Knowledge Is Everything) is an umbrella project introduced to bring our related technologies together under one roof. It also acts as the core shared between our projects.
KIE contains the following different but related projects offering a complete portfolio of solutions for business automation and management:
Drools is a business-rule management system with a forward-chaining and backward-chaining inference-based rules engine, allowing fast and reliable evaluation of business rules and complex event processing. A rules engine is also a fundamental building block to create an expert system which, in artificial intelligence, is a computer system that emulates the decision-making ability of a human expert.
jBPM is a flexible Business Process Management suite allowing you to model your business goals by describing the steps that need to be executed to achieve those goals.
OptaPlanner is a constraint solver that optimizes use cases such as employee rostering, vehicle routing, task assignment and cloud optimization.
Business Central is a full featured web application for the visual composition of custom business rules and processes.
UberFire is a web-based workbench framework inspired by Eclipse Rich Client Platform.
Apache JENA
https://jena.apache.org/index.html
https://jena.apache.org/documentation/inference/
jena-overview-jena.apache.org-Reasoners and rule engines Jena inference support.pdf
The Jena inference subsystem is designed to allow a range of inference engines or reasoners to be plugged into Jena. Such engines are used to derive additional RDF assertions which are entailed from some base RDF together with any optional ontology information and the axioms and rules associated with the reasoner. The primary use of this mechanism is to support the use of languages such as RDFS and OWL which allow additional facts to be inferred from instance data and class descriptions. However, the machinery is designed to be quite general and, in particular, it includes a generic rule engine that can be used for many RDF processing or transformation tasks.
We will try to use the term inference to refer to the abstract process of deriving additional information and the term reasoner to refer to a specific code object that performs this task. Such usage is arbitrary and if we slip into using equivalent terms like reasoning and inference engine please forgive us.
The overall structure of the inference machinery is illustrated below.
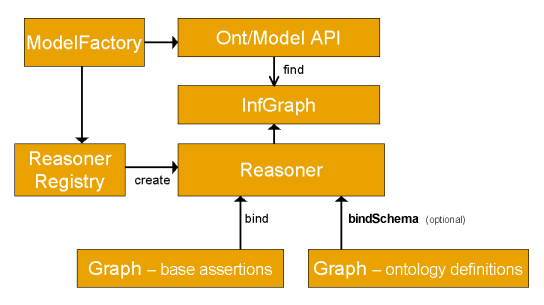
Applications normally access the inference machinery by using the ModelFactory to associate a data set with some reasoner to create a new Model. Queries to the created model will return not only those statements that were present in the original data but also additional statements than can be derived from the data using the rules or other inference mechanisms implemented by the reasoner.
As illustrated the inference machinery is actually implemented at the level of the Graph SPI, so that any of the different Model interfaces can be constructed around an inference Graph. In particular, the Ontology API provides convenient ways to link appropriate reasoners into the OntModels that it constructs. As part of the general RDF API we also provide an InfModel, this is an extension to the normal Model interface that provides additional control and access to an underlying inference graph.
The reasoner API supports the notion of specializing a reasoner by binding it to a set of schema or ontology data using the bindSchema call. The specialized reasoner can then be attached to different sets of instance data using bind calls. In situations where the same schema information is to be used multiple times with different sets of instance data then this technique allows for some reuse of inferences across the different uses of the schema. In RDF there is no strong separation between schema (aka Ontology AKA tbox) data and instance (AKA abox) data and so any data, whether class or instance related, can be included in either the bind or bindSchema calls - the names are suggestive rather than restrictive.
To keep the design as open ended as possible Jena also includes a ReasonerRegistry. This is a static class though which the set of reasoners currently available can be examined. It is possible to register new reasoner types and to dynamically search for reasoners of a given type. The ReasonerRegistry also provides convenient access to prebuilt instances of the main supplied reasoners.
BIAN - Banking Industry Architecture Network
https://www.bian.org/deliverables/
The BIAN model is based on a service-oriented architecture that defines the standard business capabilities that make up a bank- such as payments, loan offerings or trading facilities.
