m Kubernetes
- jim mason
- jimm1
- Jim Mason
Key Points
- Kubernetes is the default container orchestration manager solution
- K8s provides a logical overlay network that allows a single network to span multiple clouds
- Anthos is the control plane for K8s environments on all cloud providers and on-premise servers
References
Key Concepts
Serverless Design on Kubernetes
https://platform9.com/wp-content/uploads/2019/01/Serverless-on-Kubernetes-Gorilla-Guide.pdf
Kubernetes vs Docker concepts
https://containerjournal.com/topics/container-ecosystems/kubernetes-vs-docker-a-primer/
Docker is a standalone software that can be installed on any computer to run containerized applications. Containerization is an approach of running applications on an OS such that the application is isolated from the rest of the system. You create an illusion for your application that it is getting its very own OS instance, although there may be other containers running on same system. Docker is what enables us to run, create and manage containers on a single operating system.
Kubernetes turns it up to 11, so to speak. If you have Docker installed on a bunch of hosts (different operating systems), you can leverage Kubernetes. These nodes, or Docker hosts, can be bare-metal servers or virtual machines. Kubernetes can then allow you to automate container provisioning, networking, load-balancing, security and scaling across all these nodes from a single command line or dashboard. A collection of nodes that is managed by a single Kubernetes instance is referred to as a Kubernetes cluster.
Now, why would you need to have multiple nodes in the first place? The two main motivations behind it are:
- To make the infrastructure more robust: Your application will be online, even if some of the nodes go offline, i.e, High availability.
- To make your application more scalable: If workload increases, simply spawn more containers and/or add more nodes to your Kubernetes cluster.
Docker Containers
There are two ways of looking at Docker. The first approach involves seeing Docker containers as really lightweight virtual machines, while the second approach is to see Docker as a software packaging and delivery platform. This latter approach has proven a lot more helpful to human developers and resulted in widespread adoption of the technology.
you can package your code into a Docker image, run and test it locally using Docker to guaranteed that the containers that were created from that Docker image will behave the same way in production. Limits the need for customized environment configurations.
Note: All the dependencies, such as the version of programming language, standard library, etc., are all contained within that image.
Apt, the package manager, still uses tar under the hood, but users never have to worry about it. Similarly, while using Docker we never have to worry about the package manager, although it is present. Even when developing on top of Node.js technology, for example, developers prefer building their Docker images on top of Node’s official Docker image.
For a microservices-based architecture for your software you should definitely use Docker containers for each microservice.
Docker makes deployment better
Complex multi-container deployments are now standardized thanks to docker-compose. Software engineers have taken containers to their logical extreme by providing complete CI/CD solutions involving building and testing Docker images and managing public or private Docker registries.
Kubernetes - manages containers over networks of nodes
Kubernetes takes containerization technology, as described above, and turns it up to 11. It allows us to run containers across multiple compute nodes (these can be VMs or a bare-metal servers). Once Kubernetes takes control over a cluster of nodes, containers can then spun up or torn down depending upon our need at any given time.
Challenge Kubernetes addresses on a WAN
participating compute nodes are securely connected with one another and so on. Having a set of different nodes instead of a single host brings a whole different set of problems.
Kuerbernetes architecture
node. This is a common term for VMs and/or bare-metal servers that Kubernetes manages
pod is a collection of related Docker containers that need to coexist. For example, your web server may need to be deployed with a redis caching server so you can encapsulate the two of them into a single pod
Master Node, where the heart of Kubernetes is installed. It controls the scheduling of pods across various worker nodes (a.k.a just nodes), where your application actually runs. The master node’s job is to make sure that the desired state of the cluster is maintained.

On Kubernetes Master we have:
- kube-controller-manager: This is responsible for taking into account the current state of the cluster (e.g, X number of running pods) and making decisions to achieve the desired state (e.g, having Y number of active pods instead). It listens on kube-apiserver for information about the state of the cluster
- kube-apiserver: This api server exposes the gears and levers of Kubernetes. It is used by WebUI dashboards and command-line utility like kubeclt. These utilities are in turn used by human operators to interact with the Kubernetes cluster.
- kube-scheduler: This is what decides how events and jobs would be scheduled across the cluster depending on the availability of resources, policy set by operators, etc. It also listens on kube-apiserver for information about the state of the cluster.
- etcd: This is the “storage stack” for the Kubernetes master nodes. It uses key-value pairs and is used to save policies, definitions, secrets, state of the system, etc.
We can have multiple master nodes so that Kubernetes can survive even the failure of a master node.
On a worker node we have:
- kubelet: This relays the information about the health of the node back to the master as well as execute instructions given to it by master node.
- kube-proxy: This network proxy allows various microservices of your application to communicate with each other, within the cluster, as well as expose your application to the rest of the world, if you so desire. Each pod can talk to every other pod via this proxy, in principle.
- Docker: This is the last piece of the puzzle. Each node has a docker engine to manage the containers.
Challeges running Kubernetes
Kubernetes is rapidly evolving, and other organizations are adding their own special sauce to it, such as service mesh, networking plugins, etc. Most of these are open source and therefore are appealing to operator. However, running them in production is not what I would recommend. Keeping up with them requires constant maintenance of your cluster and costs more human hours.
There are cloud-hosted Kubernetes platforms that organizations can use to run their applications. The worldwide availability of hosted data centers can actually help you to get the most out of the distributed nature of Kubernetes. And, of course, you don’t have to worry about maintaining the cluster.
If you want to survive node failures and get high scalability, you shouldn’t run Kubernetes on a single 1-U rack or even in a single data center.
Using a Kubernetes cloud platform, Even small businesses and individual developers now can scale their applications across the entire planet
Networking differences
Kubernetes specifies that each pod should be able to freely communicate with every other pod in the cluster in a given namespace, whereas
Docker has a concept of creating virtual network topologies and you have to specify which networks you want your containers to connect to.
