m Data Services Concepts
- jim mason
- jimm1
Key Points
- Data pipelines connect, transform data sources to data targets in batches or event streams
- Semantic data services - data that can interpret, map other data sources semantically to a data context
References
Key Concepts
Supply Chain Data Examples Categorized by Structure, Volume Dimensions
Linkedin - Raj Grover - Transform Partners - Supply Chain Data Governance tip

Data Management Standards
- Data Modeling Standards
- Enterprise Metadata Standards
- Data Architecture Standards
- Data Quality Standards
- Master Data Management Standards
- Data Governance Standards & Polcies
- Data Services Standards
- Data Transformation Standards
- Data Security Standards & Policies
- Data Transaction Standards
- Distributed Data Standards
- Data Control Standards
- Data Event Services Standards
Data Table Types
- Master Code Tables
- Meta model definition Tables
- Service Control Tables
- Process Control Tables
- Interface Control Tables
- Product Control Tables
- Environment Control Tables
- Event Control Tables
- Data Management Control Tables
- Configuration Tables
- Master Tables
- Transaction Tables
- Transaction Ledgers
- Transaction Logs
- Event Transaction Tables
- Work Tables ( global, process, user )
- Work Management Tables
Data Attribute Types
Character
Number
Decimal
Date
Boolean
Binary
OLTP
Observability tools - common features for OLTP
oltp-observability-astronomer.io-Watch Demos On-Demand - Astronomer.pdf link
oltp-observability-astronomer.io-Watch Demos On-Demand - Astronomer.pdf file
OLAP
real-time on-demand access
smart caching and data age
data streaming
event streaming and reactive services
Enterprise Data Landscape Components
Raj Grover
Components of #Data Landscape:
The term "data landscape" refers to the comprehensive view of all data assets and their interactions within an organization. It encompasses the various data sources, data repositories, data flows, data processing, and data usages across the enterprise.
The data landscape provides a holistic perspective on how data is collected, stored, processed, and utilized to support business operations, decision-making, and strategic objectives.
Key components and aspects of a data landscape typically include:
-Data Sources: These are the origins of data, such as databases, applications, sensors, external partners, or any system that generates or captures data.
-Data Types: Different categories of data, including structured data (e.g., databases, spreadsheets) and unstructured data (e.g., text documents, images, videos).
-Data Repositories: The places where data is stored, including on premises databases, data warehouses, data lakes, cloud storage, and file systems.
-Data Flows: The pathways through which data moves within the organization. This includes data ingestion, transformation, movement between systems, and data export.
-Data Processing: The actions and transformations applied to data as it moves through the data landscape. This can involve data cleansing, aggregation, analytics, and reporting.
- #DataIntegration: The process of combining data from different sources to provide a unified view. Integration helps eliminate data silos and ensures data consistency.
-Data Usage: How data is utilized within the organization, including reporting, business intelligence, analytics, and other applications. This also covers data access and usage permissions.
- #DataGovernance: The policies, procedures, and controls governing data quality, security, privacy, and compliance throughout the data landscape.
- #Metadata: Information about the data, such as data definitions, data lineage, data ownership, and data quality indicators. Metadata is critical for understanding and managing the data landscape.
- #DataArchitecture: The structural design and organization of data assets, including data models, schemas, and data structures.
- #DataManagement Tools: The software and platforms used to manage and maintain the data landscape, such as data integration tools, data modeling tools, data cataloging tools, and data governance platforms.
- #DataSecurity and Access Control: Measures in place to protect sensitive data, including authentication, authorization, encryption, and data masking.
-Data Ownership and Stewardship: Roles and responsibilities for managing and maintaining data assets, including data owners and data stewards.
- #DataQuality and Data Profiling: Processes for assessing and improving the quality of data, as well as understanding the characteristics of data elements
Datacamp Data and Machine Learning Tools Landscape Resource Map
Identifies many data technologies, tools and resources that can be used to build, operate and support an Enterprise Data Landscape
Image Source: Datacamp
https://www.datacamp.com/blog/infographic-data-and-machine-learning-tools-landscape
Data Lake versus Data Warehouse
When to use a data lake
Typical uses for a data lake include data exploration, data analytics, and #machinelearning.
A data lake can also act as the data source for a #datawarehouse. With this approach, the raw data is ingested into the data lake and then transformed into a structured queryable format. Typically this transformation uses an ELT (extract-load-transform) pipeline, where the data is ingested and transformed in place. Source data that is already relational may go directly into the data warehouse, using an ETL process, skipping the data lake.
Data lake stores are often used in event streaming or IoT scenarios, because they can persist large amounts of relational and nonrelational data without transformation or schema definition. They are built to handle high volumes of small writes at low latency, and are optimized for massive throughput.