BIAN is in partnership with independent standards bodies such as Object Management Group (OMG) and The Open Group. In addition, BIAN has a ‘category D liaison’ with the International Organisation for Standardisation (ISO), for ISO 20022 semantic models.
The BIAN “How-to Guide” is a comprehensive set of documents. Aimed at audiences including technical architects, BIAN members and other financial institutions
Together this network of professionals is dedicated to lowering the cost of banking and boosting speed to innovation in the industry. Members combine their industry expertise to define a revolutionary banking technology framework that standardises and simplifies core banking architecture, which has typically been convoluted and outdated. Based on service oriented architecture principles, the comprehensive model provides a future-proofed solution for banks that fosters industry collaboration.
https://www.bian.org/deliverables/bian-how-to-guide/
The BIAN “How-to Guide” is a comprehensive set of documents. Aimed at audiences including technical architects, BIAN members and other financial institutions, the guides detail the theory and design practices behind the BIAN Service Landscape, the tools and templates used to capture content and directions for applying the BIAN Standard in your technical and business environment.
- BIAN How-to Guide – Introduction to BIAN v7.0
- BIAN How-to Guide – Design Principles Techniques v7.0
- BIAN How-to Guide – Developing Content v7.0
- BIAN How-to Guide – Applying the BIAN Standard v7.0
- BIAN How-to Guide – Semantic API V7.0
The “How-to Guide” gives organisations a toolset for using and implementing the BIAN model in their own organisations.
BIAN Service Message API Formats
https://static.bian.org/wp-content/uploads/2015/01/FINALBIAN_CMU_Final_Report.pdf
IDEF models - Integrated Definition
https://www.edrawsoft.com/what-is-idef.php
graphical Process Modeling Methodology used to implement systems and engineer software. These methods are used in data functional modeling, simulation, object-oriented analysis, and knowledge acquisition.
SOA - Service-Oriented Architecture
Principles
service-oriented architecture (SOA) is an architectural pattern in computer software design in which application components provide services to other components via a communications protocol, typically over a network
- Standardized Service Contract - Services adhere to a service description. A service must have some sort of description which describes what the service is about. This makes it easier for client applications to understand what the service does.
- Loose Coupling – Less dependency on each other. This is one of the main characteristics of web services which just states that there should be as less dependency as possible between the web services and the client invoking the web service. So if the service functionality changes at any point in time, it should not break the client application or stop it from working.
- Service Abstraction - Services hide the logic they encapsulate from the outside world. The service should not expose how it executes its functionality; it should just tell the client application on what it does and not on how it does it.
- Service Reusability - Logic is divided into services with the intent of maximizing reuse. In any development company re-usability is a big topic because obviously one wouldn't want to spend time and effort building the same code again and again across multiple applications which require them. Hence, once the code for a web service is written it should have the ability work with various application types.
- Service Autonomy - Services should have control over the logic they encapsulate. The service knows everything on what functionality it offers and hence should also have complete control over the code it contains.
- Service Statelessness - Ideally, services should be stateless. This means that services should not withhold information from one state to the other. This would need to be done from either the client application. An example can be an order placed on a shopping site. Now you can have a web service which gives you the price of a particular item. But if the items are added to a shopping cart and the web page navigates to the page where you do the payment, the responsibility of the price of the item to be transferred to the payment page should not be done by the web service. Instead, it needs to be done by the web application.
- Service Discoverability - Services can be discovered (usually in a service registry). We have already seen this in the concept of the UDDI, which performs a registry which can hold information about the web service.
- Service Composability - Services break big problems into little problems. One should never embed all functionality of an application into one single service but instead, break the service down into modules each with a separate business functionality.
- Service Interoperability - Services should use standards that allow diverse subscribers to use the service. In web services, standards as XML and communication over HTTP is used to ensure it conforms to this principle.