Service Mesh solutions with Kubernetes
Service meshes can connect ( in some cases ) K8s apps and services, VMs, other containers
Which are REALLY open-source AND general-purpose with interfaces?
Istio used to be. Newer ones target specific gateways or controllers
Which Service Mesh is open-source and useful now?
service-mesh-options-201016-searchitoperations.techtarget.com-Service mesh upstarts challenge Istio Linkerd
Kubernetes ebook Concepts - Admin 2020 OReilly
https://drive.google.com/open?id=1iwyi_F1X_ukbE7kZdjZyF1Fx3KDD_tW8
https://tanzu.s3.us-east-2.amazonaws.com/campaigns/pdfs/KUAR_V2_31620.pdf

many reasons why people come to use containers and container APIs likeKubernetes, but we believe they can all be traced back to one of these benefits:
- •Velocity
- •Scaling (of both software and teams)
- •Abstracting your infrastructure
- •Efficiency
Minikube
f you need a local development experience, or you don’t want to pay for cloudresources, you can install a simple single-node cluster using minikube.Alternatively, if you have already installed Docker Desktop, it comes bundled with asingle-machine installation of Kubernetes.While minikube (or Docker Desktop) is a good simulation of a Kubernetes cluster, it’sreally intended for local development, learning, and experimentation. Because it onlyruns in a VM on a single node, it doesn’t provide the reliability of a distributedKubernetes cluster.
Kubectl - K8s client
Kubernetes client is kubectl: a command-line tool for interacting withthe Kubernetes API. kubectl can be used to manage most Kubernetes objects, such asPods, ReplicaSets, and Services. kubectl can also be used to explore and verify theoverall health of the cluster.
Component deployment
many of the components thatmake up the Kubernetes cluster are actually deployed using Kubernetes itself.
Everything contained in Kubernetes is represented by a RESTful resource
K8s Proxy
Kubernetes proxy is responsible for routing network traffic to load-balancedservices in the Kubernetes cluster. To do its job, the proxy must be present on everynode in the cluster. Kubernetes has an API object named DaemonSet, which you willlearn about later in the book, that is used in many clusters to accomplish this. If yourcluster runs the Kubernetes proxy with a DaemonSet, you can see the proxies byrunning:
$ kubectl get daemonSets --namespace=kube-system kube-proxy
NAME DESIRED CURRENT READY NODE-SELECTOR AGE
kube-proxy 4 4 4 <none> 45
K8s DNS
Kubernetes also runs a DNS server, which provides naming and discovery for theservices that are defined in the cluster. This DNS server also runs as a replicated ser‐vice on the cluster.
K8s UI
The UI is run as a single replica, but it isstill managed by a Kubernetes deployment for reliability and upgrades.
Kubectl
client commands works with namespace objects
to change the default namespace more permanently, you can use a con‐text.
a kubectl configuration file, usually located at$HOME/.kube/config.
output command responses as 1 line ( default ), wide - all text or json or yaml
create, update, delete objects
Alternatives to Kubectl
there are plug-ins for several editors that integrate Kubernetes and theeditor environment, including:
- •Visual Studio Code
- •IntelliJ
- •Eclipse
Pod
containerized applications you will often want to colocate multiple applications into a single atomic unit, scheduled onto a singlemachine

Each container within a Pod runs in its own cgroup, but they share a number ofLinux namespaces.Applications running in the same Pod share the same IP address and port space (net‐work namespace), have the same hostname (UTS namespace), and can communicateusing native interprocess communication channels over System V IPC or POSIXmessage queues (IPC namespace).
However, applications in different Pods are iso‐lated from each other; they have different IP addresses, different hostnames, andmore. Containers in different Pods running on the same node might as well be on different servers
Pod overview
Pods represent the atomic unit of work in a Kubernetes cluster. Pods are comprised ofone or more containers working together symbiotically. To create a Pod, you write aPod manifest and submit it to the Kubernetes API server by using the command-linetool or (less frequently) by making HTTP and JSON calls to the server directly.Once you’ve submitted the manifest to the API server, the Kubernetes scheduler findsa machine where the Pod can fit and schedules the Pod to that machine. Once sched‐uled, the kubelet daemon on that machine is responsible for creating the containersthat correspond to the Pod, as well as performing any health checks defined in thePod manifest.
Once a Pod is scheduled to a node, no rescheduling occurs if that node fails. Additionally, to create multiple replicas of the same Pod you have to create and name themmanually. In a later chapter we introduce the ReplicaSet object and show how you canautomate the creation of multiple identical Pods and ensure that they are recreated inthe event of a node machine failure.
What apps should go in the same Pod?
Will these con‐tainers work correctly if they land on different machines?” If the answer is “no,” a Podis the correct grouping for the containers. If the answer is “yes,” multiple Pods isprobably the correct solution. In the example at the beginning of this chapter, the two containers interact via a local filesystem. It would be impossible for them to operatecorrectly if the containers were scheduled on different machines.
Pod Manifest
Pods are described in a Pod manifest. The Pod manifest is just a text-file representa‐tion of the Kubernetes API object
Port Forwarding
Can expose a service to the world or other containersusing load balancers—but oftentimes you simply want to access a specific Pod, even ifit’s not serving traffic on the internet.To achieve this, you can use the port-forwarding support built into the KubernetesAPI and command-line tools.
When you run:
$ kubectl port-forward kuard 8080:8080
a secure tunnel is created from your local machine, through the Kubernetes master, tothe instance of the Pod running on one of the worker nodes.