m Apache Data Services
Data Exchange Stds - ISO20022
ISO_20022-fin-data-exchange-stds_ppt_long_version_v176.pdf
Data Exchange Formats - ISO ASN.1 std
ASN.1 Reference card
Serializable data formats with different encoding stds
concept of a schema and data
supports XML, JSON, BER, PER formats
ISO ASN.1 std reference card - gdrive
Contact ::= SEQUENCE {
name VisibleString,
phone NumericString
}So, the above contact named John Smith with a phone number of 987 6543210 might be serialized in binary or text format (ASN.1 Encoding Rules). For example:
Basic Encoding Rules (BER)
30 19 80 0A 4A6F686E20536D697468 81 0B 3938372036353433323130
Packed Encoding Rules (PER)
0A 4A 6F 68 6E 20 53 6D 69 74 68 0B A9 80 76 54 32 10
XML Encoding Rules (XER)
<?xml version="1.0" encoding="UTF-8"?> <Contact>
<name>John Smith</name> <phone>987 6543210</phone> </Contact>
JSON Encoding Rules (JER)
{ "name" : "John Smith", "phone" : "987 6543210" }
Data Quality - SOC 2 Data Quality Standards for Data Services
https://www.imperva.com/learn/data-security/soc-2-compliance/
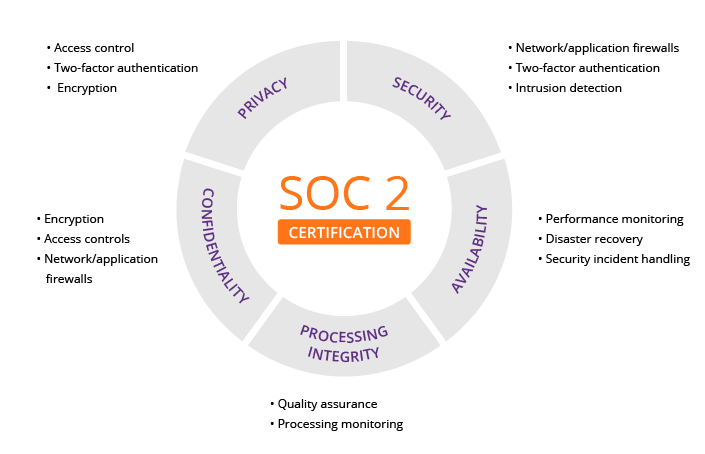
SOC 2 is an auditing procedure that ensures your service providers securely manage your data to protect the interests of your organization and the privacy of its clients. For security-conscious businesses, SOC 2 compliance is a minimal requirement when considering a SaaS provider.
Developed by the American Institute of CPAs (AICPA), SOC 2 defines criteria for managing customer data based on five “trust service principles”—security, availability, processing integrity, confidentiality and privacy.
SQL Basics
https://datamovesme.com/2019/12/30/free-sql-for-data-science-course/
DDL
DML
see Jim Mason SQL Sessions
m IBM i and Z Solutions & Services#JimMason-BestSQLsession
NoSQL compared to SQL
https://www.w3resource.com/mongodb/nosql.php
https://drive.google.com/open?id=1UAwrKXa9PN3SG4V6IrVfLzdb3L_lgwnw
Transcript
What is NoSQL?
NoSQL is a non-relational database management systems, different from traditional relational database management systems in some significant ways. It is designed for distributed data stores where very large scale of data storing needs (for example Google or Facebook which collects terabits of data every day for their users). These type of data storing may not require fixed schema, avoid join operations and typically scale horizontally.
NoSQL
- Represente Not Only SQL
- Aucun langage de requete declarative
- Aucun schema predefini
- Key-Value stockage de paire, colonne Store, espace de stockage de documents, bases de donnees de graphes
- consistance eventuel plutot la propriete ACID
- Les donnees non structurees et imprevisible
- Priorise haute performance, haute disponibilite et i'evolutivite
NoSQL Really Means...
mettre laccent sur la non relationnelle,
La prochaine generation
Espace de stockage de donnees
operationnelles
et
bases de donnees....
Why NoSQL?
aujourd'hui les donnees deviennent de plus facile d'acceder et de capturer par des tiers tels que Facebook, Google+ et d'autres. Informations personnelles de i'utilisateur, des graphiques sociaux, donnees de localisation geo, le contenu genere par i'utilisateur et de i'exploitation des donnees de la machine ne sont que quelques exemples ou les donnees ont ete en augmentation exponentielle. Pour profiter du service ci-dessus correctement, il est necessaire de traiter une enorme quantite de donnees. L'evolution des bases de donnees NoSQL permet est de gerer ces enormes donnees correctement.
Where to use NoSQL
- Les donnees sociales
- Traitement de I'information
- Enregistrement
- analyse geospatiale
- La modelisation moleculaire
- etc......