Key Documents by Project Stage
project-document-checklist-v1.xlsx
| define_________ | design_________ | plan___________ | build__________ | test___________ | implement________ | support___________ |
|---|---|---|---|---|---|---|
| vision and charter | design plan | delivery plan | build plan | test plan | implementation plan | support plan |
| assessment plan | epics, stories | resources | operations plan | |||
| assessment budget | user journeys | moscow priorities | management plan | |||
| current docs | entities, life cycles | delivery budget | ||||
| analysis | ERD | implementation budget | ||||
| use cases | system flows | support budget | ||||
| requirements | transactions events | |||||
| surveys | services | |||||
| incidents | infrastructure | |||||
| inventory | interfaces | |||||
| RACI table | architecture decision log |
ITIL version 2
The eight ITIL Version 2 books and their disciplines are:
The IT service management sets
1. Service Support 2. Service Delivery
Other operational guidance
3. ICT infrastructure management 4. Security management 5. Application management 6. Software asset management
To assist with the implementation of ITIL practices a further book was published (Apr 9, 2002) providing guidance on implementation (mainly of Service Management):
7. Planning to implement service management
And this has more recently (Jan 26, 2006) been supplemented with guidelines for smaller IT units, not included in the original eight publications:
8. ITIL small-scale implementation
Service support
The Service Support[33] ITIL discipline focuses on the User of the ICT services and is primarily concerned with ensuring that they have access to the appropriate services to support the business functions.
To a business, customers and users are the entry point to the process model. They get involved in service support by:
- Asking for changes
- Needing communication, updates
- Having difficulties, queries
- Real process delivery
The service desk functions are the single contact-point for end-users' incidents. Its first function is always to document ("create") an incident. If there is a direct solution, it attempts to resolve the incident at the first level. If the service desk cannot solve the incident then it is passed to a 2nd/3rd level group within the incident management system. Incidents can initiate a chain of processes: incident management, problem management, change management, release management and configuration management. This chain of processes is tracked using the configuration management database (CMDB), - ITIL refers to configuration management system (CMS), which records each process, and creates output documents for traceability (quality management). Note - CMDB/CMS does not have to be a single database. The solution can be Federated.
Service delivery
The service delivery[34] discipline concentrates on the proactive services the ICT must deliver to provide adequate support to business users. It focuses on the business as the customer of the ICT services (compare with: service support). The discipline consisted of the following processes:
- Service level management
- Capacity management
- IT service continuity management
- Availability management
- Financial management
ICT infrastructure management
Information and Communication Technology (ICT) management[35] processes recommend best practice for requirements analysis, planning, design, deployment and ongoing operations management and technical support of an ICT infrastructure.
The infrastructure management processes describe those processes within ITIL that directly relate to the ICT equipment and software that is involved in providing ICT services to customers.
- ICT design and planning
- ICT deployment
- ICT operations
- ICT technical support
These disciplines are less well understood than those of service management and therefore often some of their content is believed to be covered 'by implication' in service management disciplines.
12 Factor App Design
https://en.wikipedia.org/wiki/Twelve-Factor_App_methodology#The_Twelve_Factors
| # | Factor | Description |
|---|---|---|
| I | Codebase | There should be exactly one codebase for a deployed service with the codebase being used for many deployments. |
| II | Dependencies | All dependencies should be declared, with no implicit reliance on system tools or libraries. |
| III | Config | Configuration that varies between deployments should be stored in the environment. |
| IV | Backing services | All backing services are treated as attached resources and attached and detached by the execution environment. |
| V | Build, release, run | The delivery pipeline should strictly consist of build, release, run. |
| VI | Processes | Applications should be deployed as one or more stateless processes with persisted data stored on a backing service. |
| VII | Port binding | Self-contained services should make themselves available to other services by specified ports. |
| VIII | Concurrency | Concurrency is advocated by scaling individual processes. |
| IX | Disposability | Fast startup and shutdown are advocated for a more robust and resilient system. |
| X | Dev/Prod parity | All environments should be as similar as possible. |
| XI | Logs | Applications should produce logs as event streams and leave the execution environment to aggregate. |
| XII | Admin Processes | Any needed admin tasks should be kept in source control and packaged with the application. |
MVVM - front-end app pattern
https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel
Model–view–viewmodel (MVVM) is a software architectural pattern.