Execute in a container
Sometimes logs are insufficient, and to truly determine what’s going on you need toexecute commands in the context of the container itself. To do this you can use:$ kubectl exec kuard dateYou can also get an interactive session by adding the -it flags:$ kubectl exec -it kuard ash
Copy files between containers
K8s has configurable keep alive health checks
Liveness probes are defined per container,which means each container inside a Pod is health-checked separately.
Readiness Probes
Liveness determines if an applica‐tion is running properly. Containers that fail liveness checks are restarted. Readinessdescribes when a container is ready to serve user requests. Containers that fail readi‐ness checks are removed from service load balancers.
Resource Management
K8s can be set to manage resources efficiently - win in cloud environments
Persist Data with Volumes outside of a Pod
When a Pod is deleted or a container restarts, any and all data in the container’s file‐system is also deleted. This is often a good thing, since you don’t want to leave aroundcruft that happened to be written by your stateless web application. In other cases,having access to persistent disk storage is an important part of a healthy application.Kubernetes models such persistent storage
Use volumes in a pod
To add a volume to a Pod manifest, there are two new stanzas to add to our configu‐ration. The first is a new spec.volumes section. This array defines all of the volumesthat may be accessed by containers in the Pod manifest. It’s important to note that notall containers are required to mount all volumes defined in the Pod. The second addi‐tion is the volumeMounts array in the container definition. This array defines the vol‐umes that are mounted into a particular container, and the path where each volumeshould be mounted. Note that two different containers in a Pod can mount the samevolume at different mount paths.
To achieve this,Kubernetes supports a wide variety of remote network storage volumes, includingwidely supported protocols like NFS and iSCSI as well as cloud provider networkstorage like Amazon’s Elastic Block Store, Azure’s Files and Disk Storage, as well asGoogle’s Persistent Disk.
Mount host filesystem
Other applications don’t actually need a persistent volume, but they do need someaccess to the underlying host filesystem. For example, they may need access tothe /dev filesystem in order to perform raw block-level access to a device on the sys‐tem. For these cases, Kubernetes supports the hostPath volume, which can mountarbitrary locations on the worker node into the container.
Can mount remote volumes in a Pod
Oftentimes, you want the data a Pod is using to stay with the Pod, even if it is restar‐ted on a different host machine.To achieve this, you can mount a remote network storage volume into your Pod.When using network-based storage, Kubernetes automatically mounts and unmountsthe appropriate storage whenever a Pod using that volume is scheduled onto a partic‐ular machine.
Labels and Annotations
Kubernetes Patterns-2023.pdf file
1. Introduction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
The Path to Cloud Native 1
Distributed Primitives 3
Containers 4
Pods 5
Services 7
Labels 7
Annotations 9
Namespaces 9
Discussion 11
More Information 12
Part I. Foundational Patterns
2. Predictable Demands. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
Problem 15
Solution 16
Runtime Dependencies 16
Resource Profiles 18
Pod Priority 20
Project Resources 22
Capacity Planning 22
iii
Discussion 23
More Information 24
3. Declarative Deployment. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
Problem 25
Solution 25
Rolling Deployment 27
Fixed Deployment 29
Blue-Green Release 30
Canary Release 30
Discussion 31
More Information 33
4. Health Probe. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
Problem 35
Solution 35
Process Health Checks 36
Liveness Probes 36
Readiness Probes 37
Discussion 38
More Information 40
5. Managed Lifecycle. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
Problem 41
Solution 41
SIGTERM Signal 42
SIGKILL Signal 42
Poststart Hook 43
Prestop Hook 44
Other Lifecycle Controls 45
Discussion 46
More Information 46
6. Automated Placement. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
Problem 47
Solution 47
Available Node Resources 48
Container Resource Demands 49
Placement Policies 49
Scheduling Process 50
Node Affinity 51
iv | Table of Contents
Pod Affinity and Antiaffinity 52
Taints and Tolerations 54
Discussion 57
More Information 59
Part II. Behavioral Patterns
7. Batch Job. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
Problem 63
Solution 64
Discussion 67
More Information 68
8. Periodic Job. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
Problem 69
Solution 70
Discussion 71
More Information 72
9. Daemon Service. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
Problem 73
Solution 74
Discussion 76
More Information 77
10. Singleton Service. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
Problem 79
Solution 80
Out-of-Application Locking 80
In-Application Locking 82
Pod Disruption Budget 84
Discussion 85
More Information 86
11. Stateful Service. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
Problem 87
Storage 88
Networking 89
Identity 89
Ordinality 89
Table of Contents | v
Other Requirements 89
Solution 90
Storage 91
Networking 92
Identity 94
Ordinality 94
Other Features 95
Discussion 96
More information 97
12. Service Discovery. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
Problem 99
Solution 100
Internal Service Discovery 101
Manual Service Discovery 104
Service Discovery from Outside the Cluster 107
Application Layer Service Discovery 111
Discussion 113
More Information 115
13. Self Awareness. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
Problem 117
Solution 117
Discussion 121
More Information 121
Part III. Structural Patterns
14. Init Container. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
Problem 125
Solution 126
Discussion 130
More Information 130
15. Sidecar. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
Problem 131
Solution 132
Discussion 134
More Information 134
vi | Table of Contents
16. Adapter. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