When to use NoSQL
- Une grande quantite de donnees
- Beaucoup de lectures / ecritures
- Economique
- schema flexible
- Aucune transaction necessaires
- ACID est pas important
- Aucune jointure
Relational vs NoSQL Database Systems
Relations Basic Relations Data Manipulation Language(DML) No predefined schema Indexes Indexes Structured query language(SQL) Limited query capabilities Transactions Generally No Structured and organized data Unstructured and unpredictable data Only Values Values & references Strongely typed Loosely typed Joins No Joins
CAP Theorem
Vous devez comprendre le theoreme CAP lorsque vous parlez de bases de donnees NoSQL ou en fait lors de la conception de tout systeme distribue. CAP theoreme affirme qu'il ya trois exigeneces fondamentales qui existent dans une relation particuliere lors de la conception d'applications pour une architecture distribuee.
- Consistency - Cela signifie que les donnees contenues dans la base de donnees reste constant apres I'execution d'une operation. Par exemple, apres une operation de mise a jour de tous les clients de voir les memes donnees,
- Availability - Cela signifie que le systeme est toujours (disponibilite garantie de service), sans temps d'arret.
- Partition Tolerance - Cela signifie que le systeme continue de fonctionner meme si la communication entre les serveurs ne sont pas fiables, I.S. les serveurs peuvent etre divises en plusieurs groupes qui ne peuvent pas communiquer entre eux.
Graphical Presentation
Image
NoSQL Categories
It existe quatre types generaux(categories les plus courantes) des bases de donnees NoSQL. Chacune de ces categories a ses propres attributs et limitations specifiques. Il n'y a pas une seule solution qui est mieux que tous les autres, mais il y a des bases de donnees qui sont mieux pour resoudre des problemes specifiques. Afin de clarifier les bases de donnees NoSQL, on se permet de discuter les categories les plus courantes:
* Key-Value store
* Column store
* Document store
* Graph Databases
Key-Value store
* Key-Value stores sont les types les plus elementaires des bases de donnees NoSQL.
* Concu pour traiter d'enormes quantites de donnees.
* Base sur le papier Dynamo d'Amazon.
* Key value stores permettent au developpeur de stocker des donnees de schema-moins.
* Dans le stockage de cle-valeur, stocke les donnees de base de donnees comme table de hachage ou chaque cle est unique et la valeur peut etre une chaine, JSON, BLOB (grand objet de base), etc.
* Une cle peut etre des chaines, hash, listes, ensembles, tries ensembles et les valeurs sont stockees contre ces touches.
* Key value stores peuvent etre utilises comme des collections, des dictionnaires, des tableaux associatifs, etc.
* Key value stores suit la <<disponibilite>> et<<aspects de la partition>> du CAP theoreme.
* Key value stores serait bien travailler pour le shopping contenu de panier, ou des valeurs individuelles comme des couleurs, une page d'atterrissage URI, ou un numero de compte par defaut.
Key- Value stire
Image
Key-Value store Databases
Examples:
* Redis
* Dynamo
* Riak
Column-oriented
* bases de donnees en colonnes travaillent principalement sur des colonnes et chaque colonne est traitee individuellement
* Les valeurs d'une seule colonne sont stockes de maniere contigue.
* stocke les donnees de colonne dans des fichiers specifiques colonnes.
* Dans les column stores, les processeurs de requetes fonctionnent sur des colonnes aussi
* Toutes les donnees dans chaque fichier de donnees de colonne ont le meme type qui le rend ideal pour la compression
* Les column stores peuvent ameliorer les performances des requetes qu'il peut acceder a des donnees specifiques de la colonne.
* Haute performance sur les requetes d'agregation (par exemple COUNT, SUM, AVG, MIN, MAX)
* Travaux sur les entrepots de donnees et de business intelligence, gestion de la relation client (CRM), la bibliotheque de catalogues de cartes, etc.
Key-Value Store
Image
Column-oriented
Image
Column-oriented Databases
Examples:
* BigTable
* Cassandra
* SimpleDB
Document oriented databases
* Une collection de documents
* Les donnees de ce modele sont stockees a I'interieur de documents.
* Un documents est un ensemble de valeurs cles ou la cle permet d'acceder a sa valeur.
* Les documents ne sont generalement pas force d'avoir un schema et sont donc flexibles et faciles a changer.
* Les documents sont stockes dans des collections afin de regrouper differents types de donnees..
* Les documents peuvent contenir plusieurs differentes paires cle-valeur, ou des paires cle-tableau, ou meme des documents imbriques.
Document oriented databases
Image
Document oriented databases
Examples:
* MongoDB
* CouchDB
Graph databases
* Une base de donnees graphique stocke les donnees dans un graphique.
* Il est capable de representer elegamment toute sorte de donnees d'une maniere tres accessible.
