m Apache Kafka
- jim mason
- jimm1
Key Points
- Data pipelines connect, transform data sources to data targets in batches or event streams
- Kafka directory services definitions stored as metadata with optional data schemas
- brokers connect clients, producers to topics ( queues ) using Kafka directory services
- handles many types of producers, consumers, topics (queues), replication, partitions
- messages can be consumed by multiple clients, sent by multiple producers, serialized, synch or asynch
- clients must poll a queue - there is DIRECT NO PUSH options ( eg web sockets model etc )
- producers push message to topics queues
- queues can be persistent
- REST proxy available to interface to queues
- Future option to replace Zookeeper directory with distributed metadata services ( DMS )
References
Key Concepts
Kafka
Apache Kafka vs. Enterprise Service Bus (ESB) – Friends, Enemies or Frenemies? article
Typically, an enterprise service bus (ESB) or other integration solutions like extract-transform-load (ETL) tools have been used to try to decouple systems. However, the sheer number of connectors, as well as the requirement that applications publish and subscribe to the data at the same time, mean that systems are always intertwined. As a result, development projects have lots of dependencies on other systems and nothing can be truly decoupled.
This blog post shows why so many enterprises leverage the ecosystem of Apache Kafka® for successful integration of different legacy and modern applications, and how this differs but also complements existing integration solutions like ESB or ETL tools.
The need for integration is a never-ending story.
This includes many different factors:
- Technologies (standards like SOAP, REST, JMS, MQTT, data formats like JSON, XML, Apache Avro or Protocol Buffers, open frameworks like Nginx or Kubernetes, and proprietary interfaces like EDIFACT or SAP BAPI)
- Programming languages and platforms like Cobol, Java, .NET, Go or Python
- Application architectures like Monolith, Client Server, Service-oriented Architecture (SOA), Microservices or Serverless
- Communication paradigms like batch processing, (near) real-time, request-response, fire-and-forget, publish-subscribe, continuous queries, and rewinding
Many enterprise architectures are a bit messy—something like this:
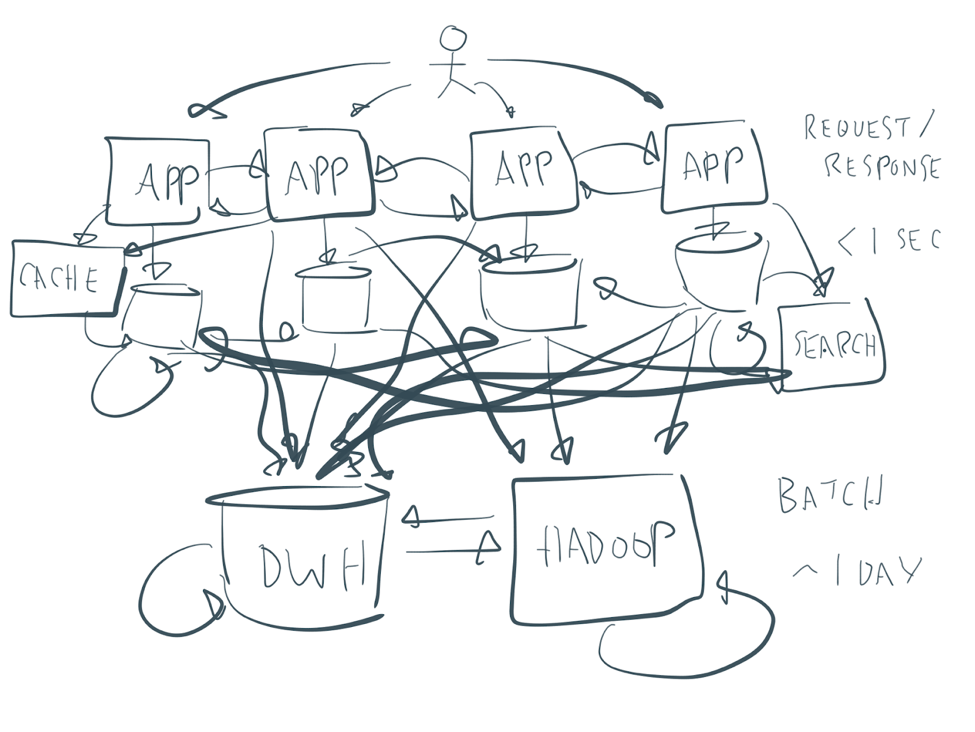
You always see the same picture as a solution to move away from your spaghetti architecture to a central integral box in the middle, like this:
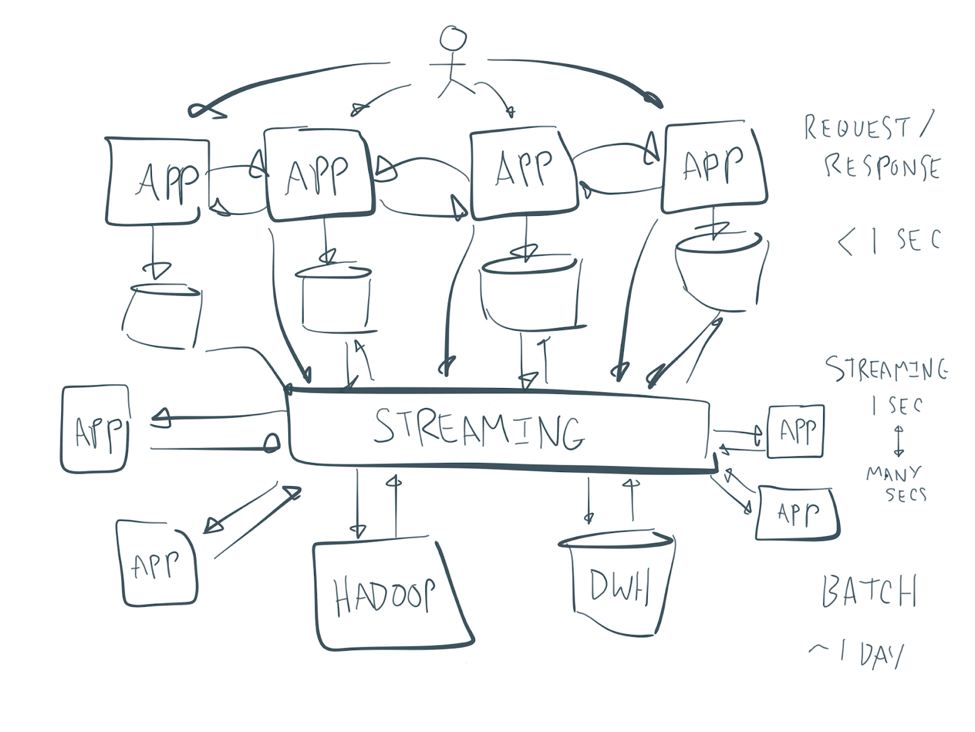