Problem 135
Solution 135
Discussion 138
More Information 138
17. Ambassador. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
Problem 139
Solution 139
Discussion 141
More Information 142
Part IV. Conguration Patterns
18. EnvVar Conguration. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
Problem 145
Solution 145
Discussion 148
More Information 149
19. Conguration Resource. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
Problem 151
Solution 151
Discussion 156
More Information 156
20. Immutable Conguration. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
Problem 157
Solution 157
Docker Volumes 158
Kubernetes Init Containers 159
OpenShift Templates 162
Discussion 163
More Information 164
21. Conguration Template. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165
Problem 165
Solution 165
Discussion 170
More Information 171
Table of Contents | vii
Part V. Advanced Patterns
22. Controller. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
Problem 175
Solution 176
Discussion 186
More Information 187
23. Operator. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
Problem 189
Solution 190
Custom Resource Definitions 190
Controller and Operator Classification 193
Operator Development and Deployment 195
Example 197
Discussion 201
More Information 202
24. Elastic Scale. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203
Problem 203
Solution 204
Manual Horizontal Scaling 204
Horizontal Pod Autoscaling 205
Vertical Pod Autoscaling 210
Cluster Autoscaling 213
Scaling Levels 216
Discussion 219
More Information 219
25. Image Builder. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
Problem 221
Solution 222
OpenShift Build 223
Knative Build 230
Discussion 234
More Information 235
Kubernetes Operators-redhat-2023.pdf file
1. Operators Teach Kubernetes New Tricks. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
How Kubernetes Works 1
Example: Stateless Web Server 3
Stateful Is Hard 4
Operators Are Software SREs 4
How Operators Work 5
Kubernetes CRs 6
How Operators Are Made 6
Example: The etcd Operator 6
The Case of the Missing Member 7
Who Are Operators For? 7
Operator Adoption 8
Let’s Get Going! 8
2. Running Operators. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Setting Up an Operator Lab 9
Cluster Version Requirements 9
Authorization Requirements 10
Standard Tools and Techniques 11
Suggested Cluster Configurations 11
Checking Your Cluster Version 12
Running a Simple Operator 13
A Common Starting Point 13
Fetching the etcd Operator Manifests 14
CRs: Custom API Endpoints 14
Who Am I: Defining an Operator Service Account 15
vii
Deploying the etcd Operator 17
Declaring an etcd Cluster 18
Exercising etcd 19
Scaling the etcd Cluster 20
Failure and Automated Recovery 21
Upgrading etcd Clusters 22
Cleaning Up 24
Summary 25
3. Operators at the Kubernetes Interface. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
Standard Scaling: The ReplicaSet Resource 27
Custom Resources 28
CR or ConfigMap? 28
Custom Controllers 29
Operator Scopes 29
Namespace Scope 29
Cluster-Scoped Operators 30
Authorization 30
Service Accounts 30
Roles 31
RoleBindings 31
ClusterRoles and ClusterRoleBindings 31
Summary 32
4. The Operator Framework. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
Operator Framework Origins 33
Operator Maturity Model 34
Operator SDK 34
Installing the Operator SDK Tool 35
Operator Lifecycle Manager 35
Operator Metering 36
Summary 37
5. Sample Application: Visitors Site. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
Application Overview 39
Installation with Manifests 41
Deploying MySQL 41
Backend 43
Frontend 45
Deploying the Manifests 47
Accessing the Visitors Site 47
Cleaning Up 47
viii | Table of Contents
Summary 48
6. Adapter Operators. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
Helm Operator 51
Building the Operator 51
Fleshing Out the CRD 55
Reviewing Operator Permissions 55
Running the Helm Operator 55
Ansible Operator 56
Building the Operator 56
Fleshing Out the CRD 58
Reviewing Operator Permissions 58
Running the Ansible Operator 58
Testing an Operator 59
Summary 60
Resources 60
7. Operators in Go with the Operator SDK. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Initializing the Operator 62
Operator Scope 62
Custom Resource Definitions 64
Defining the Go Types 65
The CRD Manifest 66
Operator Permissions 66
Controller 67
The Reconcile Function 69
Operator Writing Tips 70
Retrieving the Resource 70
Child Resource Creation 71
Child Resource Deletion 74
Child Resource Naming 75
Idempotency 75
Operator Impact 76
Running an Operator Locally 77
Visitors Site Example 78
Summary 79
Resources 79
8. Operator Lifecycle Manager. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
OLM Custom Resources 81
ClusterServiceVersion 82
CatalogSource 82
Table of Contents | ix
Subscription 83
InstallPlan 83
OperatorGroup 83
Installing OLM 84
Using OLM 86
Exploring the Operator 90
Deleting the Operator 91
OLM Bundle Metadata Files 92
Custom Resource Definitions 92
Cluster Service Version File 93
Package Manifest File 93
Writing a Cluster Service Version File 93
Generating a File Skeleton 93
Metadata 95
Owned CRDs 96
Required CRDs 99
Install Modes 100
Versioning and Updating 100
Writing a Package Manifest File 101
Running Locally 102
Prerequisites 102
Building the OLM Bundle 105
Installing the Operator Through OLM 107
Testing the Running Operator 109
Visitors Site Operator Example 109
Summary 109
Resources 109
9. Operator Philosophy. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
SRE for Every Application 111
Toil Not, Neither Spin 112
Automatable: Work Your Computer Would Like 112
Running in Place: Work of No Enduring Value 112
Growing Pains: Work That Expands with the System 113
Operators: Kubernetes Application Reliability Engineering 113
Managing Application State 114
Golden Signals Sent to Software 114
Seven Habits of Highly Successful Operators 116
Summary 117
Kubernetes Container Management Models
DAPR - Distributed Application Runtime pattern
DAPR - Distributed App Portable Runtime
Dapr is a portable, event-driven runtime that makes it easy for any developer to build resilient, stateless and stateful applications that run on the cloud and edge and embraces the diversity of languages and developer frameworks.