* Une base de donnees graphique est un ensemble de noeuds et d'aretes
* Chaque noeud represente une entite (comme un etudiant) et chaque bord represente une connexion ou d'une relation entre deux noeuds.
* Chaque noeud et le bord est defini par un identifiant unique.
* Chaque noeud connait ses noeuds adjacents.
* Comme le nombre de noeuds augmente, le cout d'une etape locale (ou hop) reste le meme.
* Index pour les recherches.
Graph databases
Image
Graph databases
Examples:
* OrientDB
* Neo4J
* Titan
NoSQL pros/cons
Advantages:
- Haute evolutivite
- Distributed Computing
- Moindre cout
- flexibilite du schema, donnees semi-structurees
- Pas de relations compliquees
Disadvantages:
- Pas de normalisation
- capacites de requete Limited (jusqu'a present)
- la coherence eventuel est pas intuitif pour programmer
- Pas assez mature pour les entreprises
Production deployment
There is a large number of companies using NoSQL. To name a few:
- Mozilla
- Adobe
- Foursquare
Thank you for your Time and Attention!
Redis DB Cache Management
https://www.w3resource.com/slides/redis-nosql-database-an-introduction.php
https://drive.google.com/open?id=1E3-abaRe0dSBiGCrJJqJ9hx-1P5HDDgL
<<tip>> compare to ehcache, internal server caches ( session and global )
Redis (Remote DIctionary Server) is an open source, networked, single threaded, in- memory, advanced key-value store with optional durability. It is often referred to as a data structure server since keys can contain strings, hashes, lists, sets and sorted sets.
★ Developer(s) : Salvatore Sanfilippo, Pieter Noordhuis ★ Initial release : April 10, 2009 ★ Stable release : 2.8.12 / June 23, 2014 ★ Development status : Active ★ Written in : ANSI C ★ Operating system : Cross-platform ★ Type : Key–value stores ★ License : BSD
Redis : What for?
★ Cache out-of-process ★ Duplicate detector ★ LIFO/FIFO Queues ★ Priority Queue ★ Distributed HashMap ★ UID Generator ★ Pub/Sub ★ Real-time analytics & chat apps ★ Counting Stuff ★ Metrics DB ★ Implement expires on items ★ Leaderboards (game high scores) ★ Geolocation lookup ★ API throttling (rate-limits) ★ Autocomplete ★ Social activity feed
Who's using Redis?
★ Twitter ★ Github ★ Weibo ★ Pinterest ★ Snapchat ★ Craigslist ★ Digg ★ StackOverflow ★ Flickr ★ 220.000.000.000 commands per day ★ 500.000.000.000 reads per day ★ 50.000.000.000 writes per day ★ 500+ servers 2000+ Redis instances!
key Features
★ Atomic operations ★ Lua Scripting ★ Pub/Sub ★ Transactions ★ Master/Slave replication ★ Cluster (with automatic sharding)* ★ Automatic failover (Redis Sentinel) ★ Append Only File (AOF) persistence ★ Snapshot (RDB file) persistence ★ Redis can handle up to 232 keys, and was tested in practice to handle at least 250 million of keys per instance. ★ Every list, set, and sorted set, can hold 232 elements.
key Advantages & Disadvantages
► Advantages
★ Blazing Fast ★ Robust ★ Easy to setup, Use and maintain ★ Extensible with LUA scripting
► Disadvantages
★ Persistence consumes lot of I/O when using RDB ★ All your data must fit in memory
Redis in-memory
► Redis is an in-memory but persistent on disk database, so it represents a different trade off where very high write and read speed is achieved with the limitation of data sets that can't be larger than memory.
Why GraphQL
Fits CQRS - Command Query Responsibility Separation Principle for performance, modularity, control
Glide - open-source GraphQL front-end for Salesforce API set
https://postlight.com/trackchanges/introducing-glide-graphql-for-salesforce
Glide is a free toolkit for engineers who are building Salesforce integrations into their apps. Glide allows you to seamlessly execute GraphQL requests against any Salesforce instance with minimal setup. The code is free and open source. Get Glide on GitHub.
Developers love working with GraphQL, because it brings a strongly-typed schema to your application’s data, and gives clients control over requesting exactly what they need, no more and no less. This reduces network traffic (and latency) compared to REST, where your app has to make multiple calls to various endpoints to retrieve the data it needs (plus some it doesn’t). When GraphQL is paired with React, it’s an incredible development toolchain.
Glide is the quickest way to prototype and build GraphQL applications backed by Salesforce data. Glide automatically introspects your Salesforce data models, and creates an intuitive and idiomatic GraphQL schema out of the box. Glide also handles Salesforce authentication for you, so you can hit the ground running and start prototyping right away.