MVVM facilitates a separation of development of the graphical user interface – be it via a markup language or GUI code – from development of the business logic or back-end logic (the data model). The view model of MVVM is a value converter,[1] meaning the view model is responsible for exposing (converting) the data objects from the model in such a way that objects are easily managed and presented. In this respect, the view model is more model than view, and handles most if not all of the view's display logic.[1] The view model may implement a mediator pattern, organizing access to the back-end logic around the set of use cases supported by the view.
issues
for larger applications, generalizing the ViewModel becomes more difficult. Moreover, he illustrates that data binding in very large applications can result in considerable memory consumption.
MVC - front-end app pattern
https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller
Model–View–Controller (usually known as MVC) is an architectural pattern commonly used for developing user interfaces that divides an application into three interconnected parts. This is done to separate internal representations of information from the ways information is presented to and accepted from the user.[1][2] The MVC design pattern decouples these major components allowing for code reuse and parallel development.
Traditionally used for desktop graphical user interfaces (GUIs), this architecture has become popular for designing web applications.[3] Popular programming languages like JavaScript, Python, Ruby, PHP, Java, and C# have MVC frameworks that are used in web application development straight out of the box.
Model The central component of the pattern. It is the application's dynamic data structure, independent of the user interface.[4] It directly manages the data, logic and rules of the application.
View Any representation of information such as a chart, diagram or table. Multiple views of the same information are possible, such as a bar chart for management and a tabular view for accountants.
Controller Accepts input and converts it to commands for the model or view.[5]
In addition to dividing the application into these components, the model–view–controller design defines the interactions between them.[6]
- The model is responsible for managing the data of the application. It receives user input from the controller.
- The view means presentation of the model in a particular format.
- The controller responds to the user input and performs interactions on the data model objects. The controller receives the input, optionally validates it and then passes the input to the model.
Benefits
- High cohesion – MVC enables logical grouping of related actions on a controller together. The views for a specific model are also grouped together.
- Loose coupling – The very nature of the MVC framework is such that there is low coupling among models, views or controllers
- Ease of modification – Because of the separation of responsibilities, future development or modification is easier
- Multiple views for a model – Models can have multiple views
Issues
- learning curve
- too much boilerplate in some frameworks
Potential Value Opportunities
Draw.io Diagrams are free - web based
Potential Challenges
Candidate Solutions
BPM >> Process Mining For Dummies, Celonis.pdf. link
Process_Mining_for_Dummies_Final.pdf. file
Delivery Team factors impacting goals, organization

Agile Delivery
https://en.wikipedia.org/wiki/Agile_software_development
Agile Manifesto
Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan
That is, while there is value in the items on
the right, we value the items on the left more.
The Manifesto for Agile Software Development is based on twelve principles:[22]
- Customer satisfaction by early and continuous delivery of valuable software.
- Welcome changing requirements, even in late development.