- useful open-source package of app services for distributed apps
- uses sidecar pattern to pair app services to another app container
- useful for distributed apps in a Kubernetes runtime
- can help lower dependencies on cloud specific providers like AWS, Azure, etc improving portability, lowering operations costs
Kubernetes Main Doc Set
https://kubernetes.io/docs/home/
_k8s-p1-Kubernetes Documentation _ Kubernetes.pdf file
_k8s-p2-Getting started _ Kubernetes.pdf file
_k8s-p3-Concepts _ Kubernetes.pdf file
_k8s-p4-Tasks _ Kubernetes.pdf file
_k8s-p5-Tutorials _ Kubernetes.pdf file
Learning Kubernetes basics
https://www.redhat.com/en/topics/containers/learning-kubernetes-tutorial
Overview
Containers let developers focus on their apps while operations focus on the infrastructure—container orchestration is the way you manage these deployments across an enterprise.
Kubernetes is an open source container orchestration platform that automates many of the manual processes involved in deploying, managing, and scaling containerized applications.
Kubernetes can help you deliver and manage containerized, legacy, and cloud-native apps at scale, as well as those being refactored into microservices across environments, including private cloud and major public cloud providers like Amazon Web Services (AWS), Google Cloud, IBM Cloud, and Microsoft Azure.
Kubernetes architecture
Kubernetes gives you the platform to schedule and run containers on clusters of physical or virtual machines. Kubernetes architecture divides a cluster into components that work together to maintain the cluster's defined state.
A Kubernetes cluster is a set of node machines for running containerized applications. You can visualize a Kubernetes cluster as two parts: the control plane and the compute machines, or nodes. Each node is its own Linux® environment, and could be either a physical or virtual machine. Each node runs pods, which are made up of containers.
The Kubernetes API (application programming interface) is the front end of the Kubernetes control plane and is how users interact with their Kubernetes cluster. The API server determines if a request is valid and then processes it.
The Kubernetes API is the interface used to manage, create, and configure Kubernetes clusters. It's how the users, external components, and parts of your cluster all communicate with each other.
This quick Kubernetes tutorial shows you how to create a cluster and deploy an application.
Other pieces of a Kubernetes cluster
Nodes:
These machines perform the requested tasks assigned by the control plane.
Pod:
A set of 1 or more containers deployed to a single node. A pod is the smallest and simplest Kubernetes object.
Service:
A way to expose an application running on a set of pods as a network service. This decouples work definitions from the pods.
Kubectl:
The command line interface where you can manage your Kubernetes cluster. Learn basic kubectl and Helm commands for beginners.
kubelet:
A tiny application located within each node that communicates with the control plane. The kublet makes sure containers are running in a pod.
If you’re ready to get started with Kubernetes for yourself, Minikube is an open source tool that allows you to set up a local Kubernetes cluster so you can try out Kubernetes from a laptop.
How Kubernetes works
Kubernetes works based on defined state and actual state. Kubernetes objects represent the state of a cluster and tell Kubernetes what you want the workload to look like.
Once an object has been created and defined, Kubernetes works to make sure that the object always exists.
Controllers actively manage the state of Kubernetes objects and work to make changes that move the cluster from its current state to the desired state.
Developers or sysadmins specify the defined state using the YAML or JSON files they submit to the Kubernetes API. Kubernetes uses a controller to analyze the difference between the new defined state and the actual state in the cluster.
The desired state of a Kubernetes cluster defines which applications or other workloads should be running, along with which container images they use, which resources should be made available to them, and other configuration details.
Configuration data and information about the state of the cluster lives in etcd, a key-value store database. Fault-tolerant and distributed, etcd is designed to be the ultimate source of truth about your cluster.
Kubernetes will automatically manage your cluster to match the desired state. Controllers usually do this by sending messages to the API server that result in the needed changes, and some Kubernetes resources have built-in controllers.
As an example of how Kubernetes manages desired state, suppose you deploy an application with a desired state of "3," meaning 3 replicas of the application should be running.
If 1 of those containers crashes, the Kubernetes replica set will see that only 2 replicas are running, so it will add 1 more to satisfy the desired state.
Replica sets are a type of controller that ensures a specified number of pods are running at any given time.
Kubernetes deployments are the preferred method for managing replica sets and provide declarative updates to pods so that you don’t have to manually manage them yourself.
You can also use autoscaling in Kubernetes to manage the scale of your services based on user demand. When specifying the desired state of an application or service, you can also tell the controller to make additional pods available if demand increases.
For example, during a busy time period your application's desired state could increase to 10, instead of the usual 3 replicas
Kubernetes deployments
A Kubernetes deployment is a resource object in Kubernetes that provides declarative updates to applications.
A deployment allows you to describe an application’s life cycle, such as which images to use for the app, the number of pods there should be, and the way in which they should be updated.
The process of manually updating containerized applications can be time consuming and tedious. A Kubernetes deployment makes this process automated and repeatable.
Deployments are entirely managed by the Kubernetes backend, and the whole update process is performed on the server side without client interaction.
The Kubernetes deployment object lets you:
- Deploy a replica set or pod
- Update pods and replica sets
- Rollback to previous deployment versions
- Scale a deployment
- Pause or continue a deployment
Kubernetes patterns
Kubernetes patterns are design patterns for container-based applications and services.
Kubernetes can help developers write cloud-native apps, and it provides a library of application programming interfaces (APIs) and tools for building applications.
However, Kubernetes doesn’t provide developers and architects with guidelines for how to use these pieces to build a complete system that meets business needs and goals.
Patterns are a way to reuse architectures. Instead of completely creating the architecture yourself, you can use existing Kubernetes patterns, which also ensure that things will work the way they’re supposed to.
Patterns are the tools needed by a Kubernetes developer, and they will show you how to build your system.
Kubernetes operators
A Kubernetes operator is a method of packaging, deploying, and managing a Kubernetes application. A Kubernetes application is both deployed on Kubernetes and managed using the Kubernetes API and kubectl tooling.
A Kubernetes operator is an application-specific controller that extends the functionality of the Kubernetes API to create, configure, and manage instances of complex applications on behalf of a Kubernetes user.
