m Data Service Products
- jim mason
- jimm1
Key Points
- Account Aggregation is a foundation financial data service
- future products can provide more data, function and analytic components of wealth and money management
- Data pipelines connect, transform data sources to data targets in batches or event streams
- Multiple roles to add value in data services: provider, aggregator, agent, cataloger, manager, notifier, security, compliance, transformer, processor, usage, logger, analytics, indexer, archiver, finder, viewer, presenter, access controller, resource manager, identity manager, smart cache
- what are the open-source components we can leverage?
- common architecture for definitions, development, services, deployment, management, support across all platforms is key
- conceptual model: client app > ds broker > ds agent > ds service > resources > ds adapters > client app
- common architecture standards is key, ideally using established orgs ( SOC 2, MOBI, ISO, identity foundation, IEEE, IETF )
- focus on domains to add value, market segmentation: banking, wealth management, insurance, credit, loans,
- provide leading suite adapters ( eg Salesforce, SAP, HIE etc )
- identity current solution providers for financial data services by domain: equitites, bonds, accounts, purchases, orders
- a data service is a service to other solutions - not a top level solution to users or organizations
- account aggregator ds value-adds for VSM, VCN
- aggregation, audit, analytics, events, notifications, data trackers, identity, registrations, rbac, dqm, usage x user - data, sql extensions, consent mgt, session workspaces, frames
- find best aggregators and work on SWOT reputations, credentials in standards orgs
- study full Homenet life cycle from market dev through support, retention - api and sftp interfaces
- what are the data products by segment? how are they priced? reward programs for usage over forecast,
- aggregation audit >> what do we have now?
- tech study>> data bricks, spark, container spring boot msvc, rbac fwks
- marketing study>> service business case - who needs? value? other providers SWOT ranked? opporunity sized? success path? success kpi?
- tech costs>> give mid-range providers
- more
References
| Reference_description_with_linked_URLs_______________________ | Notes______________________________________________________________ |
|---|---|
| m Data Services Concepts | |
| m Data Architecture | |
| data-platforms-v1 gsheet link | |
| https://www.w3resource.com/mongodb/nosql.php | SQL compared to NoSQL article |
| Kubernetes | |
| Kube Flow | |
| https://github.com/aidtechnology/lf-k8s-hlf-webinar | Kafka on Kubernetes Tutorial |
https://pages.databricks.com/WB-azuretraining-01.html | Databricks video tutorials on Azure - engineering, analytics, data science |
| Articles | |
| https://www.imperva.com/learn/data-security/soc-2-compliance/ | SOC 2 Data Quality Standards for Data Services |
| https://drive.google.com/open?id=1W1vHQ4oxOJUB_OSX1B5c9L06HRNjXXK- | Dummies Guide to Cloud Enterprise Data Platforms |
https://drive.google.com/open?id=1zipd_DJ_GxoCRgUlEtMrzErT2jntkSDv | IBM Cloud Pak |
Key Concepts
Data Quality - SOC 2 Data Quality Standards for Data Services
https://www.imperva.com/learn/data-security/soc-2-compliance/
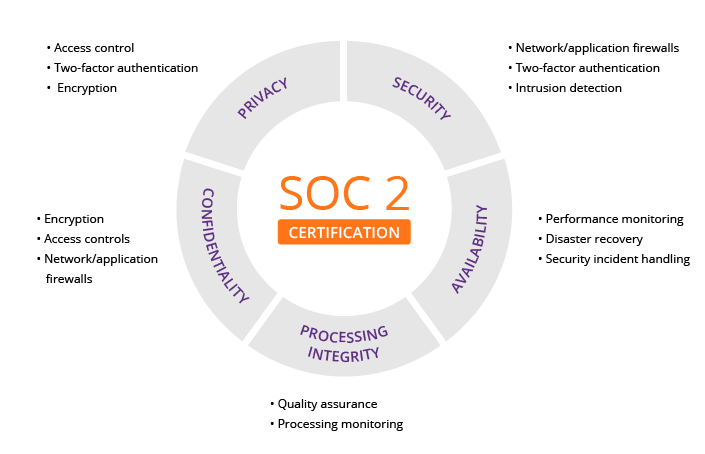
SOC 2 is an auditing procedure that ensures your service providers securely manage your data to protect the interests of your organization and the privacy of its clients. For security-conscious businesses, SOC 2 compliance is a minimal requirement when considering a SaaS provider.