- Deliver working software frequently (weeks rather than months)
- Close, daily cooperation between business people and developers
- Projects are built around motivated individuals, who should be trusted
- Face-to-face conversation is the best form of communication (co-location)
- Working software is the primary measure of progress
- Sustainable development, able to maintain a constant pace
- Continuous attention to technical excellence and good design
- Simplicity—the art of maximizing the amount of work not done—is essential
- Best architectures, requirements, and designs emerge from self-organizing teams
- Regularly, the team reflects on how to become more effective, and adjusts accordingly
| Practice | Main contributor(s) |
|---|---|
| Acceptance test-driven development (ATDD) | Kent Beck |
| Agile modeling | |
| Agile testing | |
| Backlogs (Product and Sprint) | Ken Schwaber |
| Behavior-driven development (BDD) | Dan North, Liz Keogh |
| Continuous integration (CI) | Grady Booch |
| Cross-functional team | |
| Domain-driven design (DDD) | Eric Evans |
| Iterative and incremental development (IID) | |
| Low-code development platforms | |
| Pair programming | Kent Beck |
| Planning poker | James Grenning, Mike Cohn |
| Refactoring | |
| Retrospective | |
| Scrum events (sprint planning, daily scrum, sprint review and retrospective) | |
| Specification by example | |
| Story-driven modeling | Albert Zündorf |
| Test-driven development (TDD) | Kent Beck |
| Timeboxing | |
| User story | Alistair Cockburn |
| Velocity tracking |
Agile Success Keys
- Focus on people over process
- Embed customers and their feedback in order to continuously improve
- Deconstruct work into small segments and organize effort into short chunks (typically called sprints) in order to get quick feedback and make nimble (agile!) course corrections
- Dedicate people to teams and focus on one project at a time
- Experiment and learn continuously
- Ensure transparency of the work and continuity of the team.
Agile Sprints
- Sprint plan
- epic and story development
- backlog review, dependency management and prioritization
- planning poker on selected stories
- create tickets for stories
- Sprint
- delivery - design, development, test
- scrum - daily standups > did, doing, blockers
- update tickets on stories, epics
- Sprint review
- review completed and in-progress work
- demos
- Sprint retrospective
- lessons learned
- improvement opportunities
Sprint Retro session
- What went well?
- What didn’t go so well?
- What have I learned?
- What still puzzles me?
Agile Pitfalls
Organizations and teams implementing agile software development often face difficulties transitioning from more traditional methods such as waterfall development, such as teams having an agile process forced on them.[88] These are often termed agile anti-patterns or more commonly agile smells. Below are some common examples:
Lack of overall product design
A goal of agile software development is to focus more on producing working software and less on documentation. This is in contrast to waterfall models where the process is often highly controlled and minor changes to the system require significant revision of supporting documentation. However, this does not justify completely doing without any analysis or design at all. Failure to pay attention to design can cause a team to proceed rapidly at first but then to have significant rework required as they attempt to scale up the system. One of the key features of agile software development is that it is iterative. When done correctly design emerges as the system is developed and commonalities and opportunities for re-use are discovered.[89]
Adding stories to an iteration in progress
In agile software development, stories (similar to use case descriptions) are typically used to define requirements and an iteration is a short period of time during which the team commits to specific goals.[90] Adding stories to an iteration in progress is detrimental to a good flow of work. These should be added to the product backlog and prioritized for a subsequent iteration or in rare cases the iteration could be cancelled.[91]
This does not mean that a story cannot expand. Teams must deal with new information, which may produce additional tasks for a story. If the new information prevents the story from being completed during the iteration, then it should be carried over to a subsequent iteration. However, it should be prioritized against all remaining stories, as the new information may have changed the story's original priority.
Lack of sponsor support
Agile software development is often implemented as a grassroots effort in organizations by software development teams trying to optimize their development processes and ensure consistency in the software development life cycle. By not having sponsor support, teams may face difficulties and resistance from business partners, other development teams and management. Additionally, they may suffer without appropriate funding and resources.[92] This increases the likelihood of failure.[93]
Insufficient training
A survey performed by VersionOne found respondents cited insufficient training as the most significant cause for failed agile implementations[94] Teams have fallen into the trap of assuming the reduced processes of agile software development compared to other methodologies such as waterfall means that there are no actual rules for agile software development.[citation needed]
Product owner role is not properly filled
The product owner is responsible for representing the business in the development activity and is often the most demanding role.[95]
A common mistake is to have the product owner role filled by someone from the development team. This requires the team to make its own decisions on prioritization without real feedback from the business. They try to solve business issues internally or delay work as they reach outside the team for direction. This often leads to distraction and a breakdown in collaboration.[96]
Teams are not focused
Agile software development requires teams to meet product commitments, which means they should focus only on work for that product. However, team members who appear to have spare capacity are often expected to take on other work, which makes it difficult for them to help complete the work to which their team had committed.[97]
Excessive preparation/planning
Teams may fall into the trap of spending too much time preparing or planning. This is a common trap for teams less familiar with agile software development where the teams feel obliged to have a complete understanding and specification of all stories. Teams should be prepared to move forward only with those stories in which they have confidence, then during the iteration continue to discover and prepare work for subsequent iterations (often referred to as backlog refinement or grooming).