Learn how to build a Kubernetes operator in 10 minutes using the Operator SDK.
It builds upon the basic Kubernetes resource and controller concepts, but includes domain or application-specific knowledge to automate the entire life cycle of the software it manages.
If you want more detail on Kubernetes operators and why they’re important here’s how to explain them in plain English.
Operators allow you to write code to automate a task, beyond the basic automation features provided in Kubernetes. For teams following a DevOps or site reliability engineering (SRE) approach, operators were developed to put SRE practices into Kubernetes.
Learn more about how Kubernetes operators work, including real examples, and how to build them with the Operator Framework and software development kit.
Training & administration
Deploying Containerized Applications Tech Overview
This on-demand series of short lectures and in-depth demonstrations introduces you to Linux containers and container orchestration technology using Docker, Kubernetes, and Red Hat® OpenShift® Container Platform.
Red Hat OpenShift Administration
This course teaches you how to install and administer the Red Hat OpenShift Container Platform. This hands-on, lab-based course shows you how to install, configure, and manage OpenShift clusters and deploy sample applications to further understand how developers will use the platform.
Introduction to OpenShift Applications
This course is a developer-focused introduction to Red Hat OpenShift application building, deployment, scaling, and troubleshooting. As OpenShift and Kubernetes continue to become widely adopted, developers are increasingly required to understand how to develop, build, and deploy applications with a containerized application platform
Kubernetes for the enterprise
Red Hat OpenShift is Kubernetes for the enterprise. It includes all of the extra pieces of technology that make Kubernetes powerful and viable for the enterprise, including registry, networking, telemetry, security, automation, and services.
With Red Hat OpenShift, developers can make new containerized apps, host them, and deploy them in the cloud with the scalability, control, and orchestration that can turn a good idea into new business quickly and easily.
You can try using Red Hat OpenShift to automate your container operations with a free 60-day evaluation.
Learn Kubernetes using Red Hat Developer Sandbox for OpenShift
Red Hat Developer Sandbox for OpenShift ("Sandbox") is a great platform for learning and experimenting with Red Hat OpenShift. Because OpenShift is built on Kubernetes, the Sandbox is also a great platform for learning and experimenting with Kubernetes.
This activity takes you through the creation of an application using plain Kubernetes instead of OpenShift.
Anthos is becoming the default controller for K8s on all platforms including on-premise servers
Google Cloud Platform has the industry’s best Kubernetes platform in the form of Google Kubernetes Engine (GKE). It’s fast, reliable, secure, and more importantly, backed by Google’s experience of dealing with millions of containers running its flagship products like Search and YouTube.
Google proposed a two-fold approach of containerizing the workloads and then running them in the hybrid cloud powered by Kubernetes.
From launching new Kubernetes clusters to patching them and upgrading them, the entire lifecycle of the clusters is managed by Anthos.
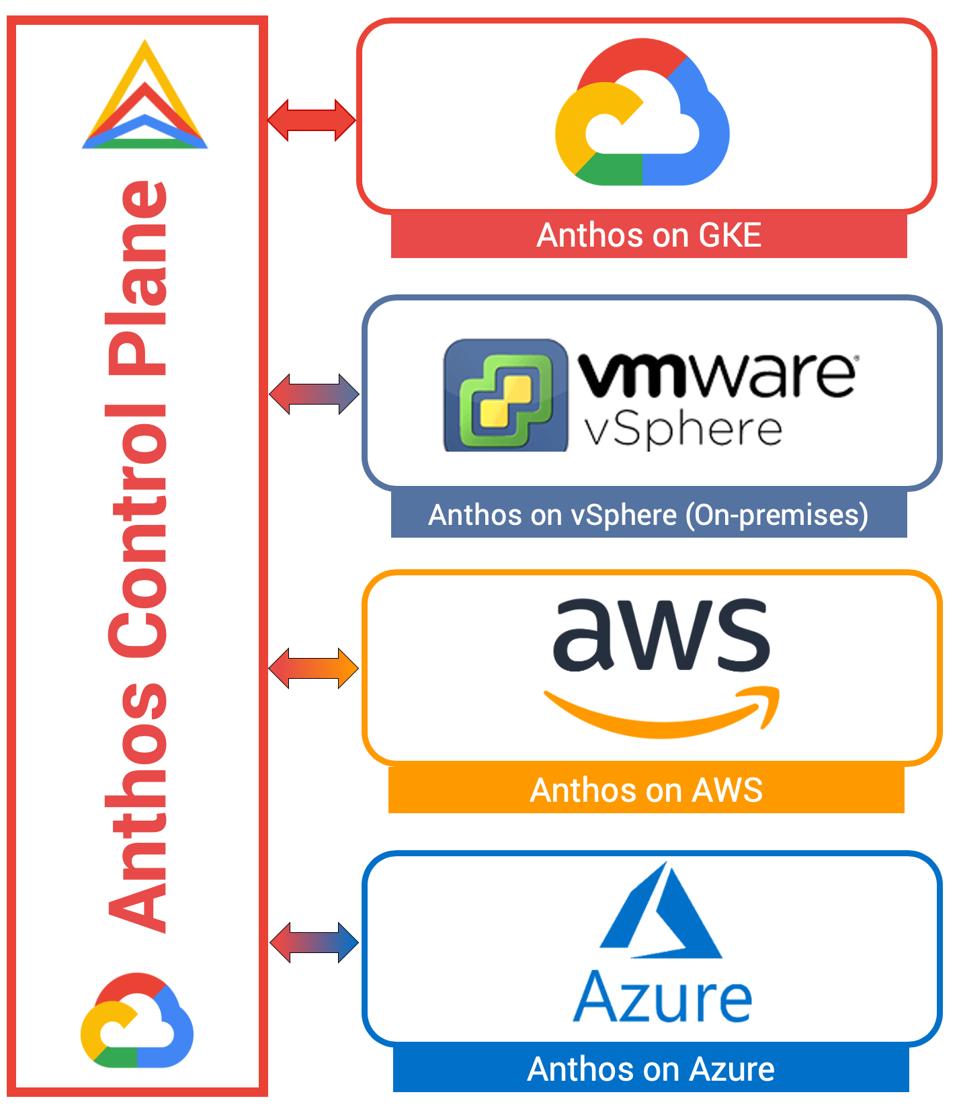
Anthos in Data Center uses VMWare VSphere platform to run
For Anthos to spin up a GKE cluster in an enterprise datacenter, it needs VMware vSphere 6.5 or above. Anthos depends on vSphere and vCenter to manage the compute infrastructure underneath Kubernetes. For networking, Anthos relies on native vSphere networking and a choice of F5 BIG-IP or a bundled software load balancer based on the Seesaw project. vSphere Storage is used as the persistent storage layer for Kubernetes workloads.