Glide can spin up a GraphQL server pointing at your Salesforce instance, or you can import Glide into your existing server code and deploy it. With Glide, you can start making GraphQL queries and mutations on your Salesforce data in two commands. Step-by-step instructions to get started are available in the docs.
Semantic Data Services and Data Models
Goals
Break down data silos, data translation mapping work
Foundation for mapping to smart contracts across disparate organizations
Data Services Catalog Service for a Context
Find, add, map new items to the catalog ( source can be a data store, message service, etc )
Client understands a data source semantically ( organization meaning vs simple schema attributes ).
theCustomerOrder, theCustomerOrderNbr vs simple ORDNO, type packed decimal etc
Automated Curation, Data Certification ( eg Pyramis data feeds w suspended batches / transactions ) of source and data
Free Time Stamp Authority Service
https://www.freetsa.org/index_en.php
Trusted time stamping is the process of securely keeping track of the creation and modification times of a document. Security here means that no one - not even the owner of the document - should be able to change it once it has been recorded provided that the time stamper's integrity is never compromised. FreeTSA trusted time stamping Software as a Service (SaaS) provides an easy method to apply RFC 3161 trusted timestamps to time-sensitive transactions through independently verified and auditable date and UTC (Coordinated Universal Time) sources.
Adding a trusted timestamp to code or to an electronic signature provides a digital seal of data integrity and a trusted date and time of when the transaction took place. Recipients of documents and code with a trusted timestamp can verify when the document or code was digitally or electronically signed, as well as verify that the document or code was not altered after the date the timestamp vouches for. (Readme).
For multiple files, the general concept is that time stamping a single file that contains an aggregate list of fingerprints of other files, also proves that these other files must have existed before the aggregate file was created, provided that both the aggregate file and the referenced file are available during verification process. Freetsa also offers the possibility of URLs timestamps (do not abuse). If you are interested in implementing timestamps on your project / company using the FreeTSA service, you can contact me for specific requirements. Freetsa can also be used within the Tor anonymity network.
Making timestamps from Android/iOS devices is possible and no software installation is required (Video). To timestamp a picture you must go to the "Online Signature" section in the browser, click "Choose a file" and select "Use camera". Once the photo or video are completed, you can download the timestamp (TimeStampResponse). Just that. You also may select any other file available in the device if you choose so.
Freetsa.org offers free OCSP and CRL, NTP, DNSCRYPT, DNS (Port 53) and DNS over TLS (DoT) services for time synchronisation and encrypted name resolution respectively. The resolution of DNSCRYPT (Port 553) do not have any type of restriction (SPAM, Malware, Parental,...). No logs are saved. Like the rest of the services offered by FreeTSA, DoT accepts TCP connections to port 853 on all its IPv4/IPv6 addresses.
Guide: How to sign PDF documents files with time stamp
FreeTSA onion domain (Tor): th3ccojidpgbgv5d.onion (https /http).
RFC 3161 TSA: Time-Stamp Protocol (TSP).
RFC 958 NTP: Network Time Protocol (NTP).
Event-Driven Data Services concepts
Difference between REST API and Event Driven API
REST APIs can be asynchronous using
- web hooks - call backs
- web sockets
Event-Driven APIs
generally designed to respond or handle a stream of events from clients
the simplified diagram from Gravitee below highlights the differences
In reality, the request model for event-driven COULD be request / response ( not shown below ) OR pub / sub ( broadcast )
SSE - Server Sent Events - publish an event to a client listener
A number of databases now support SSE.
This is a server to client push technology for messages the client can respond to
Unlike web sockets that provides the same server push capability, SSE does not allow the client to respond directly to the message which may be a securit advantage
This was a very useful model when I needed to capture transaction data from vendor applications that refused to provide an agent to see those transactions
If you control the database directly, those enterprise databases can be configured to publish SSE to clients. If not, you can use the binary logs as I did below to generate SSE from a server app to clients.
Most enterprise databases ( MySQL, Postgres, DB2, Oracle, SQL Server etc ) have binary log files for federated or distributed clusters that can be read by a client app to capture the data transactions and publish those to remote clients listening for a SSE. You can define a responsive workflow that is initiated by a transaction in a proprietary app IF it uses one of these enterprise databases.

any enterprise Data Service ( database, service etc ) should be able to:
- generate events ( typically SSE - Server Sent Events to any registered client that is read-only event data
- register to listen for events from other event sources including event frameworks like Apache EventMesh, Kafka etc
- a data service event handler would be to invoke a process ( eg gRPC, API or run a query ) typically
Using SSE ( server sent events ) generated by a service from SQL DB binary replicas to integrate with closed solutions like Cavu HCM
you may have a software vendor where you license their application software and you own your data but they won't provide a free API to access your data from their servers. Given 90% of those solutions use a standard database on the backend like ( DB2, MySQL, Mongo etc ) and the standard databases can update a replica using a binary log, the DB vendors have tools or apis to access the binary log file transactions. Creating a function to read each selected binary log event, you can create SSE ( Server Sent Events ) to publish any selected events to registered listeners. This may be an effective work around to integrate using event-driven automation even when your software vendor doesn't provide direct api or event access.