Developed by the American Institute of CPAs (AICPA), SOC 2 defines criteria for managing customer data based on five “trust service principles”—security, availability, processing integrity, confidentiality and privacy.
DQM dimensions and kpi
- Completeness.
- Uniqueness.
- Timeliness.
- Validity.
- Accuracy.
- Consistency.
- Auditabilty
- Utility ( consumption )
- Recoverability
- Authenticity
- Authorization
- Cost
- Risk
- Resources consumed ( efficiency )
- Revenue impacts ( likely indirect )
- Data. Quality. Dimensions.
SQL compared to NoSQL
https://www.w3resource.com/mongodb/nosql.php
https://drive.google.com/open?id=1UAwrKXa9PN3SG4V6IrVfLzdb3L_lgwnw
Transcript
What is NoSQL?
NoSQL is a non-relational database management systems, different from traditional relational database management systems in some significant ways. It is designed for distributed data stores where very large scale of data storing needs (for example Google or Facebook which collects terabits of data every day for their users). These type of data storing may not require fixed schema, avoid join operations and typically scale horizontally.
NoSQL
- Represente Not Only SQL
- Aucun langage de requete declarative
- Aucun schema predefini
- Key-Value stockage de paire, colonne Store, espace de stockage de documents, bases de donnees de graphes
- consistance eventuel plutot la propriete ACID
- Les donnees non structurees et imprevisible
- Priorise haute performance, haute disponibilite et i'evolutivite
NoSQL Really Means...
mettre laccent sur la non relationnelle,
La prochaine generation
Espace de stockage de donnees
operationnelles
et
bases de donnees....
Why NoSQL?
aujourd'hui les donnees deviennent de plus facile d'acceder et de capturer par des tiers tels que Facebook, Google+ et d'autres. Informations personnelles de i'utilisateur, des graphiques sociaux, donnees de localisation geo, le contenu genere par i'utilisateur et de i'exploitation des donnees de la machine ne sont que quelques exemples ou les donnees ont ete en augmentation exponentielle. Pour profiter du service ci-dessus correctement, il est necessaire de traiter une enorme quantite de donnees. L'evolution des bases de donnees NoSQL permet est de gerer ces enormes donnees correctement.
Where to use NoSQL
- Les donnees sociales
- Traitement de I'information
- Enregistrement
- analyse geospatiale
- La modelisation moleculaire
- etc......
When to use NoSQL
- Une grande quantite de donnees
- Beaucoup de lectures / ecritures
- Economique
- schema flexible
- Aucune transaction necessaires
- ACID est pas important
- Aucune jointure
Relational vs NoSQL Database Systems
Relations Basic Relations Data Manipulation Language(DML) No predefined schema Indexes Indexes Structured query language(SQL) Limited query capabilities Transactions Generally No Structured and organized data Unstructured and unpredictable data Only Values Values & references Strongely typed Loosely typed Joins No Joins
CAP Theorem
Vous devez comprendre le theoreme CAP lorsque vous parlez de bases de donnees NoSQL ou en fait lors de la conception de tout systeme distribue. CAP theoreme affirme qu'il ya trois exigeneces fondamentales qui existent dans une relation particuliere lors de la conception d'applications pour une architecture distribuee.
- Consistency - Cela signifie que les donnees contenues dans la base de donnees reste constant apres I'execution d'une operation. Par exemple, apres une operation de mise a jour de tous les clients de voir les memes donnees,
- Availability - Cela signifie que le systeme est toujours (disponibilite garantie de service), sans temps d'arret.
- Partition Tolerance - Cela signifie que le systeme continue de fonctionner meme si la communication entre les serveurs ne sont pas fiables, I.S. les serveurs peuvent etre divises en plusieurs groupes qui ne peuvent pas communiquer entre eux.