In future releases of Anthos, Google is expected to move away from VMware’s dependency, allowing its customers to run Anthos with no third-party hypervisor.
Anthos on-prem model

Anthos on AWS
The architecture of Anthos on AWS is fascinating for an infrastructure architect familiar with both the cloud platforms. Google mapped the key building blocks of GCP powering GKE to the services of AWS.
If GKE on GCP uses Compute Engine for the VMs, it is Amazon EC2 on AWS. The GCE Persistent Disks are mapped to Amazon Elastic Block Storage (EBS). The network topology is based on AWS VPC which makes it possible to run the management cluster in a private or public VPC subnet. An AWS Elastic Load Balancer (ELB) or Application Load Balancer (ALB) makes it up for the Google Cloud Load Balancer.

Anthos on AWS generates a set of Terraform templates to automate the deployment of the management cluster. Once the management cluster is in place, customers can use the familiar kubectl CLI to launch one or more user clusters. The worker nodes of a user cluster can span multiple availability zones within the same AWS region for high availability.
Anthos can manage non-K8s clusters through service mesh
Anthos control plane, the platform also supports onboarding non-GKE clusters such as Amazon EKS, Azure AKS, and even Red Hat OpenShift. Though Anthos won’t manage the clusters themselves in those environments, customers can define and manage policies through the central Anthos Configuration Management, and create and manage a service mesh through Anthos Service Mesh.
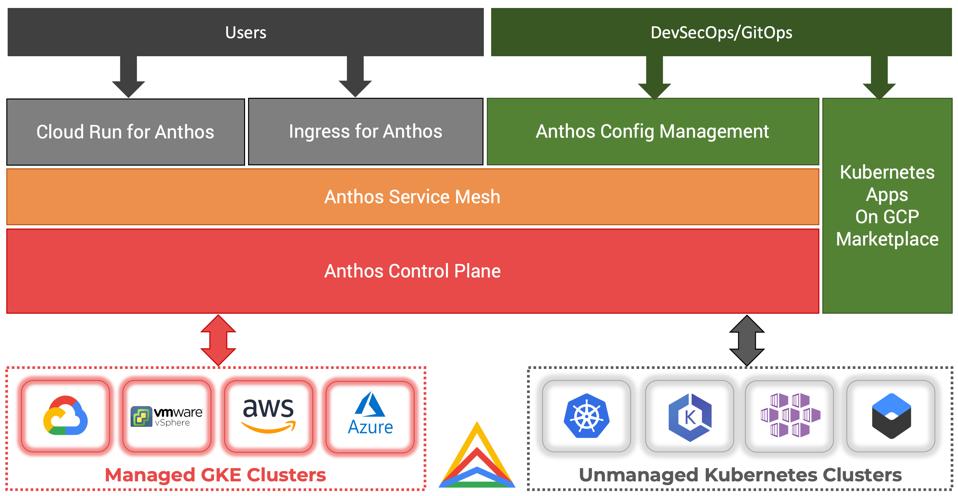
Anthos will have many native Google Services on all platforms
Google already brought some of the managed services such as Cloud Run, Dataflow based on Apache Beam and AI Pipelines powered by Kubeflow Pipelines to Anthos. Eventually, it will make other managed services available natively in Anthos. This not only reduces the latency but also encourages customers to invest in managed services of GCP even while running in other cloud platforms.
OpenShift - Open source platform based on Kubernetes, containers
service mesh support?
what service interfaces and adapters exist?
how are multiple networks composed into a logical platform for operations, management?
what identity models and interfaces are supported?
what open source monitoring solutions are supported? ( Prometheus, Nagios ? )
Key differences between OpenShift and Kubernetes
https://cloud.netapp.com/blog/cvo-blg-kubernetes-vs-openshift-10-key-differences
Kafka on Kubernetes - IBM session
kafka
compare kafka, amq
- events, topics, channels
- kafka - cluster of 3 brokers
- grpc??