More on SSE
m Data Architecture#Data-Architecture-Support-for-Event-Streams-for-Async-Server-Data-Flow-with-SSE
https://en.wikipedia.org/wiki/Server-sent_events
https://shopify.engineering/server-sent-events-data-streaming
Event-Driven Services Concepts Terminology
https://developer.confluent.io/faq/apache-kafka/architecture-and-terminology/
What is event-driven architecture?
An event-driven architecture is an architecture based on producing, consuming, and reacting to events, either within a single application or as part of an intersystem communication model. Events are communicated via event streams, and interested consumers can subscribe to the event streams and process the events for their own business purposes.
Why use an event-driven architecture?
Event-driven architecture enables loose coupling of producers and consumers via event streams, and is often used in conjunction with microservices. The event streams provide a mechanism of asynchronous communication across the organization, so that each participating service can be independently created, scaled, and maintained. Event-driven architectures are resistant to the impact of intermittent service failures, as events can simply be processed when the service comes back up. This is in contrast to REST API / HTTP communication, where a request will be lost if the server fails to reply.
What is an event stream?
An event stream is a durable and replayable sequence of well-defined domain events. Consumers independently consume and process the events according to their business logic requirements.
A topic in Apache Kafka in an example of an event stream.
What are the benefits of streaming data?
Streaming data enables you to create applications and services that react to events as they happen, in real time. Your business can respond to changing conditions as they occur, altering priorities and making accommodations as necessary. The same streams of operational events can also be used to generate analytics and real-time insights into current operations.
Check out the free courses to learn more about the benefits of thinking in events as well as building streaming data pipelines.
What is event sourcing?
Event sourcing is the capture of all changes to the state of an object, frequently as a series of events stored in an event stream. These events, replayed in the sequence in which they occurred, can be used to reconstruct both the intermediate and final states of the object.
What is an event broker?
An event broker hosts event streams so that other applications can consume from and publish to the streams via a publish/subscribe protocol. Kafka's event brokers are usually set up to be distributed, durable, and resilient to failures, to enable big data scale event-driven communication in real time.
What is stream processing?
Stream processing is an architectural pattern where an application consumes event streams and processes them, optionally emitting its own resultant events to a new set of event streams. The application may be stateless, or it may also build internal state based on the consumed events. Stream processing is usually implemented with a dedicated stream processing technology, such as Kafka Streams or ksqlDB.
What’s the difference between a queue and a topic?
Topics (also known as Event streams) are durable and partitioned, and they can be read by multiple consumers as many times as necessary. They are often used to communicate state and to provide a replayable source of truth for consumers.
Queues are usually unpartitioned and are frequently used as an input buffer for work that needs to be done. Usually, each message in a queue is dequeued, processed, and deleted by a single consumer.
What is distributed computing?
Distributed computing is an architecture in which components of a single system are located on different networked computers. These components communicate and coordinate their actions across the network, either using direct API calls or by sending messages to each other.
What is a microservice?
A microservice is a standalone and independently deployable application, hosted inside of a container or virtual machine. A microservice is purpose-built to serve a well-defined and focused set of business functions, and communicates with other microservices through either event streams or direct request-response APIs. Microservices typically leverage a common compute resource platform to streamline deployments, monitoring, logging, and dynamic scaling.
Read more about microservices and Kafka in this blog series.
What is CQRS?
Command Query Responsibility Segregation (CQRS) is an application architecture that separates commands (modifications to data) from queries (accessing data). This pattern is often used alongside event sourcing in event-driven architectures.
You can learn more about CQRS as part of the free Event Sourcing and Event Storage with Apache Kafka® training course
What is a REST API?
A REST API is an Application Programming Interface (API) that adheres to the constraints of the Representational State Transfer (REST) architectural style. REST API is often used as an umbrella term to describe a client and server communicating via HTTP(S).
You can use the REST Proxy to send and receive messages from Apache Kafka.
What is a data lake?
A data lake is a centralized repository for storing a broad assortment of data sourced from across an organization, for the primary purpose of cross-domain analytical computation. Data may be structured, semi-structured, or unstructured, and is usually used in combination with big data batch processing tools.
Data may be loaded into a data lake in batch, but is commonly done by streaming data into it from Kafka.
What is data mesh?
Data mesh is an approach to solving data communication problems in an organization by treating data with the same amount of rigor as any other product. It is founded on four pillars: data as a product, domain ownership, federated governance, and self-service infrastructure. This strategy is a formal and well-supported approach for providing reliable, trustworthy, and effective access to data across an organization.