Graphical Presentation
Image
NoSQL Categories
It existe quatre types generaux(categories les plus courantes) des bases de donnees NoSQL. Chacune de ces categories a ses propres attributs et limitations specifiques. Il n'y a pas une seule solution qui est mieux que tous les autres, mais il y a des bases de donnees qui sont mieux pour resoudre des problemes specifiques. Afin de clarifier les bases de donnees NoSQL, on se permet de discuter les categories les plus courantes:
* Key-Value store
* Column store
* Document store
* Graph Databases
Key-Value store
* Key-Value stores sont les types les plus elementaires des bases de donnees NoSQL.
* Concu pour traiter d'enormes quantites de donnees.
* Base sur le papier Dynamo d'Amazon.
* Key value stores permettent au developpeur de stocker des donnees de schema-moins.
* Dans le stockage de cle-valeur, stocke les donnees de base de donnees comme table de hachage ou chaque cle est unique et la valeur peut etre une chaine, JSON, BLOB (grand objet de base), etc.
* Une cle peut etre des chaines, hash, listes, ensembles, tries ensembles et les valeurs sont stockees contre ces touches.
* Key value stores peuvent etre utilises comme des collections, des dictionnaires, des tableaux associatifs, etc.
* Key value stores suit la <<disponibilite>> et<<aspects de la partition>> du CAP theoreme.
* Key value stores serait bien travailler pour le shopping contenu de panier, ou des valeurs individuelles comme des couleurs, une page d'atterrissage URI, ou un numero de compte par defaut.
Key- Value stire
Image
Key-Value store Databases
Examples:
* Redis
* Dynamo
* Riak
Column-oriented
* bases de donnees en colonnes travaillent principalement sur des colonnes et chaque colonne est traitee individuellement
* Les valeurs d'une seule colonne sont stockes de maniere contigue.
* stocke les donnees de colonne dans des fichiers specifiques colonnes.
* Dans les column stores, les processeurs de requetes fonctionnent sur des colonnes aussi
* Toutes les donnees dans chaque fichier de donnees de colonne ont le meme type qui le rend ideal pour la compression
* Les column stores peuvent ameliorer les performances des requetes qu'il peut acceder a des donnees specifiques de la colonne.
* Haute performance sur les requetes d'agregation (par exemple COUNT, SUM, AVG, MIN, MAX)
* Travaux sur les entrepots de donnees et de business intelligence, gestion de la relation client (CRM), la bibliotheque de catalogues de cartes, etc.
Key-Value Store
Image
Column-oriented
Image
Column-oriented Databases
Examples:
* BigTable
* Cassandra
* SimpleDB
Document oriented databases
* Une collection de documents
* Les donnees de ce modele sont stockees a I'interieur de documents.
* Un documents est un ensemble de valeurs cles ou la cle permet d'acceder a sa valeur.
* Les documents ne sont generalement pas force d'avoir un schema et sont donc flexibles et faciles a changer.
* Les documents sont stockes dans des collections afin de regrouper differents types de donnees..
* Les documents peuvent contenir plusieurs differentes paires cle-valeur, ou des paires cle-tableau, ou meme des documents imbriques.
Document oriented databases
Image
Document oriented databases
Examples:
* MongoDB
* CouchDB
Graph databases
* Une base de donnees graphique stocke les donnees dans un graphique.
* Il est capable de representer elegamment toute sorte de donnees d'une maniere tres accessible.
* Une base de donnees graphique est un ensemble de noeuds et d'aretes
* Chaque noeud represente une entite (comme un etudiant) et chaque bord represente une connexion ou d'une relation entre deux noeuds.
* Chaque noeud et le bord est defini par un identifiant unique.
* Chaque noeud connait ses noeuds adjacents.
* Comme le nombre de noeuds augmente, le cout d'une etape locale (ou hop) reste le meme.
* Index pour les recherches.