Problem-solving in the daily standup
A daily standup should be a focused, timely meeting where all team members disseminate information. If problem-solving occurs, it often can only involve certain team members and potentially is not the best use of the entire team's time. If during the daily standup the team starts diving into problem-solving, it should be set aside until a sub-team can discuss, usually immediately after the standup completes. [98]
Assigning tasks
One of the intended benefits of agile software development is to empower the team to make choices, as they are closest to the problem. Additionally, they should make choices as close to implementation as possible, to use more timely information in the decision. If team members are assigned tasks by others or too early in the process, the benefits of localized and timely decision making can be lost.[99]
Being assigned work also constrains team members into certain roles (for example, team member A must always do the database work), which limits opportunities for cross-training.[99] Team members themselves can choose to take on tasks that stretch their abilities and provide cross-training opportunities.
Scrum master as a contributor
Another common pitfall is for a scrum master to act as a contributor. While not prohibited by the Scrum methodology, the scrum master needs to ensure they have the capacity to act in the role of scrum master first and not working on development tasks. A scrum master's role is to facilitate the process rather than create the product.[100]
Having the scrum master also multitasking may result in too many context switches to be productive. Additionally, as a scrum master is responsible for ensuring roadblocks are removed so that the team can make forward progress, the benefit gained by individual tasks moving forward may not outweigh roadblocks that are deferred due to lack of capacity.[100]
Lack of test automation
Due to the iterative nature of agile development, multiple rounds of testing are often needed. Automated testing helps reduce the impact of repeated unit, integration, and regression tests and frees developers and testers to focus on higher value work.[101]
Test automation also supports continued refactoring required by iterative software development. Allowing a developer to quickly run tests to confirm refactoring has not modified the functionality of the application may reduce the workload and increase confidence that cleanup efforts have not introduced new defects.
Allowing technical debt to build up
Focusing on delivering new functionality may result in increased technical debt. The team must allow themselves time for defect remediation and refactoring. Technical debt hinders planning abilities by increasing the amount of unscheduled work as production defects distract the team from further progress.[102]
As the system evolves it is important to refactor as entropy of the system naturally increases.[103] Over time the lack of constant maintenance causes increasing defects and development costs.[102]
Attempting to take on too much in an iteration
A common misconception is that agile software development allows continuous change, however an iteration backlog is an agreement of what work can be completed during an iteration.[104] Having too much work-in-progress (WIP) results in inefficiencies such as context-switching and queueing.[105] The team must avoid feeling pressured into taking on additional work.[106]
Fixed time, resources, scope, and quality
Agile software development fixes time (iteration duration), quality, and ideally resources in advance (though maintaining fixed resources may be difficult if developers are often pulled away from tasks to handle production incidents), while the scope remains variable. The customer or product owner often push for a fixed scope for an iteration. However, teams should be reluctant to commit to the locked time, resources and scope (commonly known as the project management triangle). Efforts to add scope to the fixed time and resources of agile software development may result in decreased quality.[107]
Developer burnout
Due to the focused pace and continuous nature of agile practices, there is a heightened risk of burnout among members of the delivery team.[108]
Some Agile Terms
Acceptance Test: Confirms that a story is complete by matching a user action scenario with the desired outcome. Acceptance testing is also called beta testing, application testing, and end user testing.
Customer: A customer is a person with an understanding of both the business needs and operational constraints for a project who provides guidance during development.
Domain Model: the application domain responsible for creating a shared language between business and IT.
Iteration: An iteration is a single development cycle, usually measured as one week or two weeks.