What is real-time data analysis?
Real-time data analysis, also known as streaming analytics, refers to the processing of streams of data in real time to extract important business results. This processing is usually implemented with a dedicated stream processing technology, such as Kafka Streams or ksqlDB.
What is an enterprise service bus?
An enterprise service bus (ESB) is a software platform that routes and distributes data among connected applications, without requiring sending applications to know the identity or destination of receiving applications. ESBs differ from Kafka in several key ways. ESBs typically have specialized routing logic, whereas Kafka leaves routing to the application management side. ESBs also do not generally support durable and replayable events, a key feature for services using Kafka.
This blogdiscusses in more detail the similarities and differences between Kafka and ESBs
Apache Projects for GEMS - Global Event Management Solutions
m Apache Data Services#ApachePulsar
FinTech common data models
CDM (Common Domain Model) from ISDA
CMD Fact Sheet
https://www.isda.org/a/z8AEE/ISDA-CDM-Factsheet.pdf
The ISDA CDM is the first industry solution to tackle the lack of standard conventions in how derivatives trade events and processes are represented. Developed in response to regulatory changes, high costs associated with current manual processes and a demand for greater automation across the industry, the ISDA CDM for the first time creates a common blueprint for events that occur throughout the derivatives lifecycle, paving the way for greater automation and efficiency at scale.
“The current derivatives infrastructure is hugely inefficient and costly, and there’s virtually no way to implement scalable automated solutions across the industry.
PURE data modeler with Alloy UI - GS
( see https://medium.com/@vipinsun/pure-alloy-2fd3cd995e90 for inspiration on Data Silos and Pure + Alloy )

Trust Services Extensions to Data Solutions
STS - Smart Trust Services: deliver trusted outcomes
Potential Value Opportunities
Smart Data Services = the right Data Value Services infrastructure
Data Infrastructure Concepts - What good data looks like - datacamp
sdm-smart-data-mgt-datacamp-What Mature Data Infrastructure Looks Like.pdf
What valuable data looks like
https://www.datacamp.com/resources/webinars/data-trends-2021

Smart Data Services Infrastructure
Core Smart Data Management Principles
EEP - Entry > Edit > Post
Data Quality =
- data issue prevention ( goalie )
- data issue cleanup ( janitor )
- data understanding ( whisperer )
- data satisfaction ( therapist )
- data value ( value provider )
Data Operations Management Model for Analytics and AI
DataOps is a collaborative data management discipline that focuses on end-to-end data management and the elimination of data silos.
DataOps offers the following benefits:
• Decreases the cycle time in deploying analytical solutions
• Lowers data defects
• Reduces the time required to resolve data defects
• Minimizes data silos

Reactive Relational DB Connections ( R2DBC ) and services example
r2dbc-dzone.com-Transactional Outbox Patterns - DZone.pdf link
r2dbc-dzone.com-Transactional Outbox Patterns - DZone.pdf file
we need a Transactional Outbox is that a service often needs to publish messages as part of a transaction that updates the database. Both the database update and the sending of the message must happen within a transaction. Otherwise, if the service doesn’t perform these two operations automatically, a failure could leave the system in an inconsistent state.
The GitHub repository with the source code for this article.
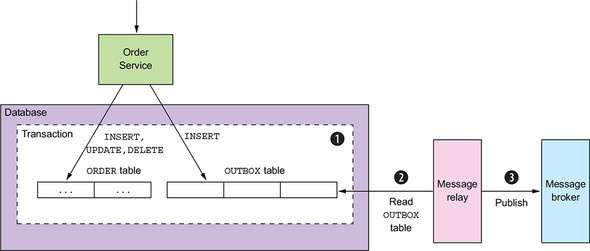
In this article, we will implement it using Reactive Spring and Kotlin with Coroutines. Here is a full list of used dependencies: Kotlin with Coroutines, Spring Boot 3, WebFlux, R2DBC, Postgres, MongoDB, Kafka, Grafana, Prometheus, Zipkin, and Micrometer for observability.