Graph databases
Image
Graph databases
Examples:
* OrientDB
* Neo4J
* Titan
NoSQL pros/cons
Advantages:
- Haute evolutivite
- Distributed Computing
- Moindre cout
- flexibilite du schema, donnees semi-structurees
- Pas de relations compliquees
Disadvantages:
- Pas de normalisation
- capacites de requete Limited (jusqu'a present)
- la coherence eventuel est pas intuitif pour programmer
- Pas assez mature pour les entreprises
Production deployment
There is a large number of companies using NoSQL. To name a few:
- Mozilla
- Adobe
- Foursquare
Thank you for your Time and Attention!
Redis DB Cache Management
https://www.w3resource.com/slides/redis-nosql-database-an-introduction.php
https://drive.google.com/open?id=1E3-abaRe0dSBiGCrJJqJ9hx-1P5HDDgL
Redis (Remote DIctionary Server) is an open source, networked, single threaded, in- memory, advanced key-value store with optional durability. It is often referred to as a data structure server since keys can contain strings, hashes, lists, sets and sorted sets.
★ Developer(s) : Salvatore Sanfilippo, Pieter Noordhuis ★ Initial release : April 10, 2009 ★ Stable release : 2.8.12 / June 23, 2014 ★ Development status : Active ★ Written in : ANSI C ★ Operating system : Cross-platform ★ Type : Key–value stores ★ License : BSD
Redis : What for?
★ Cache out-of-process ★ Duplicate detector ★ LIFO/FIFO Queues ★ Priority Queue ★ Distributed HashMap ★ UID Generator ★ Pub/Sub ★ Real-time analytics & chat apps ★ Counting Stuff ★ Metrics DB ★ Implement expires on items ★ Leaderboards (game high scores) ★ Geolocation lookup ★ API throttling (rate-limits) ★ Autocomplete ★ Social activity feed
Who's using Redis?
★ Twitter ★ Github ★ Weibo ★ Pinterest ★ Snapchat ★ Craigslist ★ Digg ★ StackOverflow ★ Flickr ★ 220.000.000.000 commands per day ★ 500.000.000.000 reads per day ★ 50.000.000.000 writes per day ★ 500+ servers 2000+ Redis instances!
key Features
★ Atomic operations ★ Lua Scripting ★ Pub/Sub ★ Transactions ★ Master/Slave replication ★ Cluster (with automatic sharding)* ★ Automatic failover (Redis Sentinel) ★ Append Only File (AOF) persistence ★ Snapshot (RDB file) persistence ★ Redis can handle up to 232 keys, and was tested in practice to handle at least 250 million of keys per instance. ★ Every list, set, and sorted set, can hold 232 elements.
key Advantages & Disadvantages
► Advantages
★ Blazing Fast ★ Robust ★ Easy to setup, Use and maintain ★ Extensible with LUA scripting
► Disadvantages
★ Persistence consumes lot of I/O when using RDB ★ All your data must fit in memory
Redis in-memory
► Redis is an in-memory but persistent on disk database, so it represents a different trade off where very high write and read speed is achieved with the limitation of data sets that can't be larger than memory.
Why GraphQL
Glide - open-source GraphQL front-end for Salesforce API set
https://postlight.com/trackchanges/introducing-glide-graphql-for-salesforce
Glide is a free toolkit for engineers who are building Salesforce integrations into their apps. Glide allows you to seamlessly execute GraphQL requests against any Salesforce instance with minimal setup. The code is free and open source. Get Glide on GitHub.
Developers love working with GraphQL, because it brings a strongly-typed schema to your application’s data, and gives clients control over requesting exactly what they need, no more and no less. This reduces network traffic (and latency) compared to REST, where your app has to make multiple calls to various endpoints to retrieve the data it needs (plus some it doesn’t). When GraphQL is paired with React, it’s an incredible development toolchain.
Glide is the quickest way to prototype and build GraphQL applications backed by Salesforce data. Glide automatically introspects your Salesforce data models, and creates an intuitive and idiomatic GraphQL schema out of the box. Glide also handles Salesforce authentication for you, so you can hit the ground running and start prototyping right away.