Planning Board: Used to track the progress of an agile development project. After iteration planning, stories are written on cards and pinned up in priority order on a planning board.
Planning Game: A planning game is a meeting attended by both IT and business teams that are focused on choosing stories for a release or iteration.
Release: A deployable software package that is a culmination of several iterations of development.
Release Plan: An evolving flowchart that describes which features will be delivered in upcoming releases.
Spike: A story that cannot be estimated until a development team runs a time-boxed investigation.
Stand-up: A daily progress meeting (literally every stands up and meets to keep engaged and motivated), traditionally held within a development area.
Story: A particular business need to be assigned to the software development team. Stories must be broken down into small enough components that they may be delivered in a single development iteration.
Timebox: A defined period of time during which a task must be accomplished.
Velocity: The budget of story units available for planning the next iteration of a development project. Velocity is based on measurements taken during previous iteration cycles.
Wiki: A wiki is a server program that allows users to collaborate in forming the content of a Web site.
SAFE - Scaled Agile Framework
https://drive.google.com/open?id=17IddOUchr7VMAQPkic9VzuMd1BHNS-gC
good ebook
SAFE Diagram

SOC2 principles for operation
https://www.compassitc.com/blog/ssae-16-soc-2-report-the-5-trust-principles
- Security - The system is protected against unauthorized access, both physical and logical
- Availability - The system is available for operation and use as committed or agreed
- Processing Integrity - System processing is complete, accurate, timely, and authorized
- Confidentiality - Information designated as confidential is protected as committed or agreed
- Privacy - Personal information is collected, used, retained, disclosed, and destroyed in conformity
Joel 12 Points on Good Software Teams
https://www.joelonsoftware.com/2000/08/09/the-joel-test-12-steps-to-better-code/
https://drive.google.com/open?id=1FXzSKjiY3kcBL6GEF0uzGsqQgGxhXjpi
12 questions for a good software team
- do you use source control?
- can you make a build in 1 step?
- do you make daily builds?
- do you have a bug database?
- do you fix bugs before new code?
- do you have an up to date schedule?
- do you have a spec?
- do programmers have quiet work conditions?
- do you use the best tools money can buy?
- do you have testers?
- do new candidates write code in their interview?
- do you do hallway usability testing?
writing specs before coding
- for major user process, create journeys with events
- for major backend systems, create system flows with events
- create epics as needed
- create stories for epics before a sprint ( as a user, given x when y then z so outcomes )
- create executable test cases for ux ( using jmeter, geb )
- create executable test cases for services using groovy, postman
Painless Software Schedules
https://www.joelonsoftware.com/2000/03/29/painless-software-schedules/
for a sprint plan, balance resources, features given the time ( 2 weeks )
evidence based scheduling
https://www.joelonsoftware.com/2007/10/26/evidence-based-scheduling/
Why won’t developers make schedules? Two reasons. One: it’s a pain in the butt. Two: nobody believes the schedule is realistic. Why go to all the trouble of working on a schedule if it’s not going to be right?
same as Jim Mason's historical schedule adjustment method
Evidence-Based Scheduling, or EBS. You gather evidence, mostly from historical timesheet data, that you feed back into your schedules. What you get is not just one ship date: you get a confidence distribution curve, showing the probability that you will ship on any given date.
work breakdown for tasks
- You have to break your schedule into very small tasks that can be measured in hours. Nothing longer than 16 hours.
- Keep track of how long you spend working on each task.
- The common estimator has a lot of velocities that are pretty close to each other, for example, {0.6, 0.5, 0.6, 0.6, 0.5, 0.6, 0.7, 0.6}. When you divide by these velocities you increase the amount of time something takes, so in one iteration, an 8-hour task might 13 hours; in another it might take 15 hours
- updates moscow priorities - actively manage projects to ship on time. For example, if you sort features out into different priorities, it’s easy to see how much it would help the schedule if you could cut the lower priority features.
- planning poker in sprint plan sessions
Step-by-step guide for Example
sample code block