Data Governance Opportunities
see STS - Smart Trust Services: deliver trusted outcomes for advanced concepts
m Data Architecture#Data-Governance-Management-Concepts
m Data Architecture#Data-Governance-Concepts-and-Tools
Data Governance Concepts
Linkedin - RajG on Data Governance concepts
Data governance has its roots in the field of information management and has evolved over time in response to the increasing importance of data in various industries. The concept of data governance emerged as organizations recognized the need to manage their data as a valuable asset and ensure its quality, security, and compliance. The history of data governance can be traced back to several key factors and developments:
- Early #InformationManagement
- IT and Database Management
- Regulatory and #Compliance Requirements
- Emergence of #DataWarehousing and #BusinessIntelligence
- Key US Regulations > Sarbanes-Oxley Act (SOX) and Dodd-Frank Act
- #DataQuality and Trust
- Master Data Management (MDM)
- Digital Transformation
- Emergence of Big Data and #Analytics
- Risk Management
- Complexity and Diversity of Data Sources
- Data Privacy Concerns and #GDPR
- Digital Asset Tokenization and Digital Twins
- Modern Data Governance
- Globalisation and Data Sharing
- Technology Advancement
Over time, these factors led to the formalization of data governance frameworks and practices within organizations. Today, data governance encompasses a range of activities, including defining data ownership, establishing data policies and standards, ensuring data quality, managing data access and security, complying with regulations, and aligning data initiatives with business goals.
Overall, data governance has evolved from a response to challenges posed by data management and regulatory compliance into a strategic discipline that enables organizations to maximize the value of their data while managing risks and ensuring accountability.

a>> Data Governance areas for VSLN
Potential Challenges
Candidate Solutions & Tools
Kafka & Spark - distributed event message network with streaming support
Kafka - distributed messaging service for message brokers and pub sub use cases
Spark - data transformation services library with data streaming support
Apache Events
EventMesh - global event mesh network supporting local and remote events for global workflows
Apache Pulsar - distributed global event mesh
CouchDB - NoSQL Distributed database with built-in API and Logical Query language - open-source
LevelDB - Key Value distributed database - open-source
CockroachDB - Key Value distributed database
https://alternativeto.net/software/cockroachdb/
YugabyteDB - Cloud native DB w Postgres SQL, Query Layer, Storage Layer, Replicas
( and Processes? Trusts? Events? Interfaces? Extensions? Mapping? Directories ? )
https://en.wikipedia.org/wiki/YugabyteDB
YugabyteDB is a high-performance transactional distributed SQL database for cloud-native applications, developed by Yugabyte.[1]
data-Distributed SQL Databases for Dummies-Yugabyte.pdf. link
Architecture
YugabyteDB is a distributed SQL database that aims to be strongly transactionally consistent across failure zones (i.e. ACID compliance].[22][23] Jepsen testing, the de facto industry standard for verifying correctness, has never fully passed, mainly due to race conditions during schema changes.[24] In CAP Theorem terms YugabyteDB is a Consistent/Partition Tolerant (CP) database.[25][26][27]
YugabyteDB has two layers,[28] a storage engine known as DocDB and the Yugabyte Query Layer.[
YugabyteDB has the ability to replicate between database instances.[47][48] The replication can be one-way or bi-directional and is asynchronous
DocDB Storage Services
The storage engine consists of a customized RocksDB[29][30] combined with sharding and load balancing algorithms for the data. In addition, the Raft consensus algorithm controls the replication of data between the nodes.[29][30] There is also a Distributed transaction manager[29][30] and Multiversion concurrency control (MVCC)[29][30] to support distributed transactions.[30]
The engine also exploits a Hybrid Logical Clock[31][29] that combines coarsely-synchronized physical clocks with Lamport clocks to track causal relationships.[32]
The DocDB layer is not directly accessible by users.[29
YQL = Y Query Layer
Yugabyte has a pluggable query layer that abstracts the query layer from the storage layer below.[33] There are currently two APIs that can access the database:[30]
YSQL[34] is a PostgreSQL code-compatible API[35][36] based around v11.2. YSQL is accessed via standard PostgreSQL drivers using native protocols.[37] It exploits the native PostgreSQL code for the query layer[38] and replaces the storage engine with calls to the pluggable query layer. This re-use means that Yugabyte supports many features, including:
- Triggers & Stored Procedures[36]
- PostgreSQL extensions that operate in the query layer[36]
- Native JSONB support[36]
YCQL[39] is a Cassandra-like API based around v3.10 and re-written in C++. YCQL is accessed via standard Cassandra drivers[40] using the native protocol port of 9042. In addition to the 'vanilla' Cassandra components, YCQL is augmented with the following features:
- Transactional consistency - unlike Cassandra, Yugabyte YCQL is transactional.[41]
- JSON data types supported natively[42]
- Tables can have secondary indexes[43]
Currently, data written to either API is not accessible via the other API, however YSQL can access YCQL using the PostgreSQL foreign data wrapper feature.[44]
The security model for accessing the system is inherited from the API, so access controls for YSQL look like PostgreSQL,[45] and YCQL looks like Cassandra access controls.
YugabyteDB versions

https://docs.yugabyte.com/preview/tutorials/
https://docs.yugabyte.com/preview/tutorials/build-and-learn/overview/
https://www.baeldung.com/yugabytedb
https://www.yugabyte.com/blog/tag/tutorial/
Step-by-step guide for Example
sample code block