Glide can spin up a GraphQL server pointing at your Salesforce instance, or you can import Glide into your existing server code and deploy it. With Glide, you can start making GraphQL queries and mutations on your Salesforce data in two commands. Step-by-step instructions to get started are available in the docs.
Potential Value Opportunities
VCN opportunities by market segment
account aggregator ds value-adds for VSM, VCN
aggregation, audit, analytics, events, notifications, data trackers, identity, registrations, rbac, dqm, usage x user - data, sql extensions, consent mgt
SWT Data Platform Comparisons workbook
SWT Open Data Services Platform
Integrated architecture and services for:
job managment
data ingestion in batch
data ingestion via api
| data_service_type_______________ | data_solution_options______________________ | Notes_________________________________ |
|---|---|---|
| distributed services orchestration | Kubernetes | provides overlay network on other platforms, networks need smart caches, federation, replicas, locality |
| distributed messaging | Kafka | |
| distributed services | gRPC | |
| REST API | ||
Potential Challenges
Existing Account Aggregators
Mint
Betterment
Candidate Solutions
Open-source NoSQL Databases
https://www.geeksforgeeks.org/top-10-open-source-nosql-databases-in-2020/
m Apache Data Services#Cassandra - open-source high-performance database that is provably fault-tolerant both on commodity hardware or cloud infrastructure
Apache Cassandra is a free and open-source high-performance database that is provably fault-tolerant both on commodity hardware or cloud infrastructure. It can even handle failed node replacements without shutting down the systems and it can also replicate data automatically across multiple nodes. Moreover, Cassandra is a NoSQL database in which all the nods are peers without any master-slave architecture. This makes it extremely scalable and fault-tolerant and you can add new machines without any interruptions to already running applications. You can also choose between synchronous and asynchronous replication for each update.
m Data CouchDb - Couch DB can also scale up for more demanding projects into a cluster of nodes with multiple servers.
Apache CouchDB is an open-source project and a single node database that allows you to easily store your data and access it when you need it. Couch DB can also scale up for more demanding projects into a cluster of nodes with multiple servers. It supports the HTTP protocol along with the JSON data format and also integrates with HTTP proxy servers. Apache CouchDB is designed for reliability with a crash-resistant structure that supports “Offline First” applications and a system that saves data redundantly so that it is never lost and available in a state of emergency.
Apache HBase - distributed Hadoop database
Apache HBase is an open-source distributed Hadoop database that can be used to read and write to big data. HBase has been constructed so that it can manage billions of rows and millions of columns using commodity hardware clusters. This database is based on the Big Table which was a distributed storage system created for structured data. Apache HBase has many different capabilities including scalability, automatic sharding of tables, consistent reading and writing capabilities, support against failure for all the servers, etc.
MongoDB - a general-purpose distributed database with ACID support
MongoDB is a general-purpose distributed database created for the application developers in this generation to use in the cloud. This is a document database that stores the data in JSON-like documents which is much more powerful and efficient than the traditional row and column databases. MongoDB also supports various methods of searching such as geographical searching, text searching, graph searching, etc. Another advantage of MongoDB is that it provides first-class security for its clients including SSL, firewalls, encryption, etc. And the best thing is you can also create visualizations using MongoDB data and connect with any Business Intelligence tools that are compatible with the MySQL protocol.
Neo4j - a graph-based database
Neo4j is a graph-based database that is excellent in handling not only data but also data relationships. Since Neo4j connects the data when it is stored in the database, it can access the data again much faster than conventional databases. Each data record has direct pointers to all the other data records it is connected with and this underlines the power of the database. Neo4j also uses Cypher queries that are much faster and simpler to write than SQL queries and since it doesn’t have any tables there is no need to bother about joins. Neo4j also provides drivers for Java, .Net, JavaScript, Python and Go in an official capacity whereas the open-source community contributors provide many other drivers like Ruby, PHP, R, C, C++, etc.