Event-driven processing and streaming as a key concept in the enterprise architecture
An event streaming platform (you can also enter another buzzword here) leverages events as a core principle. You think in data flows of events and process the data while it is in motion.
Many concepts, such as event sourcing, or design patterns such as Enterprise Integration Patterns (EIPs), are based on event-driven architecture. The following are some characteristics of a streaming platform:
- Event-based data flows as a foundation for (near) real-time and batch processing. In the past, everything was built on data stores (data at rest), making it impossible to build flexible, agile services to act on data while it is relevant.
- Scalable central nervous system for events between any number of sources and sinks. Central does not mean one or two big boxes in the middle but a scalable, distributed infrastructure, built by design for zero downtime, handling the failure of nodes and networks and rolling upgrades. Different versions of infrastructure (like Kafka) and applications (business services) can be deployed and managed in an agile, dynamic way.
- Integrability of any kind of applications and systems. Technology does not matter. Connect anything: programming language, APIs like REST, open standards, proprietary tools, and legacy applications. Speed does not matter. Read once. Read several times. Read again from the beginning (e.g., add a new application, and train different machine learning models with the same data).
- Distributed storage for decoupling applications. Don’t try to build your own streaming platform using your favorite traditional messaging system and in-memory cache/data grid. There is a lot of complexity behind this and a streaming platform simply has it built-in. This allows you to store the state of a microservice instead of requiring a separate database, for example.
- Stateless service and stateful business processes. Business processes typically are stateful processes. They often need to be implemented with events and state changes, not with remote procedure calls and request-response style. Patterns like event sourcing and CQRS help implement this in an event-driven streaming architecture.
Benefits of a streaming platform in the enterprise architecture
A streaming platform establishes huge benefits for your enterprise architecture:
- Large and elastic scalability regarding nodes, volume, and throughput—all on commodity hardware, in any public cloud environments, or via hybrid deployments.
- Flexibility of architecture. Build small services, big services, sometimes still even monoliths.