- topics can be partitioned ( by time or ?) by broker 4 scale
- supports replica for topics as needed
q> - selects a leader ( temporary or rotation? )
on failure, new leader assigned
- producers publish to kafka
- consumers read from kafka on event notifications
kafka on k8s
- kafka pods for brokers
kubectl get pods -w
- k8s health checks
alive - is container running? set threshold for actions
is port open and responding to kafka calls - simple end pt script
ready - ready to receive requests ,
if failed, remove from service list
check in-sync replicas - do replicas respond?
min.insync.replicas - min for partition to be available in k8s
if not, new events not accepted from producers
should set kafka status to not ready until min.insync hit
manage kafka pods
k8s stateful sets in kafka for persistence
captures transactions if services lost for recovery
s.set has sticky id for each pod
persistent volumes for each pod claim ( address etc ) to bind
pod can now write
restarted pod can use same p.volume claim on restart
if no p.volume, errors can be no borkerid exception etc
kafka starting - writes meta.properties file for each broker
matches a p.volume to a broker on restart
p.volume claims are persistent - need script to clean up if wanted
deploying kafka
if k8s node goes down, ensure kafka brokers are on different nodes
set k8s affiinity rules and anti-affinity rules to separate pods
spread out zookeepers as workers running next to kafka nodes
kubectl get nodes >> shows nodes
accessing kafka on k8s
headless service for stateful sets in k8s
set cluster ip = none
selector app: kafka to access any kafka nodes
kubectl get service ...
allows direct access to a specific node ( vs default routing )
useful for listeners
listeners
address the socket server listens on
advertised listeners
advertised hostname, ports to listeners and consumers
used in k8s and docker
cloudctl es broker-config n | grep listeners
shows all pods listening on same external address
> need validation script to validate advertised listeners are good
automation
helm install
helm upgrade
custom k8s resources
kubectl get kafka
kubectl get zookeeper
k8s operators
kubectl scale kafka ???
Docker Compose files can be translated to Kubernetes resources using Kompose
https://kubernetes.io/docs/tasks/configure-pod-container/translate-compose-kubernetes/
What’s Kompose? It’s a conversion tool for all things compose (namely Docker Compose) to container orchestrators (Kubernetes or OpenShift).
More information can be found on the Kompose website at http://kompose.io.
- Before you begin
- Install Kompose
- Use Kompose
- User Guide
kompose convertkompose upkompose down- Build and Push Docker Images
- Alternative Conversions
- Labels
- Restart
- Docker Compose Versions
MiniKube - Local Kubernetes Testing
https://github.com/kubernetes/minikube
Mini Kube - setup local K8s cluster for testing - all platforms
minikube implements a local Kubernetes cluster on macOS, Linux, and Windows. minikube's primary goals are to be the best tool for local Kubernetes application development and to support all Kubernetes features that fit.
Features
minikube runs the latest stable release of Kubernetes, with support for standard Kubernetes features like:
- LoadBalancer - using
minikube tunnel - Multi-cluster - using
minikube start -p <name> - NodePorts - using
minikube service - Persistent Volumes
- Ingress
- Dashboard -
minikube dashboard - Container runtimes -
start --container-runtime - Configure apiserver and kubelet options via command-line flags
As well as developer-friendly features:
- Addons - a marketplace for developers to share configurations for running services on minikube
- NVIDIA GPU support - for machine learning
- Filesystem mounts
For more information, see the official minikube website
Installation
See the Getting Started Guide
📣 Please fill out our fast 5-question survey so that we can learn how & why you use minikube, and what improvements we should make. Thank you! 👯
Documentation
See https://minikube.sigs.k8s.io/docs/
More Examples
See minikube in action here
Potential Value Opportunities
Potential Challenges
Candidate Solutions
Managing Secrets in Kubernetes - 2024
Why are Kubernetes secrets important?
How does Kubernetes leverage secrets?
Best practices for managing secrets in Kubernetes
In a distributed computing environment it is important that containerized applications remain ephemeral and do not share their resources with other pods. This is especially true in relation to PKI and other external confidential resources that pods need to access. For this reason, applications need a way to query their authentication methods externally without being held in the application itself.
Kubernetes offers a solution to this that follows the path of least privilege. Kubernetes Secrets act as separate objects that can be queried by the application Pod to provide credentials to the application for access to external resources. Secrets can only be accessed by Pods if they are explicitly part of a mounted volume or at the time when the Kubelet is pulling the image to be used for the Pod.
How does Kubernetes leverage secrets?
The Kubernetes API provides various built-in secret types for a variety of use cases found in the wild. When you create a secret, you can declare its type by leveraging the `type` field of the Secret resource, or an equivalent `kubectl` command line flag. The Secret type is used for programmatic interaction with the Secret data.
Fabric deployment on Kubernetes v1.4 - Chris Gabriel
https://github.com/denali49/fabric-ca-k8s
Notes
MicroK8s from Canoncial
Zero-ops K8 nodes for developers
A single package of k8s for 42 flavours of Linux. Made for developers, and great for edge, IoT and appliances.
The smallest, fastest, fully-conformant Kubernetes that tracks upstream releases and makes clustering trivial. MicroK8s is great for offline development, prototyping, and testing. Use it on a VM as a small, cheap, reliable k8s for CI/CD. The best kubernetes for appliances. Develop IoT apps for k8s and deploy them to MicroK8s on your Linux boxes.
- Conformant
- Istio
- Storage
- Clustering BETA
- Registry
- GPGPU bindings
- Dashboard
- Metrics
- Automatic Updates
- Ingress
- DNS
- Linkerd, Fluentd
- Knative
- Kubeflow
- Ja
Fast install
Get a full Kubernetes system running in under 60 seconds.
Secure
Runs safely on your laptop with state of the art isolation.
Upstream
CNCF binaries delivered to your laptop, with updates and upgrades.
Complete
Includes a docker registry so you can make containers, push them, and deploy them all on your laptop.
Featureful
Cool things you probably want to try on a small, standard K8s are all built-in. Just enable them and go.
Updates
Get the daily build if you want it, or betas and milestones, or just stable point releases.
Upgrades
When a new major version comes out, upgrade with a single command (or automatically).
GPGPU Passthrough
Give MicroK8s a GPGPU and your docker containers can get all nice and CUDA.
sudo snap install microk8s --classic
Running snap info microK8s shows the current published k8s versions. It is possible to select a specific version like 1.6 and get only stable or RC updates to that version. By default, you will get the current major version with upgrades when new major versions are published.
Step-by-step guide for Example
sample code block