Risk - distributed NoSQL database that is highly resilient
Riak is a distributed NoSQL database that is highly resilient and ensures data accuracy. It is created using multiple clusters that make sure data is not lost even in the event of a hardware failure and read/write operations can continue smoothly. Riak is designed using a key/value specification that solves many challenges in the management of big data such as tracking user data, copying the data in various locations all over the world, storing connected data, etc. Some of the features of Riak include scalability, operational simplicity, resiliency, complex query support, etc. It can also integrate with Apache Spark to provide real-time analysis of Spark.
Redis - in memory database that supports many different data structures such as strings, lists, hashes, sets, sorted sets
Redis is an open-source database that supports many different data structures such as strings, lists, hashes, sets, sorted sets, etc. It is written in ANSI C and it can be used with almost all the programming languages and Linux and OS X operating systems. Redis works with an in-memory dataset to preserve its extremely fast performance and the implementation uses the fork system call to create a duplicate of the current process with the data so that the parent process can continue its operations with the existing clients and the child process can create a data copy on the disk.
In memory databases
Well-known as a "data structure server", with support for strings, hashes, lists, sets, sorted sets, streams, and more.
Server-side scripting with Lua and server-side stored procedures with Redis Functions.
Horizontal scalability with hash-based sharding, scaling to millions of nodes with automatic re-partitioning when growing the cluster.
Replication with automatic failover for both standalone and clustered deployments.
Keeps the dataset in memory for fast access, but can also persist all writes to permanent storage to survive reboots and system failures.
Redis use cases
Redis' versatile in-memory data structures enable building data infrastructure for real-time applications that require low latency and high-throughput.
Redis' speed makes it ideal for caching database queries, complex computations, API calls, and session state.
The stream data type enables high-rate data ingestion, messaging, event sourcing, and notifications.
Redis Stack
Redis Stack Server lets you build applications with searchable JSON, time series and graph data models, and extended probabilistic data structures.
Get productive quickly with the Redis Stack object mapping and client libraries.
Hypertable - keeps the data sorting using a primary key, unlike most other NoSQL databases that use the hash table design
Hypertable is NoSQL open-source database that was designed to combat the scalability problem that appears in all relational databases. It was based on the Google Big Table design and written in C++. Hypertable runs in both Linux and Mac OS X. It is also suitable for a wide range of applications as it keeps the data sorting using a primary key, unlike most other NoSQL databases that use the hash table design. Hypertable is also suited to provide maximum efficiency with minimum performance and stability costs which makes it extremely cost-efficient.
RavenDB - benefits of a NoSQL database with all the conveniences of a relational database and high performance at low cost
RavenDB is a NoSQL document database that provides the benefits of a NoSQL database with all the conveniences of a relational database. It also offers fully transactional (ACID) data integrity so you can use it along with your existing SQL databases to get the most out of both types. This database is also highly scalable and it can create new nodes to keep up with increasing data traffic. RavenDB is available for installation on-premises as well as in the form of a cloud service provided by Amazon Web Services, Azure, etc.
https://ravendb.net/why-ravendb/acid-transactions
ACID transactions
RavenDB is one of the first nonrelational databases to offer ACIDity not just for a single value, but for multiple values throughout your database as well. And as a distributed database, it also offers ACID guarantees throughout your database cluster. Your developers are exempt from handling the numerous scenarios of partial data transfers and the intricacies of data storage, and are free to focus on building robust applications and deliver value to the business.
Low cost performance
In some cases, data is streamed from small edge points like sensors embedded in machinery, clothing and even the human body, and then relayed to servers for immediate processing. On a Raspberry PI, a $25 machine running on low powered ARM chips and a mere 1 GB of RAM, RavenDB can handle over 13,000 reads per second and over a 1,000 writes per second. This is more than enough for most small to medium applications. For demands higher than that, a single RavenDB server running on a machine of less than $1,000 can handle over 150,000 writes per second and over a million reads per second.
Google Data Products - Data to AI
Image Source: Data to AI, Google Cloud
diagram below misses several key dimensions >>. trusts, governance, value ( VCRS )

Step-by-step guide for Example
sample code block