- Event-driven microservices. Asynchronously connected microservices model complex business flows and move data to where it is needed.
- Openness without commitment to a unique technology or data format. The next new standard, protocol, programming language, or framework is coming for sure. The central streaming platform is open even if some sources or sinks use a proprietary data format or technology.
- Independent and decoupled business services, managed as products, with their own lifecycle regarding development, testing, deployment, and monitoring. Loose coupling allows for independent speed of processing between different producers and consumers, on/offline modes, and handling backpressure.
- Multi-tenancy to ensure that only the right user can create, write to, and read from different data streams in a single cluster.
- Industrialized deployment using containers, DevOps, etc., deployed where needed, whether on-premise, in the public cloud, or in a hybrid environment.
Use cases for a streaming platform
Here are some generic scenarios for how you can leverage a streaming platform with the characteristics discussed above:
- Event-driven processing of big data sets (e.g., logs, IoT sensors, social feeds)
- Mission-critical, real-time applications (e.g., payments, fraud detection, customer experience)
- Decoupled integration between different legacy applications and modern applications
- Microservices architecture
- Analytics (e.g., for data science, machine learning)
Producers and consumers of different applications are decoupled. They scale independently at their speed and requirements. You can add new applications over time, both on the producer and consumer side. Often, one event is required to be consumed by many independent applications to complete the business process. For example, a hotel room reservation needs immediate payment fraud detection in real-time, the ability to process the booking through all backend systems in near real-time, and overnight batch analytics to improve customer 360, aftersales, hotel logistics, and other business processes.
Kafka 101 Tutorials
https://kafka-tutorials.confluent.io/?_ga=2.255305614.740418466.1611961981-2041899468.1610139243
Kafka 101 Basic Concepts
- Console producer and consumer basics
- Console producer and consumer basics with Confluent Cloud
- Console consumer with primitive keys and values
- Idempotent producer for message ordering and no duplication
- Avro console producer and consumer
- Change the number of partitions and replicas of a Kafka topic
- Console consumer reads from a specific offset and partition
- Produce and consume messages with clients in multiple languages
- Build your first Kafka producer application
- Using Callbacks to handle Kafka producer responses
- Build your first Kafka consumer application
- Count the number of messages in a Kafka topic
Kafka 101 Apply Functions
- Masking data
- Working with nested JSON
- Working with heterogenous JSON
- Concatenation
- Convert a stream's serialization format
- Scheduling operations in Kafka Streams
- Transform a stream of events
- Flatten deeply nested events
- Filter a stream of events
- Rekey a stream with a value
- Rekey a stream with a function
- Split a stream of events into substreams
- Merge many streams into one stream
- Find distinct events
- Apply a custom, user-defined function
- Handle deserialization errors
- Choose the output topic dynamically
- Name stateful operations
- Convert a KStream to a KTable
- Calculate the difference between two columns
Kafka 101 Aggregation Functions
- Count a stream of events
- Sum a stream of events
- Find the min/max in a stream of events
- Calculate a running average
- Cogroup multiple streams of aggregates
Apache Kafka and ksqlDB in Action: Let’s Build a Streaming Data Pipeline!
Have you ever thought that you needed to be a programmer to do stream processing and build streaming data pipelines? Think again! Apache Kafka is a distributed, scalable, and fault-tolerant streaming platform, providing low-latency pub-sub messaging coupled with native storage and stream processing capabilities. Integrating Kafka with RDBMS, NoSQL, and object stores is simple with Kafka Connect, which is part of Apache Kafka. ksqlDB is the source-available SQL streaming engine for Apache Kafka and makes it possible to build stream processing applications at scale, written using a familiar SQL interface.
In this talk, we’ll explain the architectural reasoning for Apache Kafka and the benefits of real-time integration, and we’ll build a streaming data pipeline using nothing but our bare hands, Kafka Connect, and ksqlDB.
Gasp as we filter events in real-time! Be amazed at how we can enrich streams of data with data from RDBMS! Be astonished at the power of streaming aggregates for anomaly detection!
Kafka KIPS
KIP-500 RFC - replace Zookeeper for Kafka MDM
Currently, Kafka uses ZooKeeper to store its metadata about partitions and brokers, and to elect a broker to be the Kafka Controller. We would like to remove this dependency on ZooKeeper. This will enable us to manage metadata in a more scalable and robust way, enabling support for more partitions. It will also simplify the deployment and configuration of Kafka.
brokers should simply consume metadata events from the event log.
- Status
- Motivation
- Architecture
- Compatibility, Deprecation, and Migration Plan
- Rejected Alternatives
- Follow-on Work
- References
Metadata as an event log
We often talk about the benefits of managing state as a stream of events. A single number, the offset, describes a consumer's position in the stream. Multiple consumers can quickly catch up to the latest state simply by replaying all the events newer than their current offset. The log establishes a clear ordering between events, and ensures that the consumers always move along a single timeline.
However, although our users enjoy these benefits, Kafka itself has been left out. We treat changes to metadata as isolated changes with no relationship to each other. When the controller pushes out state change notifications (such as LeaderAndIsrRequest) to other brokers in the cluster, it is possible for brokers to get some of the changes, but not all. Although the controller retries several times, it eventually give up. This can leave brokers in a divergent state.

Currently, a Kafka cluster contains several broker nodes, and an external quorum of ZooKeeper nodes
Controller Log
The controller nodes comprise a Raft quorum which manages the metadata log. This log contains information about each change to the cluster metadata. Everything that is currently stored in ZooKeeper, such as topics, partitions, ISRs, configurations, and so on, will be stored in this log.
Broker Metadata Management
Instead of the controller pushing out updates to the other brokers, those brokers will fetch updates from the active controller via the new MetadataFetch API.
A MetadataFetch is similar to a fetch request. Just like with a fetch request, the broker will track the offset of the last updates it fetched, and only request newer updates from the active controller.
The broker will persist the metadata it fetched to disk. This will allow the broker to start up very quickly, even if there are hundreds of thousands or even millions of partitions. (Note that since this persistence is an optimization, we can leave it out of the first version, if it makes development easier.)
Most of the time, the broker should only need to fetch the deltas, not the full state. However, if the broker is too far behind the active controller, or if the broker has no cached metadata at all, the controller will send a full metadata image rather than a series of deltas.

The broker will periodically ask for metadata updates from the active controller. This request will double as a heartbeat, letting the controller know that the broker is alive.
Broker States
cluster membership is integrated with metadata updates. Brokers cannot continue to be members of the cluster if they cannot receive metadata updates. While it is still possible for a broker to be partitioned from a particular client, the broker will be removed from the cluster if it is partitioned from the controller.
Broker States

Offline
When the broker process is in the Offline state, it is either not running at all, or in the process of performing single-node tasks needed to starting up such as initializing the JVM or performing log recovery.
Fenced
When the broker is in the Fenced state, it will not respond to RPCs from clients. The broker will be in the fenced state when starting up and attempting to fetch the newest metadata. It will re-enter the fenced state if it can't contact the active controller. Fenced brokers should be omitted from the metadata sent to clients.
Online
When a broker is online, it is ready to respond to requests from clients.
Stopping
Brokers enter the stopping state when they receive a SIGINT. This indicates that the system administrator wants to shut down the broker.
When a broker is stopping, it is still running, but we are trying to migrate the partition leaders off of the broker.
Java Spring Boot app using Kafka as message broker tutorial
https://developer.okta.com/blog/2019/11/19/java-kafka
kafka-java-tutorial-developer.okta.com-Kafka with Java Build a Secure Scalable Messaging App.pdf
Kafka Microservices Integration with JHipster, OICD article
https://developer.okta.com/blog/2022/09/15/kafka-microservices
One of the traditional approaches for communicating between microservices is through their REST APIs. However, as your system evolves and the number of microservices grows, communication becomes more complex, and the architecture might start resembling our old friend the spaghetti anti-pattern, with services depending on each other or tightly coupled, slowing down development teams. This model can exhibit low latency but only works if services are made highly available.
To overcome this design disadvantage, new architectures aim to decouple senders from receivers, with asynchronous messaging. In a Kafka-centric architecture, low latency is preserved, with additional advantages like message balancing among available consumers and centralized management.
When dealing with a brownfield platform (legacy), a recommended way to decouple a monolith and ready it for a move to microservices is to implement asynchronous messaging.
In this tutorial you will learn how to:
- Create a microservices architecture with JHipster
- Enable Kafka integration for communicating microservices
- Set up Okta as the authentication provider
Potential Value Opportunities
Automating K8S Kafka recoveries with Supertubes
Using Supertubes, Kafka and tools to automate POD recoveries
Potential Challenges
Candidate Solutions
Step-by-step guide for Example
sample code block